

Build 2026が示した「クラウドからローカル/エッジまで」のAI実行の選択肢
Microsoft Build 2026では、生成AIをクラウドのAPI経由で利用するだけでなく、ローカル/エッジ側で動かすための具体的な選択肢が複数発表されました。Microsoftはこの方向性を「Unmetered Intelligence」というキーワードで打ち出し、クラウドのトークン課金やデータ越境の制約を回避するための実装パターンとして、ローカル実行の比重を引き上げています。
中心となるFoundry Localは、MicrosoftがWindows端末やローカル環境でLLM・SLMを実行できるよう提供するオンデバイス推論基盤です。
Build 2026では、ローカルAI実行基盤に関わる複数の発表が相互に連携する形で示されました。具体的には、Windows向けの新しいオンデバイスSLMであるAion 1.0、Windows AI APIsの拡張、OpenClaw on Windowsのネイティブ統合、Microsoft Execution Containersの4つです。
本記事で整理する4つの実行場所
Microsoftの公式資料では、Foundry Local、Foundry Local on Azure Local、Azure Local、Windows AI APIsなど、端末上やオンプレミス、分散環境でAIを実行するための関連製品・機能がそれぞれ説明されています。ただし、Microsoftが「クラウド、オンプレミス、現場エッジ、Windows端末」という4分類を公式に示しているわけではありません。
本記事では、企業が実行場所を比較しやすいように、AIの実行場所をクラウド、オンプレミス、現場エッジ、Windows端末の4つに分けて整理します。オンプレミス、現場エッジ、Windows端末はいずれもクラウド外のローカル/エッジ側の実行環境に含まれますが、データの所在、運用主体、ハードウェア構成、レイテンシ要件が異なるため、運用上の比較軸として分けて扱います。
実行場所 | 主な役割 | 代表的な製品・構成 |
|---|---|---|
クラウド | 大規模モデルでの推論、長文ドキュメント処理 | Microsoft Foundry、Foundry Agent Service |
オンプレミス | 機密データを社外に出さない推論、業務システム連携 | Azure Local(Foundry Local on Azure Local)、オンプレミスサーバー |
現場エッジ | 工場・店舗の現場推論、低帯域・低レイテンシ環境 | Azure Local(Foundry Local on Azure Local)、エッジサーバー |
Windows端末 | 開発者向けローカル検証、業務PCでのオフライン処理 | Foundry Local、Windows AI APIs、Windows ML |
この表では、Microsoftの公式分類ではなく、実務上の比較軸として4つの実行場所を整理しています。Windows端末ではFoundry Local、オンプレミスや現場エッジではFoundry Local on Azure Localなど、実行環境に応じて利用する製品・構成が異なります。
ローカル実行が広がった3つの背景
クラウドとローカル/エッジ側の実行環境を使い分ける背景には、企業が抱える3つの実務的な課題があります。1つ目はクラウドAPIのトークン課金が業務全体に積み上がるコスト構造、2つ目は機密データを国外のクラウドに送信できないという規制対応、3つ目はリアルタイム性が求められる現場処理におけるレイテンシ要件です。これらをどう解決するかを軸に、Microsoftはクラウド一辺倒からマルチロケーション実行へと舵を切っています。
特に半導体製造装置や電子部品の検査ライン、FA制御系のように、現場で生まれたデータをそのまま現場で処理したい業務では、現場エッジやWindows端末での実行が有力な選択肢として浮上しています。
Microsoftは、Microsoft Foundry、Foundry Agent Service、Foundry Local、Foundry Local on Azure Local、Windows AI APIsなど、実行環境に応じた複数の製品・機能を提供しており、業務単位で実行場所を選べるアーキテクチャが整いつつあります。
クラウドとローカル/エッジ側の実行環境比較
ここまで本記事で整理した4つの実行場所を、AIワークロードの実行場所を選ぶための観点で比較すると、以下のようになります。
下表は、Microsoftの各公式資料で説明されているクラウド、オンプレミス、分散環境、オンデバイスといった実行形態を踏まえつつ、製造業などの現場運用で違いが出やすい項目を比較したものです。「現場エッジ」はMicrosoftが示した独立した公式レイヤー名ではなく、本記事上の運用区分です。
