
OneLake とは
OneLake は、Microsoft Fabric の中核をなす、組織全体で共有できる単一のデータレイクストレージです。 従来のデータレイクの課題を解決し、データ統合や分析をより効率的に行えるように設計されています。
データレイクとは
OneLake(Microsoft Fabric OneLake)はデータレイクストレージですが、そもそもデータレイクとは何でしょうか。
データレイクとは、さまざまな形式や種類のデータを大規模に保存し、分析や処理に活用するためのストレージの一種です。 従来のデータベースとは異なり、構造化データだけでなく、非構造化データや半構造化データもそのままの形式で格納できる柔軟性が特徴です。
Microsoft Fabric の概要
Microsoft Fabric は、データの収集、統合、変換、分析、視覚化を一貫して行うことができる、統合データ分析プラットフォームです。
具体的には、以下のようなサービスや機能が統合されています。
- Data Factory 200 以上のコネクタを活用したデータ取り込みと変換を担当し、ETL プロセスの中心となります。
- Data Engineering Spark ベースの環境でデータを収集・処理し、大規模分析に適した形に整えます。
- Data Warehouse 大規模データの高速クエリと分析を実現し、ビジネスインテリジェンスの基盤となります。
- Data Science 機械学習モデルの開発や AI 分析を通じて、データから価値ある洞察を引き出します。
- Real-Time Intelligence リアルタイムデータの処理・分析を行い、即時の洞察やアクションを可能にします。
- Power BI データの視覚化と分析を通じて、情報に基づいた意思決定を促進します。
- SQL Database リレーショナルデータベース機能を提供し、構造化されたデータの保存と管理を行います。
- OneLake Microsoft Fabric 全体のデータを一元管理する統合ストレージとして機能します。本記事で詳しくご紹介します。
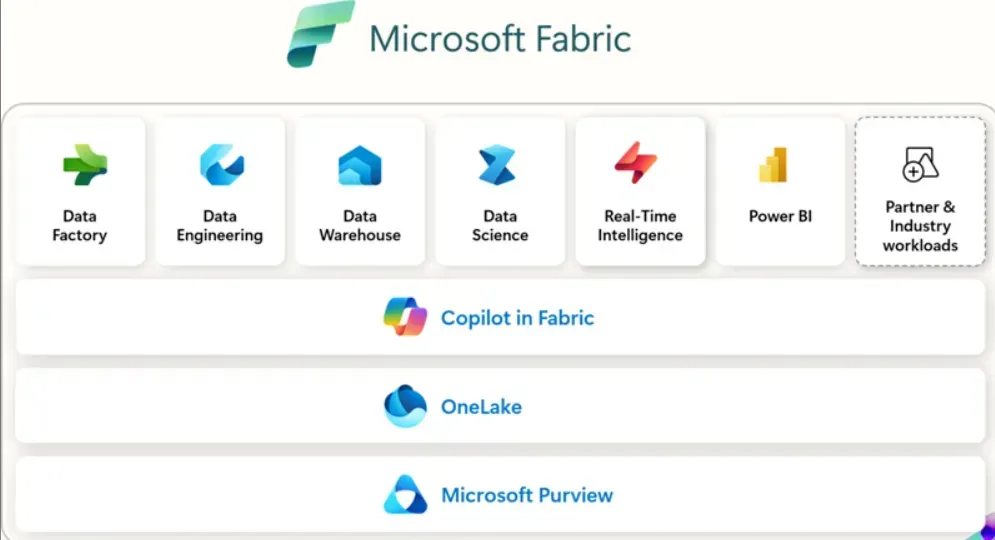
Microsoft Fabric イメージ(参考:Microsoft)
Microsoft Fabric における OneLake の役割
OneLake は、Microsoft Fabric 全体で共通利用される単一のデータレイクとして、以下のような役割を果たしています。
- Microsoft Fabric 全体での一元管理: 組織のあらゆるデータを 1 つの場所で統一的に管理する仕組みを提供します。
- エコシステム全体の中心: すべての分析エンジン(Power BI、Synapse、Databricks など)がアクセスする共通ストレージとして機能します。
OneLake の主な機能
データレイクの製品は他社(例: AWS S3、Google Cloud Storage など)にもありますが、特に OneLake が優れている点はどこにあるのでしょうか。
ここでは、競合製品と比較した OneLake の強みについてご紹介します。
Microsoft Fabric との統合
OneLake は Microsoft Fabric の中核ストレージであり、前述のすべての機能(Data Factory、Data Engineering、Data Warehouse など)とネイティブに統合されています。 統合プラットフォーム上でデータの収集、変換、分析、可視化をシームレスに行えるため、データ管理と分析が効率化されます。
他のデータレイクでは、複数のサービス間でデータを統合するために ETL プロセスや外部ツールが必要ですが、OneLake ではその手間が不要です。
ショートカット機能
OneLake のショートカット機能は、データを移動したりコピーしたりしなくても、別の場所にあるデータをあたかも同じ場所に保存されているかのように扱える仕組みです。 ファイルシステムでよく使われる「ショートカットアイコン」のようなイメージです。
通常、他の場所にあるデータ(例えば、AWS S3 や別のワークスペースに保存されたデータ)を利用するには、そのデータをコピーして自分のストレージに取り込む必要があります。
