
Microsoft FabricのData Warehouseとは?
Microsoft Fabric の Data Warehouse は、企業のデータを保存・管理し、SQLを使って大規模なデータ分析を行うことができるクラウドサービスです。Microsoft Fabric プラットフォームに統合されたデータウェアハウスサービスとして、従来のデータウェアハウスの利点をそのままに、クラウドネイティブな環境で提供されています。
このサービスを利用することで、企業は様々なデータソースから収集したデータを一元管理し、高度な分析やレポート作成を行うことができます。
また、Microsoft Fabric の他のサービスとシームレスに連携することで、データの収集から可視化までをワンストップで実現できます。
Microsoft Fabricとは
では、そもそもMicrosoft Fabricとは何でしょうか。
Microsoft Fabric は、データの収集、整理、分析をすべて一つのプラットフォームで行える統合データ分析基盤 です。
Microsoft Fabric には、データの管理や分析を支える複数のサービスが統合されています。代表的なものは次のとおりです。
- Lakehouse:データレイクとデータウェアハウスの機能を組み合わせ、大量のデータを効率的に管理・分析できるサービス。
- Data Warehouse:企業のデータを保存・管理し、SQL を使って分析できる大規模データ分析基盤。
- Data Factory:データの取り込みや変換を自動化する ETL(Extract, Transform, Load)ツール。
- Real-Time Analytics:リアルタイムのデータ処理と分析を行い、即時の意思決定をサポート。
- Power BI:データの可視化とレポート作成を行い、誰でも簡単にデータを活用できるツール。
- OneLake:Microsoft Fabric のデータを一元管理するデータレイク。さまざまなデータを統合し、各サービスからシームレスにアクセス可能。

Microsoft Fabricイメージ(参考:Microsoft)
Microsoft FabricにおけるData Warehouseの位置づけ
では、Microsoft Fabric の中で Data Warehouseはどのような役割を果たしているのでしょうか。
Microsoft Fabric でのデータ分析のプロセスは、例えば以下の流れで行われます。
データの流れ
- Data Factory で様々なデータソースからデータを収集・変換
- Data Engineering でデータを加工
- Data Warehouse でデータを保存・分析
- Power BI でデータを可視化し、レポートを作成
このように、Data WarehouseはMicrosoft Fabricの中で「データを蓄積・分析」する役割を担っています。
Synapse Data Warehouseとの関係性
Microsoft FabricのData Warehouse は、Azure Synapse Analyticsの Synapse Data Warehouse(旧 SQL Data Warehouse)の進化版です。
従来の機能を活かしつつ、Microsoft Fabric 環境に最適化されています。進化した点は以下の通りです。
- Microsoft Fabric との統合が強化
OneLake や Power BIなどの Microsoft Fabricのサービスと統合され、データの連携がスムーズになりました。
- 使いやすさが向上
従来の Synapse に比べて、直感的な UI になり、SQL ベースの開発がよりシンプルに行うことができます。
- 運用管理の負担が軽減
Microsoft Fabric は完全マネージド型の SaaS(Software as a Service) に近いモデルとなり、スケール調整やリソース管理が自動化されました。