※実値はワークロード・モデル・ネットワーク条件により変動します。
項目 | クラウド(Microsoft Foundry) | オンプレミス | 現場エッジ | Windows端末(Foundry Local) |
|---|---|---|---|---|
データの所在 | クラウド側 | 自社環境内 | エッジ拠点内 | 端末内 |
想定レイテンシ(目安) | 高め | 中 | 低 | 低 |
コスト構造 | トークン従量課金、予約型/専用型のクラウド課金 | サーバー保有+運用費 | エッジ機器+運用費 | 端末保有+運用費(クラウドAPIのトークン課金は発生しない) |
代表的なワークロード | 大規模生成・長文要約 | 機密データの社内検索 | 製造現場の検査・判定 | 開発検証・端末上の業務支援 |
この表からわかるとおり、データの所在・レイテンシ・コスト構造の3つが実行場所の選定を左右する主要な軸となります。特にコスト構造の違いは大きく、クラウド側はトークン従量課金や予約型/専用型のクラウド課金で利用量に応じた費用が継続的に発生します。
一方で、Foundry Local GA公式ブログで「no cloud dependency, no network latency, and no per-token costs」と説明されているとおり、Foundry Localによるローカル推論そのものは、クラウドAPIのper-token課金を前提としません。
ただし、端末・電力・運用コスト、利用モデルのライセンス、クラウド側サービスを併用する場合の課金は別途確認が必要です。MicrosoftがこれをUnmetered Intelligenceと呼ぶ理由は、推論実行に対するper-token課金がローカル側で発生しない構造にあります。
コスト・レイテンシの傾向
レイテンシの面では、本記事で整理した4つの実行場所にそれぞれ異なる傾向があります。クラウドはネットワーク経由のため遅延が大きくなりやすく、現場エッジとWindows端末は処理場所を利用者や現場に近づけられるため、応答時間を短縮しやすくなります。特にWindows端末上で完結する処理では、クラウド往復が不要になります。製造現場の検査ラインのように1秒以下の判定が求められる業務では、現場エッジやWindows端末での実行が有力な選択肢となります。
モデル規模を含む具体的な振り分け例については、後述の「3層 inference routingでのモデル振り分け」で解説します。
実務での選定アプローチ
実務での選定にあたっては、まずクラウド側とローカル/エッジ側に大別します。そのうえで、ローカル/エッジ側について、オンプレミス、現場エッジ、Windows端末のどこに配置するかを、機密性、レイテンシ要件、対象モデルの規模、運用負荷を踏まえて絞り込みます。
1つの実行場所で全社のAIを統一する発想ではなく、業務単位で実行場所を選べるようになった点が、Build 2026がもたらした実務的な変化です。
Foundry LocalのBuild 2026強化:Unmetered Intelligence
Build 2026では、Foundry LocalがWindows端末上のオンデバイス推論基盤として大きく強化されました。
中核は、Foundry Local自体の対応環境拡張と、Windows向けオンデバイスSLMやWindows AI APIsとの組み合わせです。これに加えて、Azure Localでのマルチノード推論サポートも発表されています。
具体的には、v1.2.0リリースでLinux ARM64対応、多言語ASR音声モデルへの対応、WinML 2.0へのアップグレード、WebGPU実行プロバイダー対応が追加されました。さらにv1.2.1では、ja-JPなどの地域別バリアントを含むASRの言語カバレッジが拡張されています。あわせて、Foundry Local on Azure Localのパブリックプレビューが拡張され、マルチノード推論とAzure Arc/Kubernetes連携にも対応しました。
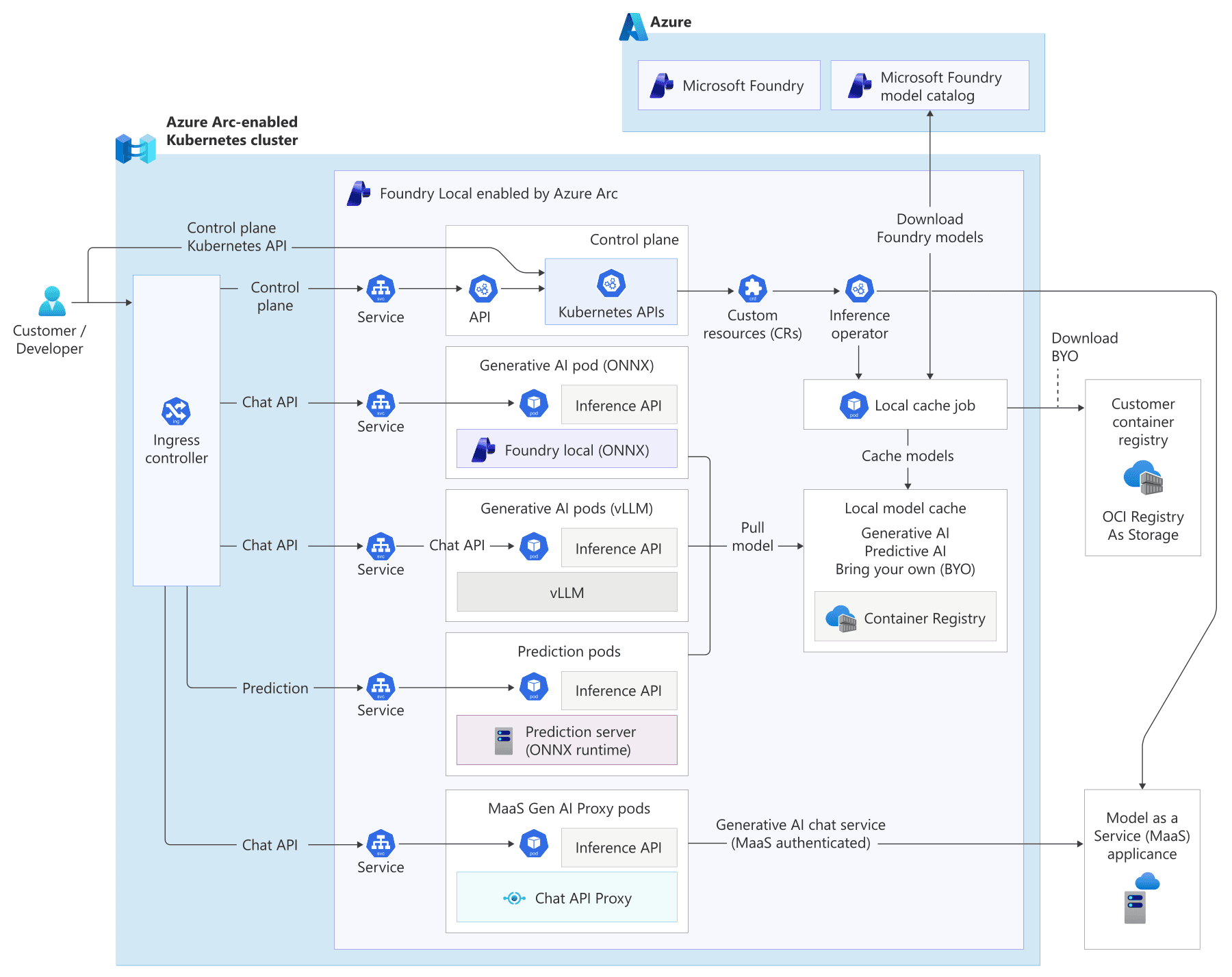
Foundry Local on Azure Localのアーキテクチャ 引用:Microsoft Learn
図のとおり、Foundry Local on Azure LocalはAzure Arc-enabled Kubernetes cluster上に、Foundry Local enabled by Azure Arc、Inference operator、Custom resources、Local model cache、ONNX/vLLMのGenerative AI podを配置する構成です。
Azure側のMicrosoft Foundryやモデルカタログからモデルを同期し、オンプレミスまたはエッジ側のKubernetes環境で推論エンドポイントを提供できる点が、端末単体のFoundry Localとは異なります。