しかしショートカット機能を使えば物理的なコピーは不要で、そのデータへの「参照」を作成するだけで、自分のストレージ内にあるように扱うことができます。
 シショートカット機能イメージ(参考:Microsoft)
シショートカット機能イメージ(参考:Microsoft)
例えば、マーケティング部門が管理するデータを営業部門が活用したい場合、物理的にデータをコピーせずにショートカットを設定するだけで、即座にアクセス可能になります。
ファイルエクスプローラーとの統合
OneLake は、Windows のファイルエクスプローラーと統合することで、OneLake 上に保存されたデータをローカルのフォルダーやファイルのように扱える機能を提供します。
専用の OneLake ファイルエクスプローラーをインストールすると、OneLake 上のデータが Windows のファイルエクスプローラーに表示されます。 これにより、「ローカルのフォルダー」にアクセスしているように、ファイルのアップロード、ダウンロード、編集することができます。
 OneLake ファイルエクスプローラーイメージ(参考:Microsoft)
OneLake ファイルエクスプローラーイメージ(参考:Microsoft)
オープンフォーマット対応
OneLake は、データを保存する際に、業界標準の形式(Parquet や Delta など)を採用しています。この対応により、OneLake に保存したデータを他のツールやプラットフォームでも簡単に利用できるので、データ運用が柔軟になっています。
Parquet や Delta の概要は次のとおりです。
- Parquet 形式: 高速にデータの読み書きが可能な列指向のファイルフォーマットです。分析ツール(Power BI、Databricks、Synapse など)やエンジン(Spark、Hive など)で広く利用されています。
- Delta 形式:Parquet を拡張したフォーマットで、データの履歴管理やリアルタイム更新が可能です。機械学習やストリーミングデータ処理に最適です。
こうしたフォーマットはオープンソースであり、多くのツールが標準でサポートしているため、OneLake 内のデータを他の環境でそのまま利用できるという利点があります。
Microsoft エコシステムとの連携
OneLake は Microsoft 365 や Microsoft Entra ID と連携し、統一された認証や権限管理を実現します。このスムーズな連携により、他のクラウドストレージよりもセキュリティと利便性が向上します。
例えば、ユーザーごとにきめ細かいアクセス権を設定できるため、複数部門や組織全体で安全にデータを共有可能です。
【類似サービスとの違い】
類似のサービスも高いセキュリティやアクセス管理機能を提供していますが、特に Microsoft 製品を活用している企業にとって、OneLake は非常に有力な選択肢となるでしょう。
Microsoft Fabric Build 2025 で追加された OneLake 関連の新機能
Microsoft Build 2025 では、OneLake に関する重要な新機能がいくつか発表されました。これらの機能により、データ統合やセキュリティ、AI 対応がさらに強化され、組織のデータ活用がより効率的になります。
Cosmos DB in Microsoft Fabric
Build 2025 で発表された最も重要な機能の一つが、Cosmos DB in Microsoft Fabric です。この統合により、NoSQL データも OneLake で一元管理できるようになりました 。
Cosmos DB データは自動的に Delta Parquet 形式で OneLake に保存され、SQL データベース、ウェアハウス、レイクハウスなど他のデータとシームレスに結合可能 です。ベクトル検索やフルテキスト検索機能もサポートし、生成 AI アプリケーションの構築が容易 になります。
【主な特徴】
- 自動的なデータ統合: Cosmos DB artifact を Fabric ワークスペースに作成すると、Fabric が自動的に複製を開始し、手動設定は不要