このように、Microsoft FabricのData Warehouse は、Synapse Data Warehouseの機能を発展させ、よりシンプルで効率的なデータ管理・分析を実現するプラットフォームとなっています。
データウェアハウス(DWH)の基本
データウェアハウスの概念や特徴を理解することで、Microsoft FabricのData Warehouseがビジネスにもたらす価値をより深く理解できます。
このセクションでは、データウェアハウスの基本から解説します。
データウェアハウスの定義
データウェアハウス(DWH) とは、企業のさまざまなシステムからデータを収集し、一元管理して分析・レポート作成に活用するためのデータベースのことです。
主に ビジネスインテリジェンス(BI)やデータ分析に特化した構造を持っています。
主な特徴は次のとおりです。
- 統合
異なるシステム(ERP、CRM、IoT、外部データなど)からデータを集約し、一元管理します。 - 時系列データの蓄積
過去のデータを長期間保存し、トレンド分析や履歴管理を可能にします。 - 最適化されたデータ構造
分析やクエリ処理を高速化するため、データは正規化・非正規化が適切に設計されています。 - 主に読み取り(リード)用途
日々の取引を処理する一般的なデータベース(OLTP)とは違い、大量のデータを素早く検索・集計できるように設計されています(OLAP構造)。
データウェアハウスの基本的な仕組み・アーキテクチャ
データウェアハウスは、主に以下の3層のアーキテクチャで構成されます。
1. 最下層(データの収集・整理)
この層では、さまざまなデータソース(業務システム、外部データなど)からデータを収集し、整理(整形・変換)する処理を担当します。
主な処理
- ETL(Extract, Transform, Load):データを抽出し、整形(不要なデータを削除・統一)、データウェアハウスに格納
- ELT(Extract, Load, Transform):データをそのまま格納し、データウェアハウス内で整形
2. 中間層(データの高速処理・分析)
この層では、大量のデータを素早く検索・分析できるように処理します。 ここで使われるのが OLAP(オンライン分析処理) という技術です。
3. 最上位層(データの可視化・レポート作成)
この層では、エンドユーザーがデータを簡単に分析・可視化できるようにする役割を担います。BIツール(Power BI、Tableau など)を用いて、グラフやダッシュボードで可視化 します。
他のデータ管理システムとの違い
Microsoft FabricのData Warehouse は、他のデータ管理システムとは異なる特性を持っています。
ここでは、主要なデータ管理システムとの違いを比較し、Microsoft FabricのData Warehouseがどのような場面で最適な選択となるかを解説します。
データベース(DB)との違い
データベースは、日常業務で利用されるデータをリアルタイムで管理するための仕組みです。
例えば、ECサイトの注文管理システムや顧客管理システム(CRM)では、データの追加・更新・削除が頻繁に発生し、正確な情報を即座に反映する必要があります。
一方、データウェアハウスは、企業内のさまざまなデータを統合し、分析しやすい形で蓄積する ことを目的としています。
データウェアハウスでは、データの削除や更新はほとんど行わず、追加のみを基本とし、BIツールやSQLクエリを使って効率的に分析できるよう最適化されています。
詳細な違いは次のとおりです。
項目 | データベース | データウェアハウス |
|---|---|---|
目的 | 日常業務のデータ管理 | データの統合・分析 |
データの処理 | 追加・更新・削除が頻繁に発生 | 追加のみ(履歴データを重視 |
利用用途 | 受注管理、顧客管理、在庫管理 | 営業・マーケティング分析、経営判断 |