一方、Windows端末上で動くFoundry Local単体の構成は、以下の図のように整理できます。
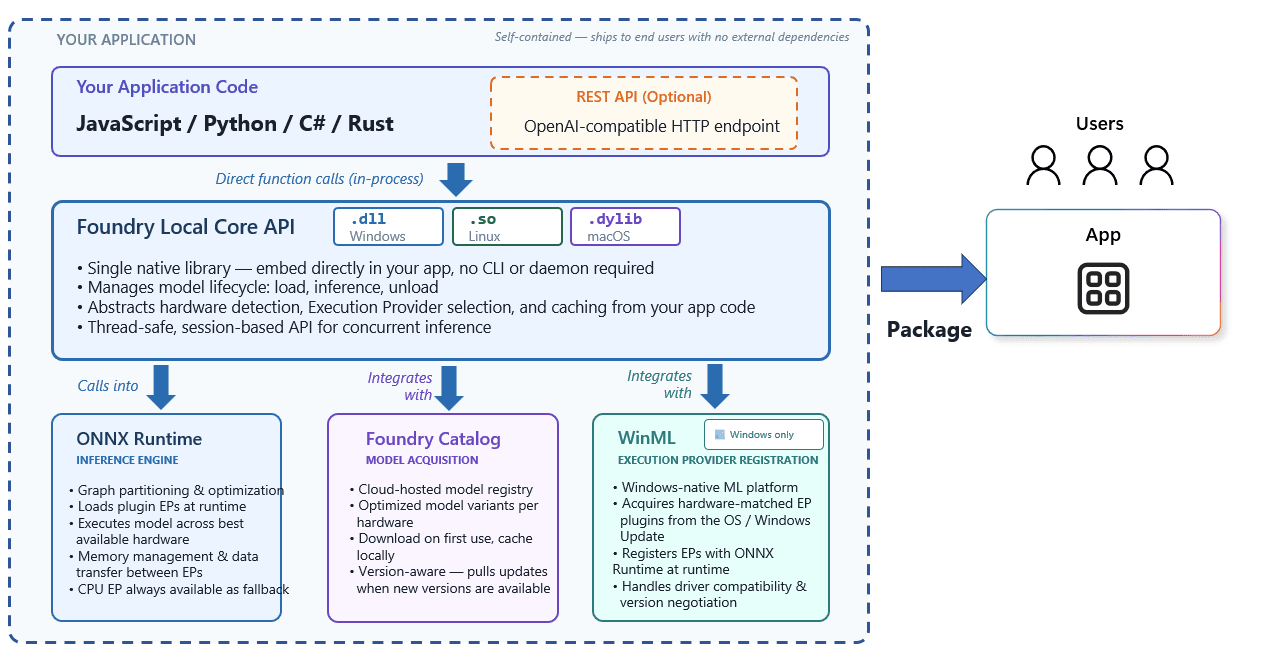
Foundry Localのアーキテクチャ 引用:Microsoft Learn
Foundry Local単体では、アプリケーション内のJavaScript、Python、C#、Rustなどのコードから、Foundry Local Core APIを直接呼び出してローカル推論を実行します。Core APIはWindows向けの.dll、Linux向けの.so、macOS向けの.dylibとして提供され、CLIや常駐デーモンを前提にせず、アプリケーションに直接組み込める構成です。
Core APIは、モデルの読み込み、推論、解放といったライフサイクル管理に加えて、ハードウェア検出、実行プロバイダーの選択、キャッシュ管理を抽象化します。
内部的にはONNX Runtimeを呼び出し、Foundry Catalogからモデルを取得・キャッシュし、Windows環境ではWindows MLとも連携します。これにより、開発者はローカル推論機能をアプリケーションに組み込み、外部依存を抑えた自己完結型のアプリとしてユーザーに配布しやすくなります。
Aion 1.0 InstructとAion 1.0 Plan
Windows向けの新世代オンデバイスSLMとして、Aion 1.0 InstructとAion 1.0 Planが発表されました。Foundry Localがローカル推論基盤を担う一方、Aion 1.0はWindows上でのテキスト処理やローカルエージェント実行を支えるモデル群として位置づけられます。
Aion 1.0 Instruct
軽量かつ高速化したオンデバイスSLMです。テキストの要約、書き換え、インテント解析、アクセシビリティ対応に最適化されています。
Edge Insiderチャネルで実験版のプレビューが開始されており、2026年7月にはHugging Faceでオープンウェイト化が予定されています。
Aion 1.0 Plan
140億パラメータの推論・ツール呼び出しモデルで、32Kコンテキスト長に対応します。対応デバイスのWindows上で利用できる予定で、完全にローカルで動作するエージェントワークフローの実現が目標として示されています。
この2モデル構成は、軽量な処理はInstructで、計画立案やツール呼び出しはPlanで担うという役割分担を意図しています。従来のオンデバイスSLMでは、推論能力の不足からエージェント的な多段処理がクラウドに依存していました。
Aion 1.0 Planの追加により、エージェントが自律的に動作する仕組みをWindows端末側で完結できる構成が、実装可能な水準に近づきつつあります。
クラウドの推論モデルを呼び出さずに端末側で完結できると、データ越境の発生がなく、推論実行に対するクラウドAPIのper-token課金も発生しません。端末・電力・運用コストやモデルライセンス、クラウド連携サービスを併用する場合の課金は別途必要ですが、製造現場のオフライン環境や、社内ネットワークから外部への通信が制限される業務でも、エージェント型のAI支援が利用しやすくなります。
Frontier Tuningとクラウド側との連携
Microsoft Foundry側のアップデートとして、Frontier Tuningが発表されました。これは、特定ドメインに特化したモデル最適化を低コストで実現するファインチューニング機能です。Microsoft Foundry Build Editionでは、技術ドキュメント領域においてGPT-5.5比で約10倍超のコスト効率を達成できるとされています。
Frontier Tuningのデモ 引用:Microsoft Build 2026
社内ドキュメントや製品マニュアル、技術仕様書など、業務ドメイン固有の語彙・文脈を持つデータを扱う企業にとって、Frontier Tuningの価値は大きくなります。
汎用モデルでは精度が出にくい用語や、独自の表記ゆれを多く含む業務文書を学習させることで、現場の判定や検索の精度を上げることが可能です。
クラウド側ではFrontier Tuningで業務ドメインに特化したモデル最適化を行い、ローカル側ではFoundry Localで対応モデルを実行する、といった役割分担を検討できます。学習をクラウド側のGPUリソースで担い、推論をローカル端末側で完結させる構成は、コスト面でもセキュリティ面でも合理的な選択肢です。なお、Frontier TuningはMicrosoft Foundry側の機能、Foundry Localはローカル実行基盤としてそれぞれ独立しており、両者を直接つなぐ運用経路は2026年6月時点では公式に明示されていません。