- リアルタイム分析: T-SQL、Spark、ノートブック、Copilot を活用した Power BI、高度なデータサイエンス機能との即座の連携が可能
- AI 機能の強化: フルテキスト検索とハイブリッド検索が一般提供され、BM25 アルゴリズムによるランク付け結果をサポート
製品チームが社内ナレッジアシスタントを構築する際、マニュアルやサポート文書を JSON として Cosmos DB に保存し、ベクトル検索でセマンティックな結果を提供 できます。
OneLake Security
OneLake Security は、行レベルや列レベルのセキュリティなど、きめ細かいセキュリティ定義を OneLake に直接定義できる新機能 です。
OneLake Security により、アクセス権限を一度定義すれば、Fabric がすべてのエンジンで一貫して適用します。データ所有者はセキュリティロールを作成し、権限を細かく調整し、行と列レベルでアクセスを制御してデータを安全に共有できます。
【主な利点】
- 統一セキュリティ管理: OneLake に保存されたきめ細かいセキュリティにより、Spark、SQL エンドポイント、Direct Lake モードの Power BI などの Fabric エンジンが、各エンジンで追加ルールを必要とせず、同じセキュリティルールに自動的に従う
- 柔軟なアクセス制御: 特定のフォルダー、テーブル、さらには lakehouse の行へのアクセスのみを許可し、個人識別情報(PII)を制限しながら他のデータを利用可能に保つ
- 自動適用: セキュリティが自動的に伝播されるため、SQL でデータをクエリしても Power BI レポートで視覚化しても、許可されたもののみが表示される
例えば小売企業の場合、店舗マネージャーには自店舗のデータのみ、経理部門には全店舗データへのアクセスを、別々のセキュリティ設定なしで実現できます。
Mirroring 機能の拡張
Build 2025 では、ミラーリング機能が大幅に強化されました。SQL Server、Azure PostgreSQL、Cosmos DB のサポートが拡張され、リアルタイムレプリケーションと分析が可能 になりました。
- SQL Server 2025 対応: Microsoft SQL Server 2025 の発表により、このバージョンからのミラーリングも利用可能。SQL Server 2025 は Change Data Capture の代わりに change feed を使用
- 認証方式の拡張: Microsoft Entra ID 認証、コンテナー選択、列名での特殊文字サポート、AI ワークロード向けベクトル検索互換性などの主要な拡張機能
- 自動スキーマ推論: 自動スキーマ推論と完全な CRUD API サポートにより、OneLake での Cosmos DB データを使用したセキュアでスケーラブルなリアルタイム分析パイプラインの構築がかつてないほど簡単
Fabric Roadmap Tool の提供
Build 2025 で発表された Fabric Roadmap Tool は、今後リリース予定の主要な Fabric 機能を確認する方法として提供されています。
Fabric ワークロード全体の今後の機能を追跡する一元化されたハブとして機能し、リアルタイム更新と内部計画ツールとの統合を提供 します。内部セキュリティ要件により Workspace の Private Link サポートを待っている組織にとって、その機能がいつ計画され、いつ利用可能になるかを明確に把握できることは重要です。
Variable Libraries の統合(Notebook 強化)
Fabric Notebooks で Variable Libraries との統合がプレビューで利用可能になりました。この新機能により、コードを変更せずに設定値を一元管理でき、Notebook がよりモジュラー、スケーラブル、環境対応になります。
- 設定値の一元管理: Variable Libraries により、ノートブックコード内の値をハードコーディングすることを避け、ノートブック内で参照されるライブラリの値を更新可能