処理方式 | トランザクション処理(ACID特性) | 分析向けに最適化(BIツール・SQLクエリ |
つまり、データベースは「日々の業務データをリアルタイムで管理するシステム」、データウェアハウスは「過去のデータを蓄積し、分析するためのシステム」 という違いがあります。
OneLake との違い
データレイクは、データをそのままの形式で大量に保存できるストレージ であり、Microsoft Fabricではこの役割を いわゆる OneLake が担っています。
- 生データ(構造化データ・非構造化データの両方)を保存可能
- 事前のデータ整備は不要(保存してから必要に応じて加工)
- 機械学習やビッグデータ分析向け
一方、データウェアハウスは、あらかじめ整理・加工されたデータを保存し、ビジネス分析に最適化されたストレージ です。
そのため、データレイクは「大量のデータをそのまま保存し、自由に分析できるストレージ」、データウェアハウスは「整理されたデータをすぐに分析できるストレージ」 という違いがあります。
Microsoft Fabric上のデータ管理システムの使い分け
Microsoft Fabric では、主に以下の3つのデータ管理システムが利用可能です。
それぞれの特性を理解し、目的に応じて使い分けることが重要です。
サービス | Fabric 上での役割 |
|---|---|
Database(SQL Database | 小規模なトランザクション処理から、リアルタイム性が求められる分析用途まで幅広く対応します |
One Lake(データレイク | あらゆる形式のデータをそのまま保存・統合する基盤です。Fabric全体のデータアクセスの中核となります。 |
Data Warehouse | 大規模な構造化データを分析・可視化するために最適化された環境(OLAP)です。複雑なSQLクエリやBI連携に適しています。 |
これらのシステムは相互に連携可能であり、例えば以下のような使い分けが考えられます。
- SQL Database
リアルタイム性の高い業務データ管理、小規模なデータセットに対する高速なクエリ実行、シンプルなレポーティングなど。
【関連記事】
【Microsoft Fabric】SQL Databaseとは?サーバーレスで実現する次世代トランザクションデータベースを徹底解説
- OneLake(データレイク)
まずは多様なデータを一箇所に集約したい場合。非構造化データを含む分析や、データサイエンス用途のデータ準備の起点など。
【関連記事】
【Microsoft Fabric】OneLakeとは?統合データレイクで実現する次世代データ分析基盤を解説
- Data Warehouse
複数ソースから統合・整理された大規模データに対する高度な分析、BIツールでの詳細なレポーティング、複雑な集計処理など。
Microsoft Fabricの大きな特徴として、OneLakeが共通のデータ基盤として機能する点が挙げられます。
SQL DatabaseやData Warehouseは、OneLake上のDelta Lakeテーブルに対して、それぞれのエンジン(T-SQL、Spark SQL)でアクセスするため、データの移動なしに用途に応じた分析環境を柔軟に使い分けることが可能です。
Microsoft FabricのData Warehouseの特徴
Microsoft Fabric の Data Warehouse は、以下のような特徴を持っています。
SaaS型の提供形態
従来のSynapse Data WarehouseはPaaS(Platform as a Service)型 で、サーバーやネットワークの設定、パフォーマンス管理などが必要でした。
しかし、Microsoft FabricのData Warehouse は SaaS(Software as a Service)型になったことで、こうしたインフラ管理が不要になり、すぐにデータ分析を始めることができるようになりました。
OneLakeとの統合