なお、Foundry Local自体の基本的な使い方やインストール手順については、東京エレクトロンデバイスAzureコラムの「Foundry Localとは?ローカル端末でLLMを動かす仕組み・使い方を解説」をご参照ください。
Windows AI APIsの拡張
Windows AI APIsは、Windows端末上でAIを呼び出すための標準APIセットです。Build 2026では、これまで主にNPU搭載PC向けだった一部機能を、CPUやGPUにも広げるアップデートが発表されました。
主な拡張内容は以下のとおりです。
- インボックスSLMのGPU対応拡大:従来のNPU専用構成から、対応要件を満たすGPU上での実行にも対応します。これにより、capable GPUを搭載したWindows 11 PCでもインボックスSLMが利用可能となりました。
- Video Super ResolutionのCPU対応追加:GPU非搭載端末でも利用可能になります。リモート会議やストリーミング映像の品質向上を、GPU非搭載のオフィスPCでも利用できる構成になりました。
- Speech Recognition APIの新規追加:リアルタイムまたはバッチでのオンデバイス音声認識を提供します。初期は英語対応で、段階的にグローバル展開が予定されています。
- Windows ML 2.0の強化:新しいONNX Runtimeにより、実行環境に応じたExecution Providerを利用してNPU・GPU・CPUで推論を高速化できる仕組みになりました。Build 2026のBRK260セッションでは、Windows MLを使ってGPU・NPU・CPU横断でローカルAIワークロードを動かす構成や、WebNN対応が紹介されています。
これらのAPIによって、NPU搭載PC中心だったローカルAI機能の一部が、対応要件を満たすWindows 11 PCのCPUやGPUにも広がりました。
最低ハードウェア要件は機能ごとに異なりますが、業務PCを全面的に入れ替えなくても、対応する現有端末でローカルAIの活用を始められる点が企業導入における大きな意味を持ちます。
特にWindows ML 2.0のハードウェア自動分配は、端末ごとにハードウェア構成が異なる現場でも同一のアプリケーションを動かせるため、現場ごとに分岐実装を持たずに済む構成が期待できます。
関連技術として、Webアプリからオンデバイス推論を呼び出すWebNNも用意されており、Webベースの業務システムから端末側の処理を活かす設計で検討できます。
OpenClaw on Windowsとエージェント実行環境
OpenClawは、AIエージェントを構築・オーケストレーションするためのオープンソースフレームワークです。エージェントが推論、計画、タスク実行、ツール呼び出しを行うための基盤を提供します。
OpenClawのWindowsネイティブ動作
Build 2026では、OpenClawがWindows上でMicrosoft Execution Containersを活用してネイティブに動作することが発表されました。具体的には、OpenClawのnodeとgatewayがMicrosoft Execution Containersの分離環境内で動作することで、システム全体のセキュリティを保ったままエージェントを実行できる仕組みになっています。
導入面では、Windows用のコンパニオンアプリが提供されており、開発者は自身のclaw(エージェント実行ユニット)をセットアップする、または既存のclawに接続することが可能です。これにより、Windows端末をエージェントの主要な実行環境として扱う運用が、採用しやすい構成として整いました。
Microsoft Execution Containersまわりのエコシステムとしては、Build 2026の公式ブログで以下のパートナーが言及されています。
- OpenClaw:Windows上でMicrosoft Execution Containersを活用してネイティブに動作
- NVIDIA OpenShell:Microsoft Execution Containers連携が発表
- Hermes Agent・Manus:Microsoft Execution Containersとの統合予定として言及
- OpenAI:Microsoft Execution Containers関連の探索・協力の文脈で言及
Windows端末でのエージェント実行シナリオ
エージェントの実行環境をWindows端末側に持つことで、業務担当者の手元のPC上で、特定の業務に特化したエージェントを動かす運用が可能になります。
たとえば営業担当者が顧客対応中に、提案資料の参照や要約をエージェントに任せるといった構成が、クラウドへの依存を抑えた形で組めるようになります。
OpenClaw on Windowsのデモ 引用:Microsoft Build 2026