- 環境間の柔軟性: 開発、テスト、本番などの複数環境で異なる Lakehouse 名を定義し、アクティブな環境に基づいてノートブックが自動的に適応
- チーム連携の向上: 一元管理されたライブラリを活用することで、チームやプロジェクト間でのコードの再利用が簡素化
レイクハウス名が環境によって異なる場合でも、ノートブックパスを手動で編集する代わりに Variable Library で Lakehouse_name を定義し、ノートブックの実行時にアクティブな環境に基づいて自動的にファイルパスが決定されます。
これらの新機能により、OneLake はより統合的で安全、かつ AI 対応のデータプラットフォームとして進化し、組織のデータ活用における新たな可能性を開拓しています。
OneLake の料金体系
Microsoft Fabric を利用するためには、Microsoft Fabric のコンピューティング容量(Capacity Units, CUs)に応じた料金が発生します。 この容量により、Microsoft Fabric 内の各種ワークロード(Power BI、Data Factory、Synapse など)が利用可能になります。
以下は、Microsoft Fabric の料金プラン(SKU)の一部です。
容量 SKU | 容量ユニット (CU) | 従量課金制(¥/月) |
|---|---|---|
F2 | 2 | ¥40,736.628 |
F64 | 64 | ¥1,303,572.096 |
F2048 | 2048 | ¥41,714,307.053 |
OneLake ストレージの料金
OneLake に保存するデータ量に応じて、従量課金制でストレージ料金が発生します。 Microsoft Fabric の基本料金とは別途で発生します。
ストレージ | 価格 (¥/月) |
|---|---|
OneLake ストレージ | GB あたり ¥3.5653 |
OneLake BCDR ストレージ | GB あたり ¥3.9063 |
OneLake キャッシュ (月)* | GB あたり ¥37.2024 |
※ 本記事に記載されている情報は、2025 年 2 月時点の情報です。変動する可能性があるため、最新の情報については、公式ページで確認してください。
OneLake の使い方
ここでは、Onelake の導入手順をご紹介します。各ステップの概要は以下となります。
- ステップ 1: Microsoft Fabric ワークスペースの作成
- ステップ 2: データレイク環境の設定
- ステップ 3: データの取り込み
※ 前提条件は次のとおりです。
- 有効な Azure アカウント、サブスクリプション、リソースグループ
- Microsoft Fabric の有効化
ステップ 1: Microsoft Fabric ワークスペースの作成
OneLake を利用するためには、まず Microsoft Fabric のワークスペースを作成する必要があります。
- Power BI サービスにアクセスし、Microsoft でサインインします。
 PowerBI サインイン画面
PowerBI サインイン画面 - 「ワークスペース」をクリックします。
 ワークスペース選択画面
ワークスペース選択画面 - 「新しいワークスペース」をクリックします。
 新しいワークスペース選択画面
新しいワークスペース選択画面 - 「ワークスペースの作成」画面で、適切な設定をします。 「適用」をクリックします。
 ワークスペースの作成画面
ワークスペースの作成画面
ステップ 2: データレイク環境の設定
OneLake は、Microsoft Fabric ワークスペースに付属する形で自動的にプロビジョニングされます。ただし、データの整理や管理を目的にレイクハウスを作成する必要があります。
レイクハウスを作成することで、データを保存する論理的な構造が整備され、データの保存、クエリ、分析が効率的に行える環境が整います。
- 「ワークスペース」→ 新しく作成したワークスペースをクリックします。
 新しく作成したワークスペース画面
新しく作成したワークスペース画面 - 「新しい項目」→「レイクハウス」をクリックします。