OneLakeは、組織全体のデータを一元管理できる、単一の論理的なデータレイク です。異なる部署やシステムのデータを統合し、一貫性を保ちながら活用することができます。
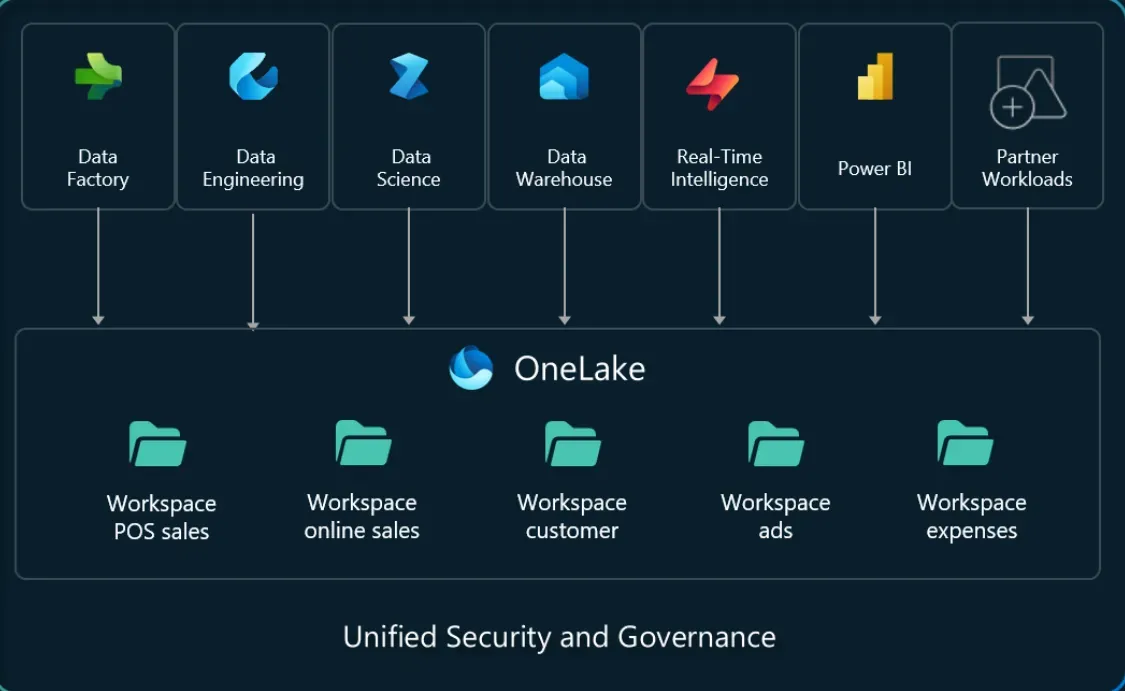
OneLakeイメージ(参考:Microsoft)
Microsoft FabricのData Warehouse は、Microsoft Fabricの統合データレイク 「OneLake」と緊密に連携しています。そのため、以下のような作業が可能です。
- OneLake 上のデータに直接クエリを実行できる(データのコピーが不要)
- Data Warehouse にデータをロードしなくても分析が可能
- データの移動や複製の手間を削減し、管理を簡素化
- リアルタイムで最新のデータを利用できる
この統合により、データの一貫性を保ちつつ、より効率的にデータ分析を行うことが可能になります。
Delta Lakeのサポート
Delta Lakeとは、データレイクに保存されたデータを、データベースのように管理できるオープンソースのストレージレイヤーです。
Parquetファイルをベースに、トランザクションログやメタデータを追加することで、信頼性や管理性を高めています。
従来のデータレイクは単なるファイルの集まりであり、トランザクション管理やデータ整合性の仕組みがありません。 そのため、大量データの処理中にエラーが発生すると、データの不整合が起きるリスクがあります。
Delta Lakeを活用することで、こうした課題を解消し、信頼性の高いデータ管理が可能になります。
Delta Lakeの主な特徴は次のとおりです。
- ACID トランザクションのサポート
データの更新や書き込みの途中でエラーが発生しても、不完全なデータが残らない。
- スキーマ強制(Schema Enforcement)
格納するデータの形式を自動的にチェックし、一貫性を保つ。
- タイムトラベル機能(過去のデータバージョンへのアクセス)
以前の状態のデータを簡単に参照することができる。
Microsoft FabricのData Warehouse は、オープンソースのテーブルフォーマットである Delta Lake をサポート しているため、データの信頼性と整合性を確保しながらスムーズなデータ管理と分析を行うことができます。
Spark エンジンによる高速なクエリ処理
Spark(Apache Spark)は、インメモリ処理と分散処理を活用し、高速なデータ処理を可能にするエンジンです。
Microsoft FabricのData WarehouseはSparkエンジンと統合されているため、以下のような利点があります。
- インメモリ処理による高速なクエリ実行
クエリの実行時にデータをメモリ上に保持し、ディスクアクセスを最小限に抑えることで、SQLクエリの実行速度が向上します。
- 分散処理によるスケーラビリティ
データを複数のノード(サーバー)に分割し、並列で処理することで、大量データでも短時間で処理が完了します。
- 多様なプログラミング言語のサポート
SQL だけでなく、Scala、Python、R などの言語を利用してデータ分析や機械学習が可能です。
AI予測と機械学習
従来のデータウェアハウスでは、データを外部にエクスポートし、機械学習環境で処理する必要がありました。しかし、Microsoft Fabric ではデータウェアハウスと機械学習の統合がスムーズになり、データの移動なしに学習を実行できます。
さらに、トレーニング済みの AI モデルをデプロイし、データウェアハウス内のデータに対してスコアリング(予測値の算出)を実行することも可能です。
そのため、データ分析から予測・意思決定までを一元化し、より効率的なデータ活用 が実現できます。
Data Factory, Power BI など他サービスとの連携
Microsoft Fabric の Data Warehouse は、以下のようにMicrosoft Fabricの他のサービスとシームレスに連携しています。