OpenClawの詳細な仕様や利用手順は、Build 2026のWindows Developer Blogおよび各パートナーの公式ドキュメントをご参照ください。
Microsoft Execution Containersとサンドボックス実行
Microsoft Execution Containersは、AIエージェントの実行をポリシー駆動で隔離・制御するための実行層として示された早期プレビュー技術です。
Microsoftの公式ブログでは、ポリシーを開発者がアプリケーション側で定義し、Windows側が実行時にそのポリシーを参照する設計が紹介されています。microsoft/mxcでは、現時点のプロファイルを正式なセキュリティ境界として扱うには注意が必要であると明記されています。
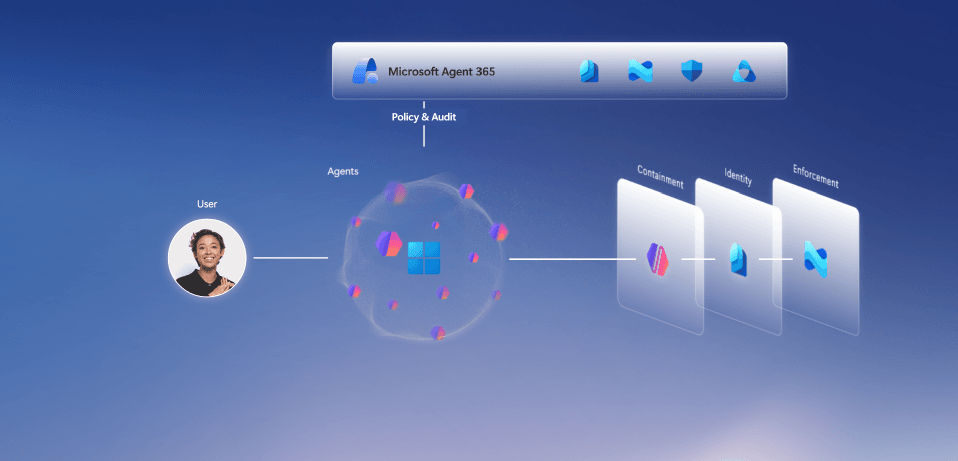
Windowsをエージェント実行基盤とする構図 引用:Windows Developer Blog
エージェントが利用するファイルやネットワークドメインに対するアクセスを、ポリシーに基づいて制御するための仕組みです。プロンプトインジェクションを介してエージェントが意図しないファイル操作を行うようなケースを抑制することを想定していますが、現時点では本番運用での厳密なセキュリティ境界としてはなく、設計検討のための早期プレビューとして扱う必要があります。
Windowsセキュリティスタックとの統合
Build 2026では、Microsoft Execution Containersと既存のWindowsセキュリティスタックとの統合方針も発表されました。
Microsoft Defender / Microsoft Entra / Microsoft Intune / Microsoft Purviewによる保護を、エージェントの実行制約として継承できる構成が示されており、2026年7月にプレビューとして提供される予定です。
- Microsoft Defender:プロンプトインジェクションをはじめとするエージェント特有の脅威に対するリアルタイム保護が提供される予定です。
- Microsoft Entra / Microsoft Intune:Agent 365のポリシーベース制御と連携し、組織ポリシーをMicrosoft Execution Containersの制約として適用する仕組みが提供される予定です。デバイス管理側で設定されたポリシーが、そのままエージェントの実行制約として効くため、IT管理者がエージェント単位の権限を個別に設計する負担を軽減することを狙いとしています。
- Microsoft Purview:データ分類・機密ラベル管理をエージェントの実行制約に反映する保護も、同じプレビューの一環として案内されています。
また、ローカル端末とは別に、Agent 365配下の管理対象Cloud PCでエージェントを分離実行する選択肢として、Windows 365 for Agentsも一般提供されています。
Foundry LocalやWindows AI APIsが端末・エッジ側の実行基盤であるのに対し、Windows 365 for Agentsはクラウド上のWindows環境でエージェントを安全に動かす補完的な選択肢です。
Azure Container Apps Sandboxes
クラウド側の対応物として、Azure Container Apps Sandboxesが同時に発表されました。
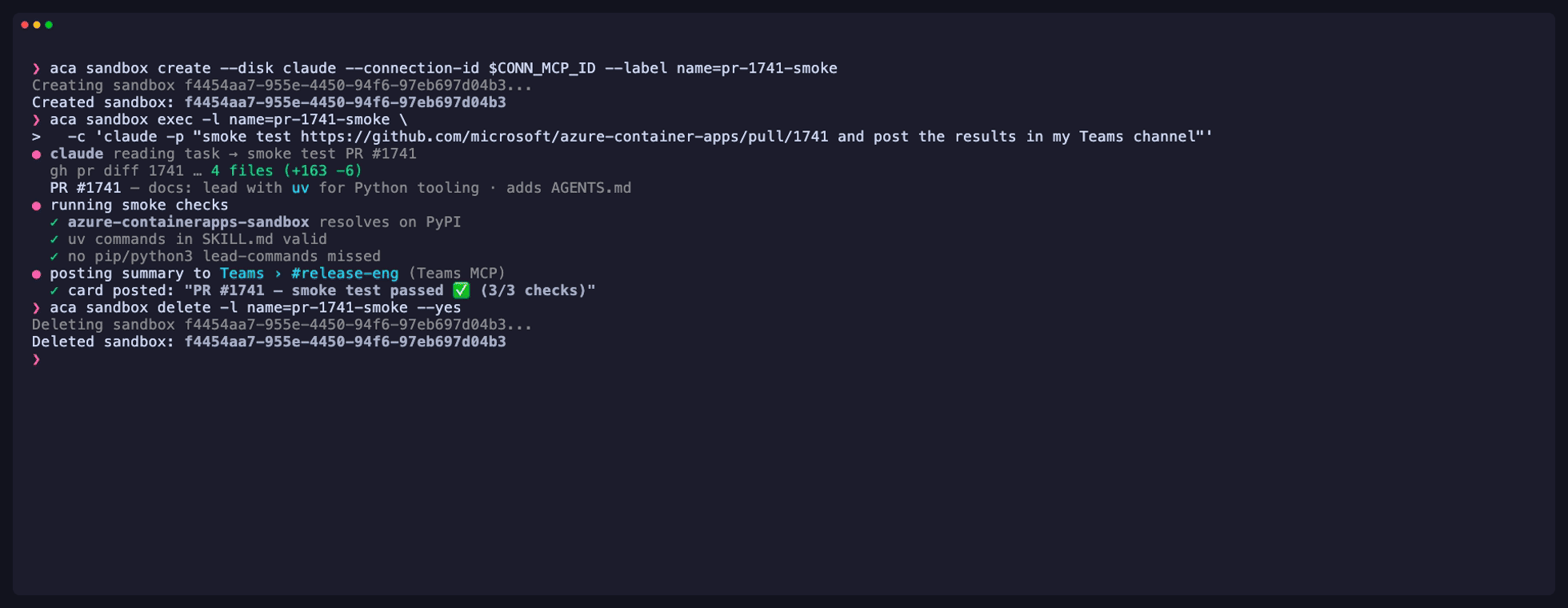
Azure Container Apps Sandboxesの動作図 引用:Microsoft Community Hub
Azure Container Apps Sandboxesは、Build 2026で発表されたエージェント向けのクラウド側サンドボックス基盤で、2026年6月2日にパブリックプレビューが公開されました。Microsoftは、端末側のMicrosoft Execution Containers(early preview)と、クラウド側のAzure Container Apps Sandboxes(public preview)の両方を、エージェント実行における主要なサンドボックス基盤の選択肢として示しています。
エージェントが端末側のリソースに触れる処理は端末側のサンドボックスで、外部APIを呼び出す処理やデータ集計はクラウド側のサンドボックスで実行する、といった役割分担が組めるようになっています。Microsoft Execution Containersの詳細な仕様や個別のユースケースは、Build 2026のWindows Developer Blogで公開されています。
3層 inference routingでのモデル振り分け
Build 2026で示されたローカルAI戦略の中で、実装パターンとして特に参考にしやすいのが、3層 inference routingと呼ばれるアーキテクチャです。