 レイクハウス選択画面
レイクハウス選択画面 - 「新しい lakehouse」画面で適切な設定をします。 「作成」をクリックします。
 新しい lakehouse 画面
新しい lakehouse 画面
ステップ 3: データの取り込み
OneLake に実際のデータを取り込むステップです。
- 作成した lakehouse でデータの取り込みを実施します。 本手順では「ファイルのアップロード」で実施します。
 ファイルのアップロード画面
ファイルのアップロード画面 - 「ファイルのアップロード」画面で、ローカルから適切なファイルを選択します。 「アップロード」をクリックします。
 アップロード画面
アップロード画面 - 適切なファイルがアップロードされたことを確認します。
 アップロード確認画面
アップロード確認画面 - アップロードしたファイルが存在することを確認します。
 ファイル確認画面
ファイル確認画面
ステップ 4: データの読み込み
1.アップロードしたファイルを右クリック →「テーブルに読み込む」→「新しいテーブル」をクリックします。 新しいテーブル選択画面
新しいテーブル選択画面
- 「新しいテーブルにファイルを読み込む」画面で適切な設定をします。 「読み込み」をクリックします。
 新しいテーブルにファイルを読み込む画面
新しいテーブルにファイルを読み込む画面 - レイクハウスに対象のテーブルが存在することを確認します。
 テーブル確認画面
テーブル確認画面 - 新規 SQL クエリから、SQL クエリを発行できます。
 新規 SQL クエリ選択画面
新規 SQL クエリ選択画面
 SQL クエリ画面
SQL クエリ画面
- 「モデルレイアウト」からテーブルのモデルレイアウトを確認することができます。
 モデルレイアウト画面
モデルレイアウト画面
OneLake 導入時のポイント・注意点
ここでは、OneLake の導入時のポイントについてご紹介します。
データガバナンス・セキュリティ
OneLake を導入する際には、部門横断で大量のデータが集中することを考慮し、以下のようなセキュリティ対策を講じる必要があります。
- アクセス権限の管理: ロールベースのアクセス制御(RBAC)を活用して、ユーザーや部門ごとに適切なアクセス権を設定します。定期的な権限レビューとログのモニタリングも重要です。
- 機密データの保護: 機密性の高いデータには暗号化やデータマスキングを適用します。Azure のセキュリティツールを活用することで、データの保護レベルをさらに向上させることができます。
データ構造・スキーマ管理
異なるデータ形式やスキーマ変更には以下のように対応しましょう。
- データ形式の整理: 異なるデータ形式の明確な取り扱い方を決める必要があります。統一的なスキーマ設計を行うことで、分析効率を高めることができます。
- スキーマ変更への対応: データのスキーマ(項目や構造)は、システムやビジネス要件の変更によって変わることがあります。Data Factory や Synapse パイプラインを活用すれば、データの形式変換や構造変更に簡単に対応可能です。
コスト最適化
OneLake の利用コストを最小化するため、以下の工夫が重要です。
- データ管理の効率化: 不要なデータコピーや冗長保存を避け、OneLake を軸にデータを一元管理します。ショートカット機能を活用してデータ移動を削減しましょう。
- コンピューティング費用の抑制: ジョブスケジューリングやクエリの最適化を行い、必要なリソースのみを使用することで、コンピューティング費用を抑えることができます。
ハイブリッド/マルチクラウド環境との連携
OneLake は Azure 外の環境とも連携可能ですが、以下の考慮が必要です。
- 外部接続の設計: AWS や GCP、オンプレミスから OneLake にデータをつなぐときには、データがスムーズに流れるように転送方法やネットワークの使用量を調整します。
- ネットワーク料金の管理: リージョン間や外部クラウドからデータを取り込むときには、さらに通信料金がかかります。そのため、事前にコストを計算し、必要ならデータを効率よく処理する仕組み(キャッシュの利用など)を取り入れます。