- Data Factory との連携(データの取り込み)
さまざまなデータソースから Data Warehouse にデータを取り込むパイプラインを作成できます。
- Power BI との連携(データの可視化)
Data Warehouse のデータを視覚的に分析し、対話型のレポートやダッシュボードを作成できます。
- Data Engineering との連携(データの変換・加工)
Data Warehouse に格納する前に、複雑なデータ変換や加工処理を実行できます。
- Data Science との連携(機械学習・AI分析)
Data Warehouse 内のデータを使って、機械学習モデルのトレーニングやデプロイを実行できます。
- Real-Time Analytics との連携(リアルタイムデータ処理)
ストリーミングデータを Data Warehouse に取り込み、リアルタイム分析が可能になります。
Real-Time Analytics で処理・分析されたストリーミングデータの + 結果を Data Warehouse に連携し、蓄積された他のデータと組み合わせて分析することが可能になります。
こうした連携機能により、データの取り込みから、加工、分析、可視化までを、Microsoft Fabric 内で一貫して行うことが可能 になります。
Microsoft FabricのData Warehouseの使い方
ここでは、Microsoft Fabric の Data Warehouse を使い始めるための具体的な手順を説明します。
前提条件:
- Microsoft Fabricにワークスペースが作成されていること(手順は、こちらを参考にしてください。)
ワークスペースの選択
Microsoft FabricのData Warehouse を利用するには、まず Microsoft Fabric のワークスペースを選択する必要があります。
- Microsoft Fabric のポータルにアクセスします。
 Fabricポータル画面
Fabricポータル画面 - ①左側のナビゲーションメニューで「ワークスペース」を選択し、②既存のワークスペースをクリックします。(ここでは、既存の workspacetest1 を選択します。)
ワークスペース選択画面
サンプルデータの用意
今回は、Excel 形式で「fabric_sample_data.xlsx」という名前のサンプルデータを用意しました。この Excel ファイルは、以下の 3 つのシートが含まれています。
- Customers(顧客情報)
- Products(商品情報)
- Orders(注文情報)
データの取り込み
ワークスペースを選択したら、Data Warehouse にデータを取り込みます。
- ワークスペースで、「+新しい項目」を選択し、「ウェアハウス」をクリックします。
 ウェアハウス選択画面
ウェアハウス選択画面 - データウェアハウスの名前を入力し、「作成」をクリックします。(ここでは、Datawarehousetest1 と入力しました。)
 ウェアハウス作成画面
ウェアハウス作成画面 - Data Warehouse の管理画面が開きます。ウェアハウス内のデータを管理し、SQL クエリの実行やデータの取り込み、パイプラインの設定ができます。
 Data Warehouseの管理画面
Data Warehouseの管理画面
各機能の概要は以下の通りです。 - ①上部メニュー:データの取得や SQL クエリの作成、データベース管理などの主要な操作を行うためのメニューが並んでいます。Power BI との連携や Copilot を活用した支援も可能です。
- ②中央パネル:ウェアハウスのセットアップを進めるためのエリアです。データの取り込み(データフローやパイプライン)、サンプルデータの追加、SQL クエリの作成などのオプションが用意されています。