これは、ユーザーからの要求をオンデバイス、オンプレミス、クラウドの順にルーティングし、それぞれの層で適切な規模のモデルが処理する仕組みです。
67%・70%削減の数値背景
Microsoft Buildのセッション「Stop routing docstrings to 70B models with on-device AI on Snapdragon」(BRKSP90)で紹介された事例として、この3層構成を採用することで、クラウドトークン消費を約67%削減、レイテンシを約70%削減できるという参考値が説明されています。
背景にあるのは、コードコメントの生成のような軽量タスクのためにクラウド上の70Bクラスのモデルを呼び出すコストの高さです。これらはBRKSP90セッション内で示された一例であり、実際の効果はワークロード・モデル・ネットワーク条件により変動しますが、要求の複雑さに応じてモデル規模を振り分けることで、コストとレイテンシの両方を抑える設計が可能になります。
3層のモデル規模と振り分けパターン
3層 inference routingにおけるモデル規模と実行場所の対応は、以下の表のとおりです。
層 | モデル規模 | 主な処理内容 | 実行場所 |
|---|---|---|---|
on-device | 〜13B | コード補完、要約、定型応答、軽い分類 | Windows端末、Foundry Local |
on-prem | 14B〜34B | 中規模の推論、社内データを使う処理 | オンプレミスサーバー |
cloud | 70B+ | 複雑な推論、長文生成、高難度タスク | Microsoft Foundry |
この表からわかるとおり、層が上がるほどモデル規模が大きく、扱える処理の難度も上がる構造になっています。
一方でコストとレイテンシも層が上がるほど大きくなるため、要求ごとに最小限の層で済ませることが、3層 inference routingの中心的な考え方です。
この振り分けの中核として、BRKSP90ではタスクの複雑さを判定するclassifierの考え方が示されています。要求内容を軽量・中規模・複雑な処理に分類し、軽量な処理はon-device層、より大きな処理はon-premまたはcloud層へ送る設計です。セッションでは、量子化によって端末側で扱えるモデルの範囲を広げることや、判定を誤った場合に再分類・クラウド送信へフォールバックする考え方も説明されています。
採用判断と新規導入の進め方
実務でこの3層構成を採用するかを判断する際は、業務全体の中で軽量タスクが占める割合がどの程度かを見極めることが重要です。
コーディング支援や定型業務支援のように軽量タスクの比率が高い業務であれば、3層 inference routingの導入で削減効果が大きく出る傾向があります。逆に複雑な推論や長文生成が中心の業務では、層を分けずにクラウド層に集約した方が運用が単純になる場合もあります。
新規導入では、業務の処理パターンをいったん計測し、軽量タスクの比率が一定以上であることを確認したうえで3層構成に移行するとよいでしょう。
マルチハードウェア最適化とAzure Cobalt 200 VMs
3層 inference routingを支えるためには、各層で適切なハードウェア上でモデルが動く必要があります。Build 2026では、特定のNPUに縛られないマルチハードウェア戦略が改めて強調されました。
ここでは、Build 2026のCPU・NPU・Arm系セッション(BRKSP90/LABSP585/BRKSP92)で取り上げられた主要ハードウェアを、横断的に比較します。
NVIDIA RTX Spark/Surface RTX Spark Dev Box/DGX Station for WindowsといったNVIDIA系ハードウェアは、本特集のWindowsとNVIDIAで進むPhysical AIで詳しくご紹介します。
ハードウェア | 主な特徴 | 想定する層 |
|---|---|---|
Qualcomm Snapdragon X2 Elite | 80 TOPSのNPUを搭載し、エンタープライズ用途のオンデバイスエージェント向け | on-device |
AMD Ryzen AI MAX+ | フルローカルでのファインチューニング、ローカルでのコーディングモデル実行に対応 | on-device |
Intel Xeon + OpenVINO | CPU・GPU・NPU横断のプロファイリング、大規模エージェントオーケストレーションに対応 | on-prem、cloud |
Azure Cobalt 200 VMs(Arm CPU) | クラウド側のArm CPU基盤、スケールアウト型agenticワークロード向け | cloud |
この表からわかるとおり、Microsoftは特定のシリコンベンダーに依存しない選択肢を意図的に揃えています。Build 2026では、こうしたハードウェア別の実装・検証に関する関連セッションが用意されました。