OneLake のユースケース・導入事例
ここでは、OneLake を使った具体的な活用場面をご紹介します。
製造業における IoT データの管理と異常検知
例えば、工場内の IoT センサーから収集されるデータを活用する製造業では、以下のような課題が生じることがあります。
【課題】
- 複数の工場・設備から生成される膨大なデータが分散しており、全体像の把握が困難。
- 異常検知や予知保全のアルゴリズムが、リアルタイムでの処理・確認に欠ける。
- 分析用データの整理や統合に時間がかかり、データサイエンティストの生産性が低下。
Microsoft Fabric を活用することで、Real-time Intelligence によるリアルタイムデータ処理と、OneLake での効率的なデータ蓄積が可能になります。 蓄積されたデータは Power BI や Synapse、Spark エンジンなどを用いて詳細に分析でき、以下の成果が期待できます。
【効果】
- データ管理の効率化:OneLake の階層型構造により、工場・設備ごとのデータ整理が容易になります。
- リアルタイム分析の実現: Real-time Intelligence により、異常検知の反応時間を大幅に短縮できます。
- コスト削減:オンプレミスの保守費用削減と、データ冗長化防止によるストレージコスト削減につながります。
小売業における顧客データの統合とマーケティング最適化
例えば、小売業で POS システム、EC サイト、ロイヤルティプログラムなど複数チャネルのデータが分散している場合、以下のような課題が生じます。
【課題】
- データがサイロ化しており、顧客行動を統合的に把握できない。
- パーソナライズしたマーケティング施策が難しく、キャンペーン効果が低い。
- 分析用データの抽出と統合に手間がかかる。
OneLake を基盤にデータを統一管理し、以下の改善が期待できます。
【効果】
- 収益向上:顧客セグメンテーションを強化し、パーソナライズキャンペーンの成功率が向上します。
- 統合効率化:Data Factory を活用して、データ統合時間を短縮します。
- 顧客満足度の向上:最新データを活用した即時対応により、顧客満足度が改善します。
医療業界における患者データの管理と研究支援
例えば、病院や研究機関で患者データを活用した医療研究を進める際に、以下の課題が生じることがあります。
【課題】
- 部門ごとにデータが分散しており、研究のための統合が困難。
- 機密データの共有には高いセキュリティが必要。
- 分析用データの準備に時間がかかり、研究効率が低下。
OneLake を活用して患者データを安全かつ効率的に統合することで、以下の成果が期待できます。
【効果】
- データ統合の効率化:OneLake のショートカット機能により、部門間でのデータ共有が迅速になる。
- セキュリティの強化:Microsoft Entra ID を活用し、機密データを保護できる。
- 研究スピード向上:データ準備時間を削減し、分析・研究プロセスを加速する。
まとめ
本記事では、OneLake の概要から必要性、特徴、ユースケース、そして導入手順などについて解説しました。
OneLake は、Microsoft Fabric のコアとなる“単一のデータレイク”であり、組織全体のデータを集約・管理する要となっています。従来のデータレイク/ウェアハウスの課題であるサイロ化や複数ツールの連携コストを低減し、ビッグデータ分析や BI の効率的な活用に役立ちます。 またハイブリッドクラウドやマルチクラウドとの連携も可能なので、セキュリティやコスト最適化を考慮しながら導入することで、大きなビジネス価値を生み出す統合データ基盤を実現できるでしょう。
ぜひ OneLake を活用し、組織のデータ活用を次のレベルへ進め、効率化と新たなビジネスチャンスの創出に挑戦してみてください。 本記事がその一助となれば幸いです。
東京エレクトロンデバイスは、Microsoft Fabric の導入を支援しています。データ活用基盤の構築、データ統合、分析に関するご相談など、専門知識を持つスタッフがお客様の課題解決をサポートします。
無料相談も受け付けておりますので、お気軽にご相談ください。 お問い合わせはこちら