- ③左側のエクスプローラー:作成したウェアハウスの構成を確認・管理するエリアです。スキーマやセキュリティ設定、SQL クエリ、モデルのレイアウトを管理できます。
- 上部メニューの「データの取得」からデータソースを選択します。(ここでは、新しいデータフローGen2をクリック)
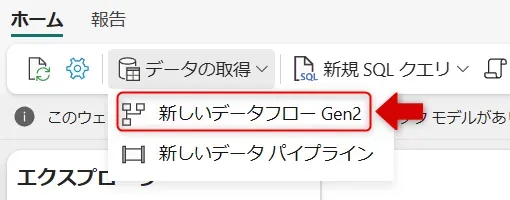 新しいデータフローGen2選択画面
新しいデータフローGen2選択画面 - Dataflowの名前を入力し(ここでは Dataflow2)、「Create」をクリックします。
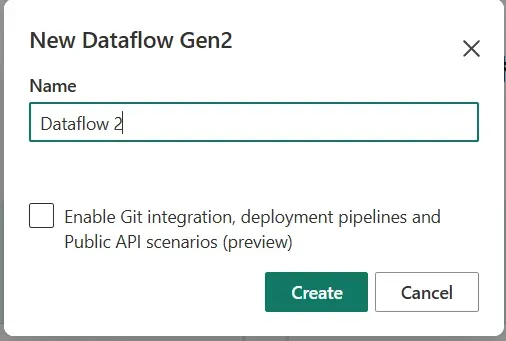 新しいデータフローGen2作成画面
新しいデータフローGen2作成画面 - 該当するインポート先を選びます。(ここでは、「Excelからインポート」)
 Excelからインポート画面
Excelからインポート画面 - 「ファイルをアップロード」を選択し、ファイルをアップロードします。ここでは、「fabric_sample_data.xlsx」というサンプルデータをアップロードしました。
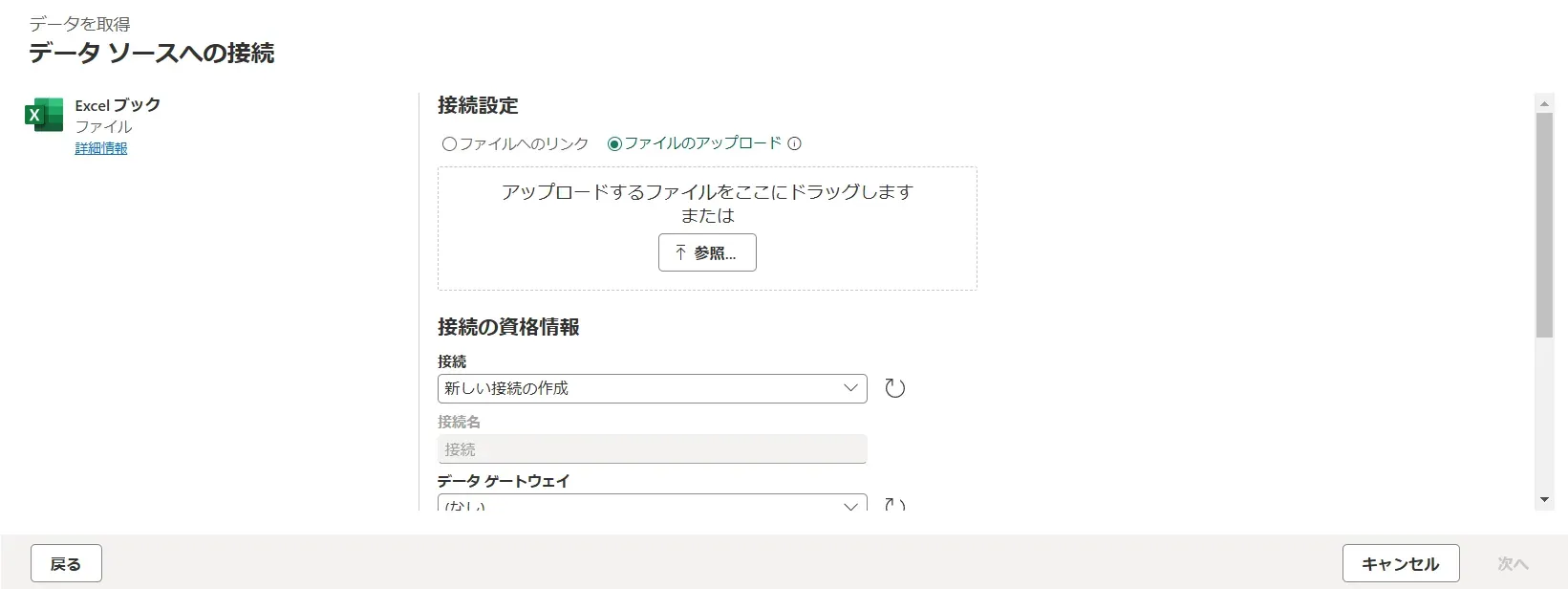 サンプルデータアップロード画面
サンプルデータアップロード画面 - アップロードしたら、「次へ」をクリックします。
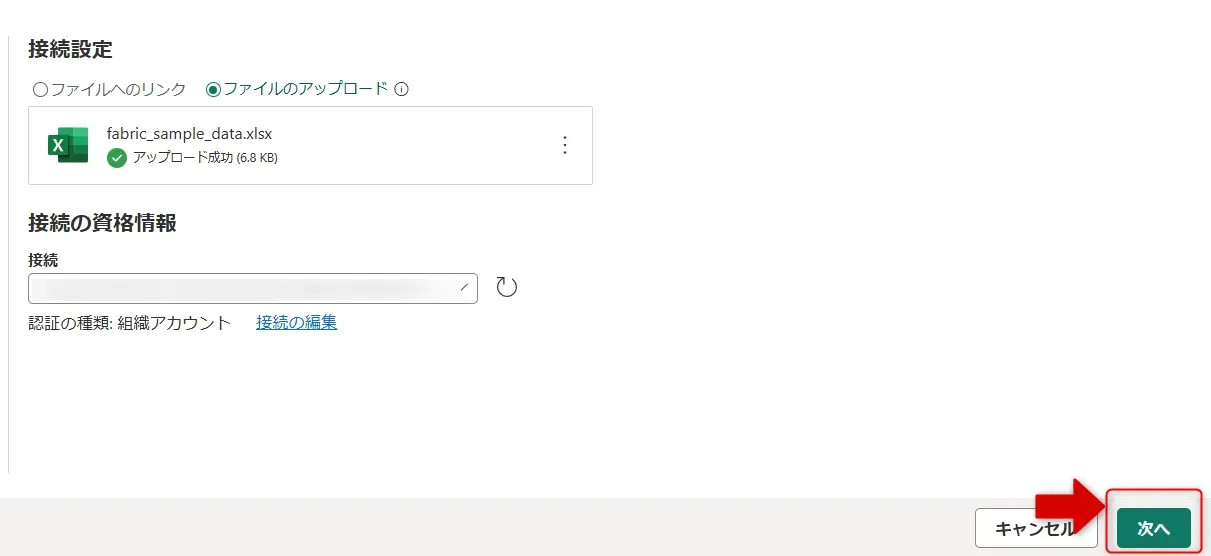 サンプルデータアップロード次へ画面
サンプルデータアップロード次へ画面 - 取り込みたいデータにチェックマークをつけます。(ここでは Customers, Orders, Products の3つを選択しました。)
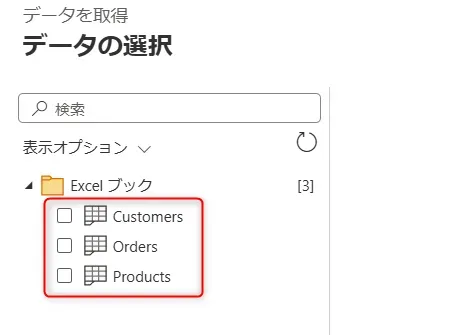 取り込みたいデータ画面
取り込みたいデータ画面 - 「作成」を押します。
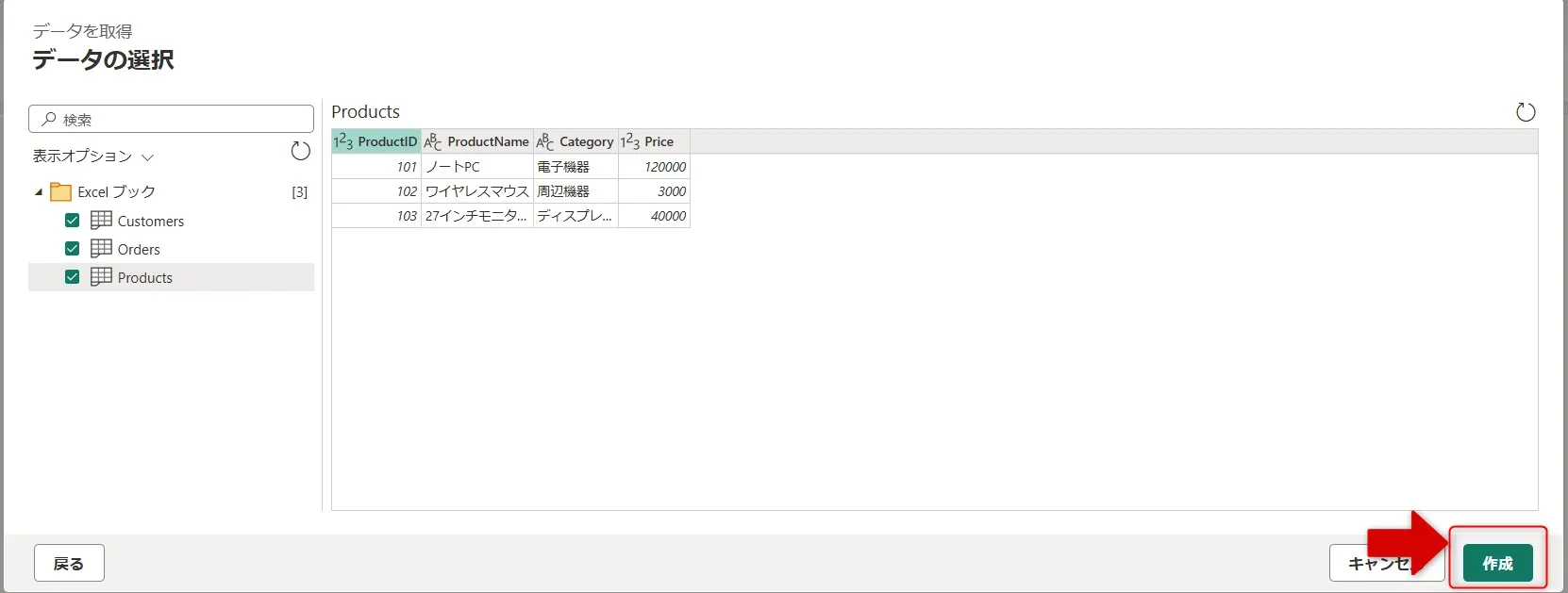 作成画面
作成画面 - 画面右下の「公開」ボタンを押して、データの変換結果を保存します。
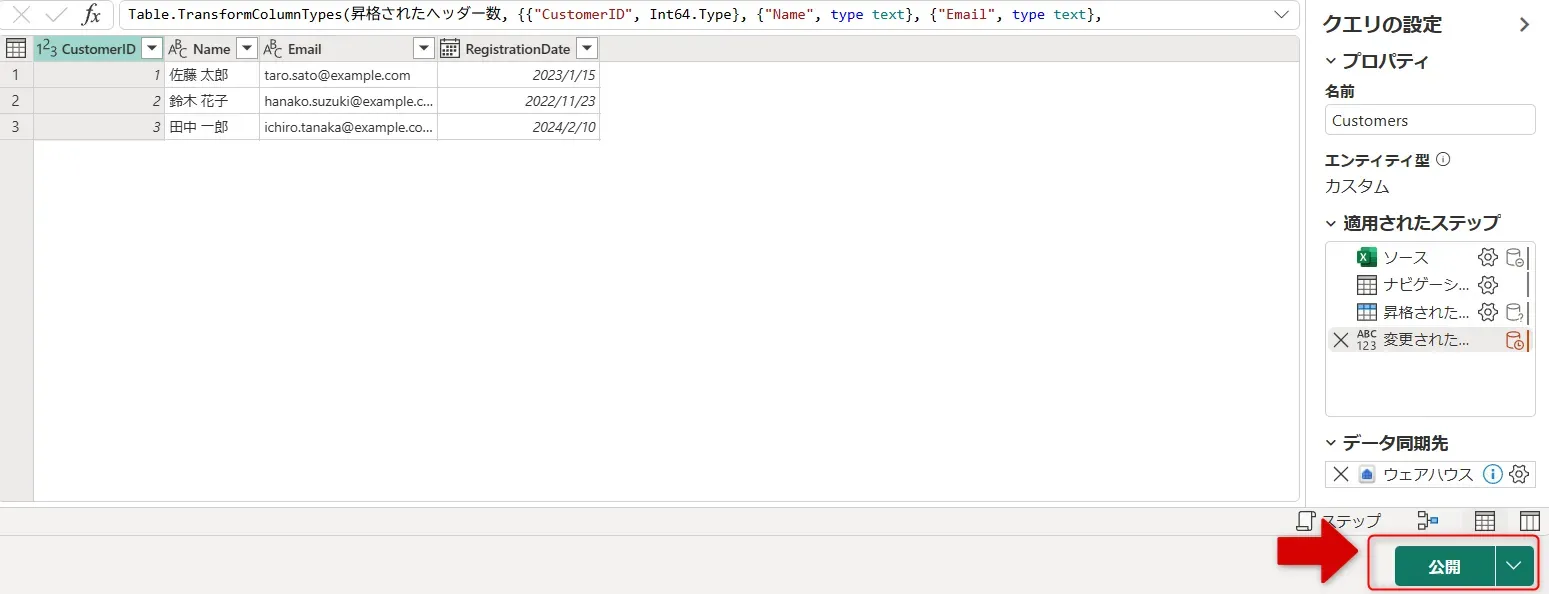 公開画面
公開画面
クエリの実行
データが取り込まれたら、SQL クエリを実行して、データを分析することができます。
- 「ワークスペース」から Data Warehouse を選択 します。(ここでは Datawarehousetest1)
 Datawarehousetest1選択画面
Datawarehousetest1選択画面 - 「新規 SQL クエリ」→「新規 SQL クエリ」をクリックします。
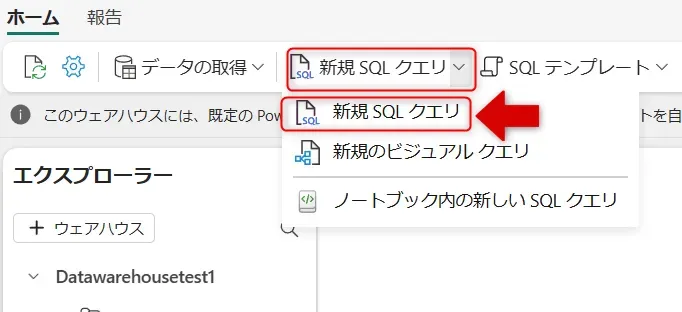 新規SQLクエリ選択画面
新規SQLクエリ選択画面 - クエリエディターに 以下の SQL クエリを記述します。
 SQLクエリ1(ここにコードを記述)
SQLクエリ1(ここにコードを記述)
このクエリを実行すると、Customers テーブルの内容が一覧表示されます。 テーブル一覧画面
テーブル一覧画面 - 次に、以下のクエリを記述します。
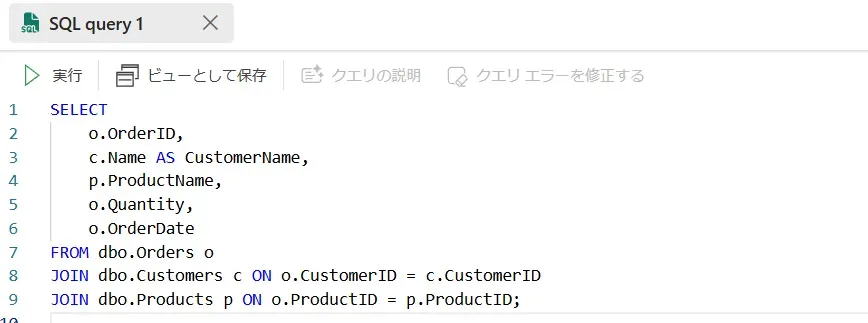 SQLクエリ画面(ここにコードを記述)
SQLクエリ画面(ここにコードを記述)
このクエリでは、Orders テーブルと Customers、Products を結合し、注文履歴を取得します。 SQLクエリ出力画面
SQLクエリ出力画面
Data WarehouseのテーブルをPower BIセマンティックモデルに追加する
Power BI セマンティックモデルに Data Warehouse のテーブルを正しく追加・同期するための設定をします。
- Data Warehouseを開きます。その後、上部の「ホーム」から、設定画面を開き、「既定の Power BI セマンティック モデルの同期」をオフからオンにします。