- Snapdragon X2 Elite:Stop routing docstrings to 70B models with on-device AI on Snapdragon(BRKSP90)
- AMD Ryzen AI MAX+:Reinforcement learning and local models on AMD Ryzen AI MAX+ with Unsloth(LABSP585)
- Intel Xeon + OpenVINO:Scale agentic AI from on-device to cloud orchestration(BRKSP92)
なお、Arm側の性能分析には、Build 2026のODSP900セッションで扱われたArm Performixが用いられており、Azure Cobalt 200上のチューニング文脈で参照されます。
半導体製造装置や電子部品、FA制御系のように、現場端末のハードウェア構成が顧客ごとに決まる業務では、この設計思想が直接的な利点となります。現場PCがSnapdragon、AMD、Intelのいずれであっても、同じFoundry Localの仕組みでローカルAIを動かせる状況が整いつつあります。
新規導入においては、対象端末のハードウェア構成を踏まえたうえで、Foundry Localのモデルダウンロード時に自動選択される実行プロバイダーが想定のハードウェアを掴むかを確認するとよいでしょう。NPUドライバーが入っていない端末では、CPUにフォールバックされるため、想定の性能が出ない場合があります。
Azure Cobalt 200 VMs
クラウド側でも、Build 2026でAzure Cobalt 200 VMsがEarly Access Previewとして発表されました。Azure Cobalt 200は、Microsoftが内製する次世代のArm CPUで、132コアを搭載しTSMC 3nmプロセスで製造されています。
Azure Cobalt 200を採用したVMは、前世代のCobalt 100と比べて、VM基盤の世代差として最大50%のCPU性能向上、NVMeリモートストレージIOPSの20%向上、NVMeリモートストレージスループットの10%向上、ネットワーク帯域幅の15%向上が示されています。加えて、実際のクラウドワークロード別には以下のような性能改善も示されています。
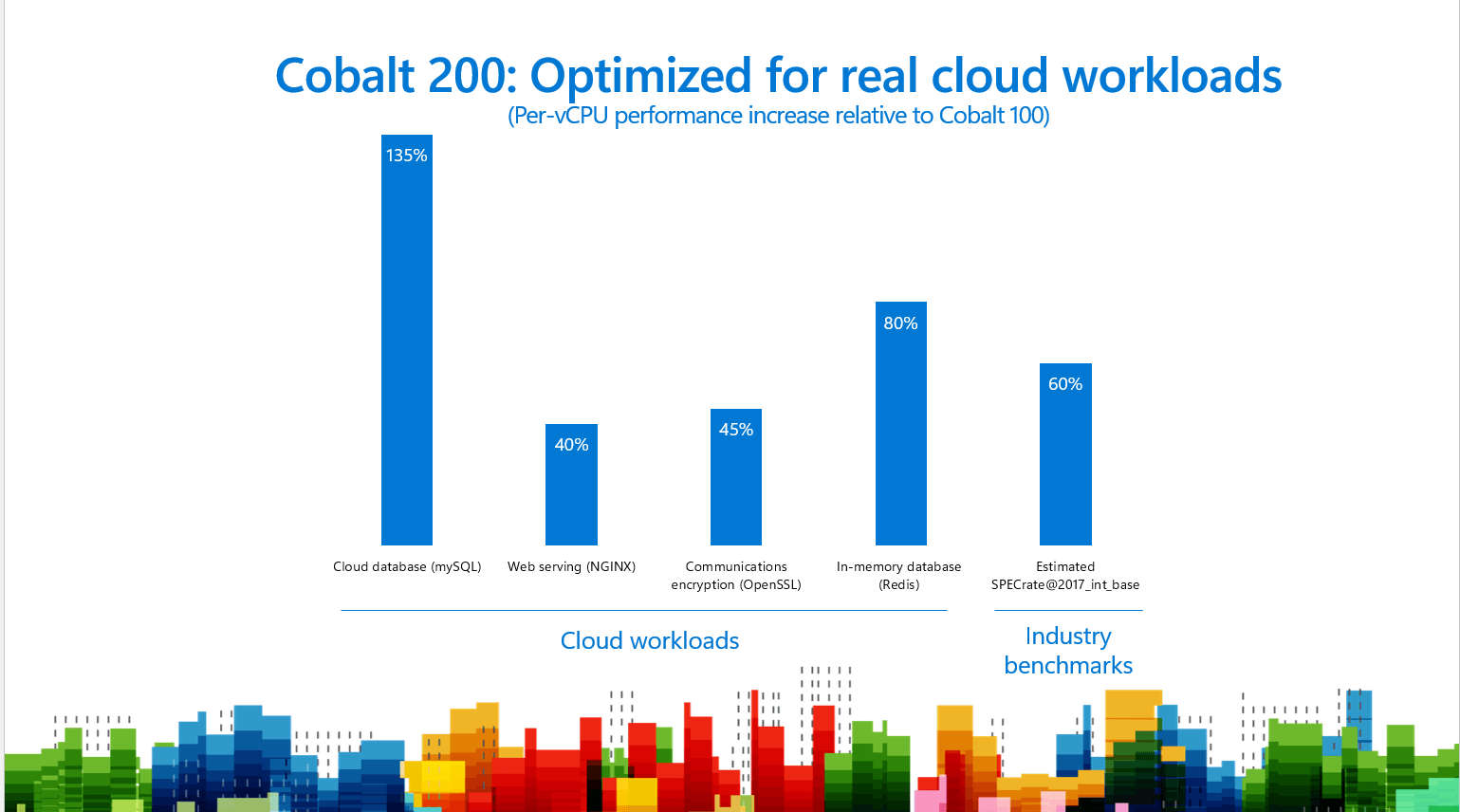
Azure Cobalt 200のクラウドワークロード別性能比較 引用:Microsoft Azure Blog
項目 | Cobalt 200の改善幅(対 Cobalt 100) |
|---|---|
クラウドデータベース(MySQL) | 最大135%向上 |
Web serving(NGINX) | 最大40%向上 |
通信暗号化(OpenSSL) | 最大45%向上 |
インメモリデータベース(Redis) | 最大80%向上 |
業界ベンチマーク(推定SPECrate 2017_int_base) | 最大60%向上 |
Azure Cobalt 200 VMsは最大128 vCPUまでスケールし、スケールアウト型・クラウドネイティブ・Linuxベースのagentic AIワークロード向けのクラウド側CPU/VM基盤として位置づけられます。Build 2026時点ではEarly Access Previewとして扱われるため、本番利用時は提供リージョンや利用条件の確認が必要です。エージェントのオーケストレーションやデータ処理、業務ロジックの実行を担う層に向いた選択肢です。
なお、AI推論そのものは別軸のAIアクセラレータが担う領域で、MicrosoftはMaia 200を自社開発の推論向けAIアクセラレータとして展開しています。Cobalt 200はCPU/VM基盤、Maia 200はAI推論アクセラレータと役割が分かれます。
Build 2026で示された全体像としては、端末側のSnapdragon・AMD・Intelといったオンデバイス向けハードウェアと、クラウド側のCobalt 200(CPU/VM基盤)およびMaia 200(AI推論アクセラレータ)が、Microsoft FoundryとFoundry Localを支えるクラウド側・端末側の選択肢として役割分担する構図になっています。
クラウドとローカルのハードウェアをワークロードに応じて使い分けられる点が、運用設計の負担を抑えるうえで重要な意味を持ちます。
業務に合わせたAI実行基盤の選び方
ここまでご紹介した内容を踏まえて、ローカルAI実行基盤を業務に組み込む際の選定ポイントを整理します。
実行場所を決める3つの確認事項
実行場所を決める際は、次の3つを順に確認するとよいでしょう。
- 業務単位で実行場所を決める:機密データの所在、許容レイテンシ、想定モデル規模の3つの軸で、業務ごとに、本記事で整理したクラウド、オンプレミス、現場エッジ、Windows端末のいずれが適しているかを判定します。
- 既存のFoundry系コンポーネントとマッピングする:各業務に対して、Foundry Local(Windows端末)、Foundry Local on Azure Local(オンプレミス/現場エッジ)、Foundry Agent Service(クラウドエージェント)、Microsoft Foundry(モデル基盤)のどれが必要かを割り当てます。
- 段階的にロールアウトする:まずは1業務に対して1つの実行場所で検証し、効果を測定したうえで横展開を進めます。
業界別の実装シナリオ
業界別の実装シナリオの例としては、以下のようなものが考えられます。
- 半導体製造装置:工場現場PCでの検査支援や異常ログの一次分析をオンデバイスで行う構成です。画像・センサーデータの判定には用途に応じたローカル推論モデルを用い、Aion 1.0系モデルは作業手順の要約、異常内容の説明、次アクションの計画などのテキスト・エージェント処理で活用する構成が考えられます。
- 電子部品:検査ライン端末でリアルタイムに判定する構成です。Windows AI APIsのSpeech Recognition APIやVideo Super Resolutionを併用することで、検査オペレーターの作業を支援できます。
- FA・制御系:現場PLC連携端末での即時推論が中心となる構成です。現場エッジではオンプレミスのArm機や既存エッジサーバーを活用し、クラウド側の処理ではAzure Cobalt 200 VMsを組み合わせるパターンが選択肢となります。
複数業務へ広げる際のポイント
実務での選定にあたっては、すべての業務をクラウドだけ、またはローカルだけで揃えるのではなく、業務単位で実行場所を組み合わせます。コスト、レイテンシ、データガバナンスの3つを同時に満たすには、本記事で整理した4つの実行場所を業務ごとに使い分けることが重要です。
新規導入では、まずFoundry Localによる端末側の検証から開始し、軽量タスクでの効果を確認したうえで、クラウド側との3層 inference routing構成に拡張していく進め方を推奨します。最初からマルチ層構成を組むよりも、1層ずつ確実に運用に乗せていく方が、想定外のコストや運用負担を避けやすくなります。
まとめ
本記事では、Microsoft Build 2026で発表されたFoundry LocalとローカルAI実行基盤の動向について、運用上整理した4つの実行場所の比較、Foundry Local自体の強化点、Windows AI APIs・OpenClaw・Microsoft Execution Containers・3層 inference routing・マルチハードウェア最適化までを解説しました。
Foundry Localは、Microsoftが提供するオンデバイス推論基盤として、Build 2026で大きく強化されました。あわせて、Windows向けオンデバイスSLMであるAion 1.0 InstructとAion 1.0 Planが発表され、Windows端末側で完結するテキスト処理やエージェントワークフローを実現しやすくなっています。さらにWindows AI APIs、OpenClaw on Windows、Microsoft Execution Containersといった発表により、Windowsをエージェント実行基盤として活用するための土台が整いました。
Microsoftの各公式資料では、クラウド上のMicrosoft Foundry、ユーザーデバイス上のFoundry Local、オンプレミスや分散環境向けのFoundry Local on Azure Localなど、複数の実行環境が説明されています。本記事では、これらを実務上の比較軸として、クラウド、オンプレミス、現場エッジ、Windows端末の4つに分けて整理しました。
また、後半ではBRKSP90で紹介された実装パターンとして、要求内容に応じて推論先を振り分ける3層 inference routingを取り上げました。これにより、クラウドトークン消費の削減とレイテンシ短縮を図る考え方が示されています。ハードウェア側ではSnapdragon・AMD・Intel・Arm横断で最適化が進み、クラウド側ではEarly Access PreviewのAzure Cobalt 200 VMsが新たな選択肢として加わっています。
東京エレクトロンデバイスでは、Foundry LocalやMicrosoft Foundryを活用したローカル・クラウド統合AI基盤の構築を総合的にサポートしています。業務特性に合わせた実行場所の選定、エッジ・端末側のハードウェア選定、PoCから本番展開までの導入支援など、ローカルAI実行基盤に関するご相談をお受けしています。