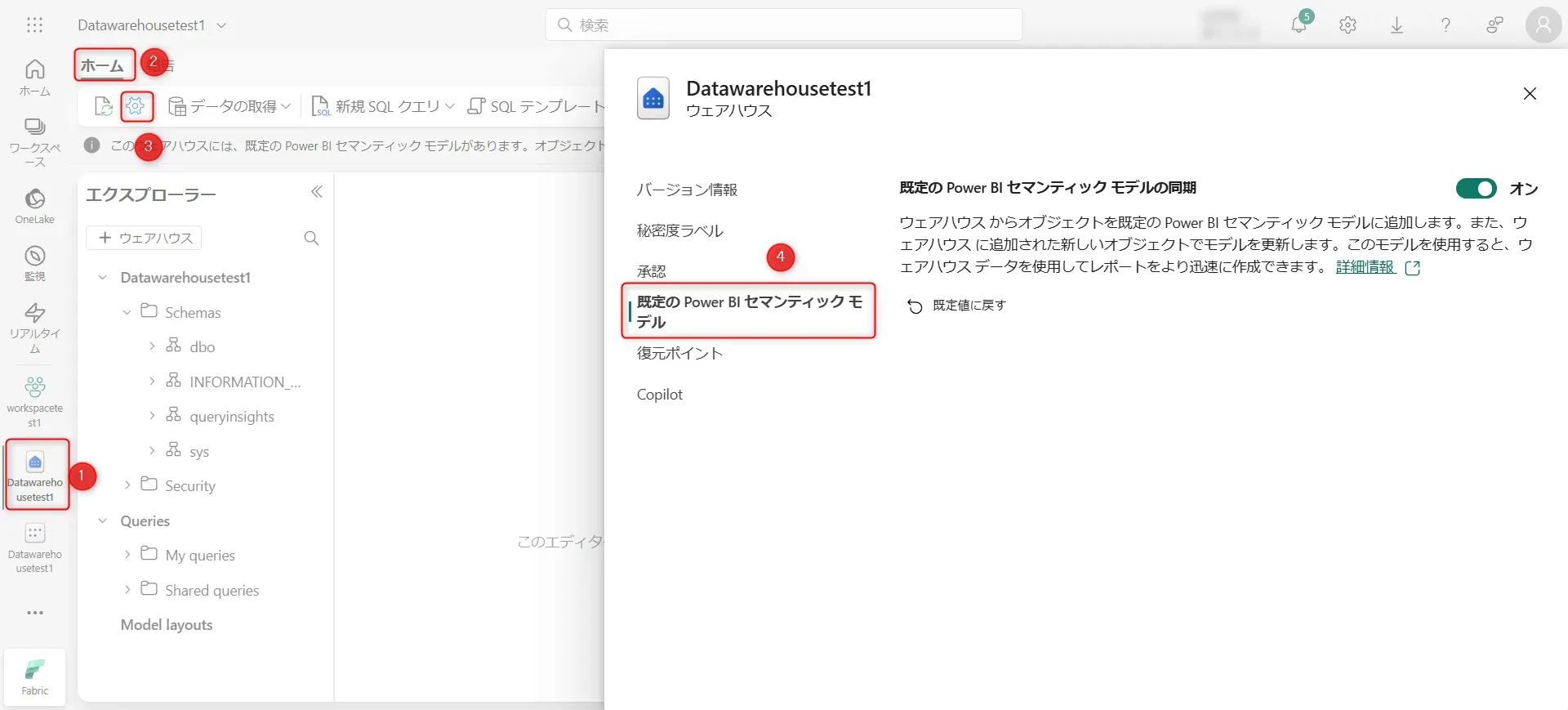 セマンティック モデルの同期ボタン
セマンティック モデルの同期ボタン - 上部メニューの「報告」タブから「既定の Power BI セマンティック モデルの管理」をクリックします。
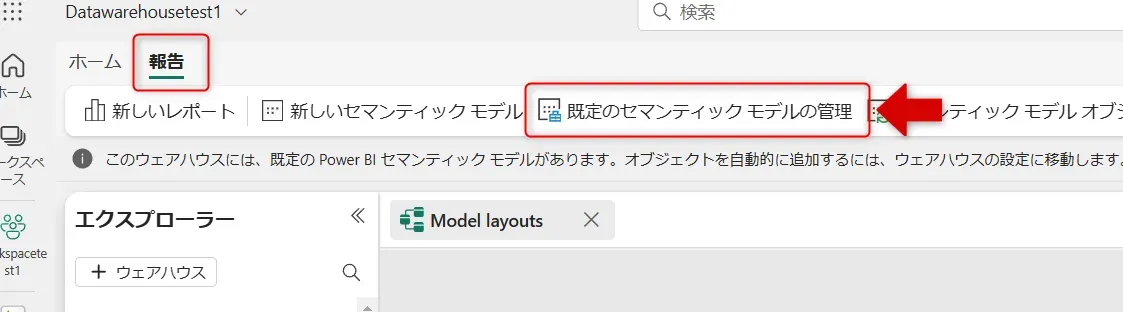 セマンティックモデルの管理画面
セマンティックモデルの管理画面 - 既存のセマンティックモデルの管理画面が開くので、ここでは「すべて選択」をクリックし、「確認」をクリックします。
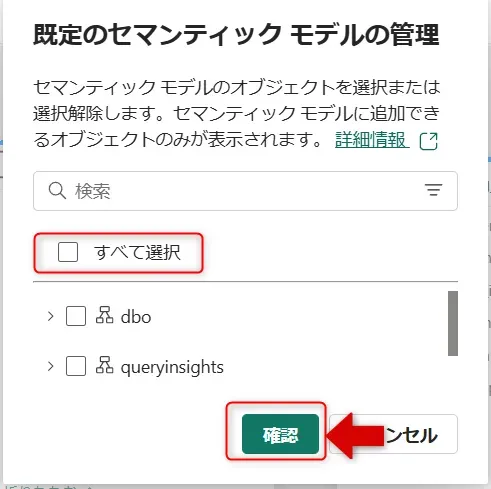 セマンティックモデルの管理詳細画面
セマンティックモデルの管理詳細画面
レポートの作成
Power BI を使って、Data Warehouse 内のデータを可視化し、レポートを作成できます。
- ワークスペースの左側のナビゲーションメニューで、「Fabric」のアイコンをクリックします。
 Fabricアイコン選択画面
Fabricアイコン選択画面 - 「Power BI」を選択します。
 PowerBI選択画面
PowerBI選択画面 - 「+新しいレポート」をクリックします。
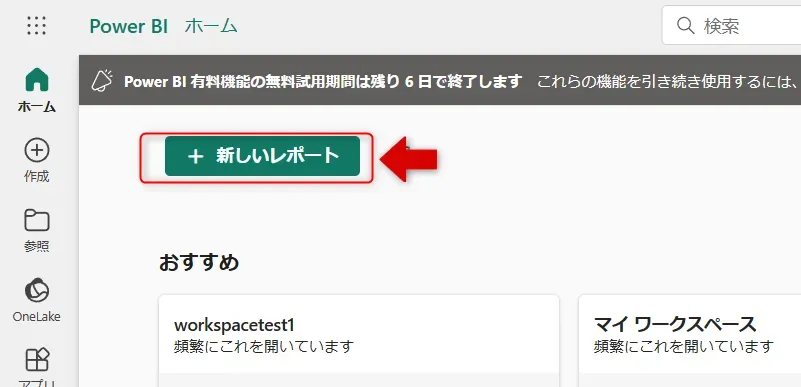 新しいレポート選択画面
新しいレポート選択画面 - 「公開されたセマンティックモデルを選択します」をクリックします。
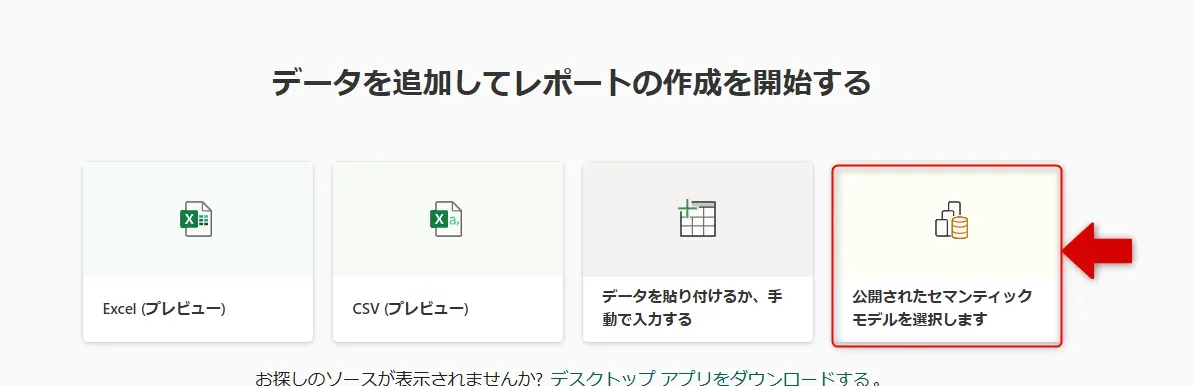 セマンティックモデルを選択画面
セマンティックモデルを選択画面 - データソースとして、作成したデータウェアハウスを選択し(ここでは、Datawarehousetest1)、「レポートを自動作成する」をクリックします。
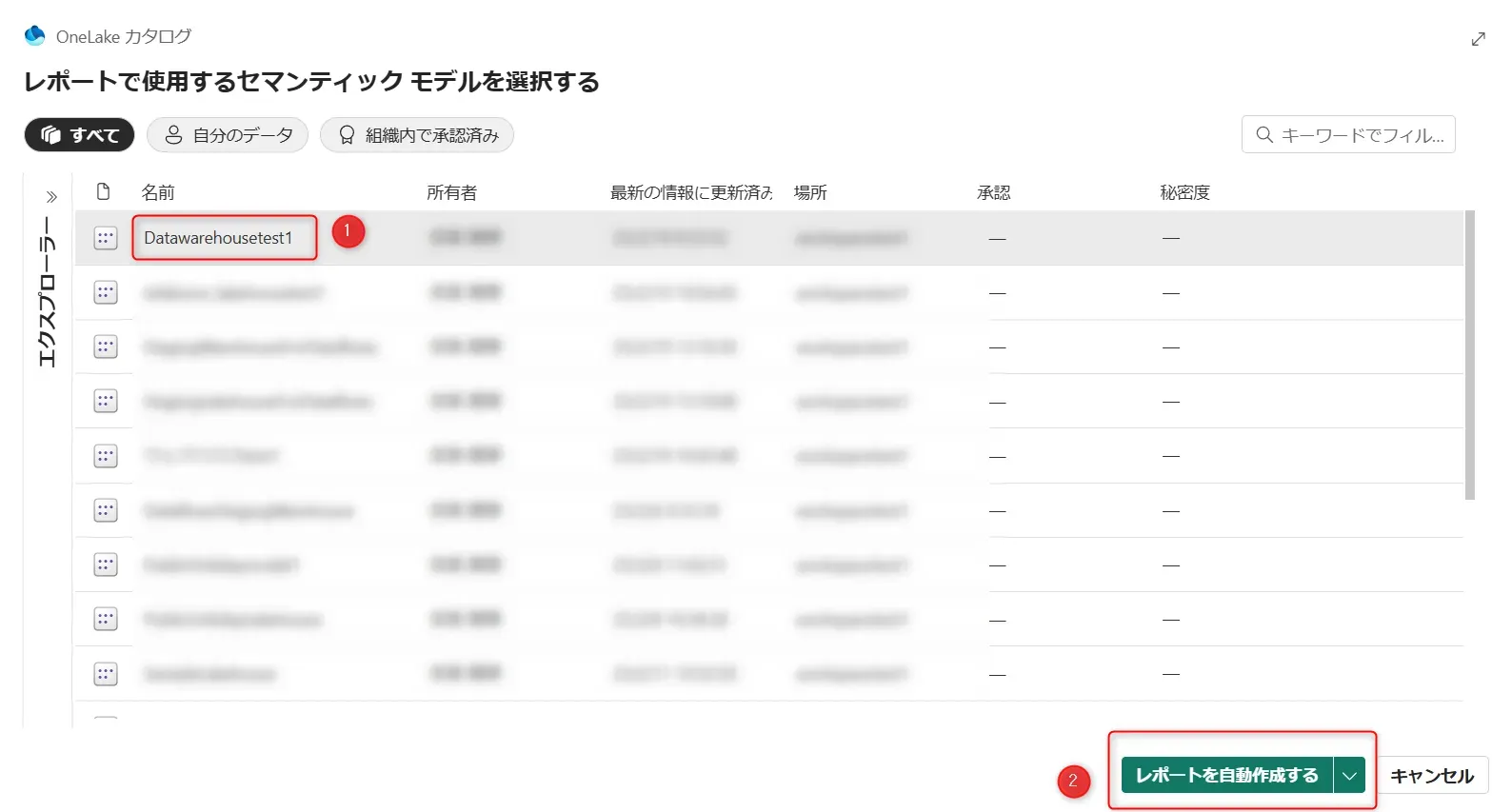 レポートの自動作成ボタン
レポートの自動作成ボタン - レポートが作成されました。
 レポート画面
レポート画面
Microsoft Fabric の Data Warehouseの料金体系
Microsoft Fabric の Data Warehouse は、独立した料金体系があるのではなく、Microsoft Fabricの容量(Capacity)に含まれるサービスの一つです。
そのため、Microsoft Fabric の全体的な料金体系に基づいて課金されます。
Microsoft Fabric では、容量(Capacity)ベースの課金モデル を採用し、利用するコンピューティングリソース(SKU)に応じて課金されます。
詳細は、こちらをご覧ください。
※本記事に記載されている情報は、2025年3月時点の情報です。変動する可能性があるため、最新情報はMicrosoft Fabricの料金詳細をご覧ください。
Microsoft Fabric の Data Warehouseのユースケース
Microsoft Fabric の Data Warehouse は、大規模データの処理、ビジネスインテリジェンス(BI)、機械学習、リアルタイム分析など、幅広い用途で活用できます。
ここでは、具体的なユースケースを紹介します。
ビジネスインテリジェンス(BI)とレポート作成
企業の経営戦略や業務改善に役立つデータ分析を行うためには、データの可視化とレポート作成が欠かせません。Microsoft FabricのData Warehouseは、Power BI と統合することで、スムーズにデータを可視化することができます。
例:
- 売上分析
地域別、製品別の売上データを分析し、成長トレンドや売上パターンを可視化。 - 顧客分析
顧客の購買履歴をもとに、リピーター率や購買傾向を分析し、マーケティング施策に活用。 - KPI 管理
企業の主要な指標(売上、利益、在庫状況など)をダッシュボードでリアルタイムに監視。
データレイクとの連携による統合データ管理
企業内にはさまざまなシステムが存在し、それぞれにデータが分散している場合が多いです。
Microsoft FabricのData Warehouse は、OneLakeを活用することで、異なるシステムのデータを統合し、データ管理の効率を向上させます。
例:
- 異なるシステムのデータ統合
CRM、ERP、IoT デバイスのデータを OneLake に集約し、一元管理。 - ETL(Extract, Transform, Load)パイプラインの構築
Data Factory を活用し、データの取り込み・変換を自動化。 - データのバージョン管理と履歴管理
Delta Lake フォーマットを活用し、データの変更履歴を追跡可能。
機械学習・予測分析(AIとの統合)
Microsoft FabricのData Warehouse は、機械学習モデルのトレーニングや予測分析にも活用できます。Azure Machine LearningやData Scienceとの統合により、高度なデータ分析が可能になります。
例:
- 売上予測
過去の販売データをもとに、来月の売上を AI モデルで予測し、在庫管理や販売戦略に活用。 - 異常検知
工場のセンサーデータを分析し、機器の異常や故障を事前に検出。 - 顧客離脱予測
購買履歴やアクセスログから、離脱リスクの高い顧客を特定し、適切なマーケティング施策を実施。
サプライチェーンと在庫管理の最適化
企業のサプライチェーンでは、在庫の適正化や供給計画の最適化が重要です。Microsoft FabricのData Warehouseを活用することで、リアルタイムのデータ分析が可能になります。
例:
- 需要予測
季節やトレンドを考慮し、適切な在庫量を予測し、過剰在庫や品切れを防ぐ。 - 在庫分析
倉庫ごとの在庫状況を可視化し、最適な補充計画を策定。 - 物流最適化
配送ルートやリードタイムを分析し、コスト削減と効率化を実現。
金融・保険業界でのデータ活用
金融業界では、データの分析とセキュリティの両立が求められます。Microsoft FabricのData Warehouseは、高度なセキュリティ機能を備えながら、大量データの分析を可能にします。
例:
- リスク管理
取引データや市場データを分析し、リスクを最小限に抑えるための対策を策定。 - 詐欺検出
クレジットカードの取引履歴を分析し、不正な取引をリアルタイムで検知。 - 顧客セグメント分析
取引履歴や信用スコアをもとに、ターゲットごとに適した金融商品を提案。
まとめ
本記事では、Microsoft Fabric の Data Warehouse について、その概要、機能、メリット、他のデータウェアハウス製品との比較、料金体系、活用方法 まで幅広く解説しました。
Microsoft Fabric の Data Warehouse は、包括的な分析プラットフォームである Microsoft Fabric の中核をなすサービスです。Microsoft Fabric の他のサービスとシームレスに連携できる点が大きな強みで、Data Factory、Data Engineering、Data Science、Real-Time Analytics、Power BI と組み合わせることで、データの取り込みから、加工、分析、可視化までを一貫して行うことができます。
Fabric Data Warehouse を導入することで、企業のデータ分析業務を効率化し、データから迅速にインサイトを得ることが可能 になるでしょう。
本記事が、Microsoft Fabric の Data Warehouse の理解を深め、皆様のデータ活用戦略の一助となれば幸いです。
東京エレクトロンデバイスは、Microsoft Fabricの導入を支援しています。データ基盤の構築、リアルタイム分析環境の構築、既存システムとの連携など、お客様の課題や目的に合わせて幅広くサポートいたします。
「データ活用を加速したい」「リアルタイムなデータ分析を実現したい」といったご要望がございましたら、ぜひお気軽にご相談ください。



