
Foundry Localとは?
Foundry Localとは、Microsoftが提供するオンデバイス推論ソリューションです。AIモデルを開発者のPCやローカル環境で実行でき、CLI、SDK、ローカルREST API を通じて、検証からアプリケーションへの組み込みまで行えます。
Azureサブスクリプションなしで始められるため、まずローカル推論を試したい場合にも導入しやすい構成です。
ただし、Foundry Localの価値は、単に「ローカルでAIを動かせる」ことだけではありません。中核にはONNX Runtimeがあり、その上にモデルの実行、ハードウェア最適化、OpenAI互換のローカルRESTサーバー、SDKなどをまとめて提供することで、オンデバイス推論を扱いやすくしています。
クラウド型のAIサービスでは、推論のたびにネットワーク接続やデータ送信が前提になるケースがあります。一方、Foundry Localはローカルで推論処理を完結できるため、機密データを外部へ送らずにAI機能を活用しやすく、低レイテンシやオフライン動作といった利点も得やすくなります。
こうした実用性を支えているのが、後述するONNX Runtimeです。
Foundry Localを支えるONNX Runtimeとは?
ONNX Runtimeとは、ONNX形式のモデルを効率よく実行するための推論ランタイムです。CPU、GPU、NPUなど異なる計算資源に対して共通の実行基盤を提供できる点が特徴で、同じモデルをさまざまなデバイス上で動かしやすくします。
Foundry Localでは、このONNX Runtimeを中核に採用することで、開発者がハードウェアごとの差分を強く意識せずにローカル推論を扱えるようにしています。
つまり、Foundry Localは単なるCLIツールではなく、ONNX Runtimeをベースに、モデル実行やアプリ組み込みを開発者が扱いやすい形にまとめた仕組みと捉えると分かりやすいでしょう。
ONNX Runtimeの有効性は、主に次の3点にあります。
- 実行先のハードウェアに応じて、最適なバックエンドを選びやすい
- CPUのみの環境からGPU/NPU搭載端末まで、同じ推論基盤で展開しやすい
- 量子化モデルを含むローカル実行向けの最適化と相性がよく、オンデバイスAIを実装する際の運用負荷を下げやすい点
Foundry Localは、こうしたONNX Runtimeの利点を、モデル実行やアプリ組み込みまで開発者が扱いやすい形にまとめている点に特徴があります。
Foundry Localの主な機能
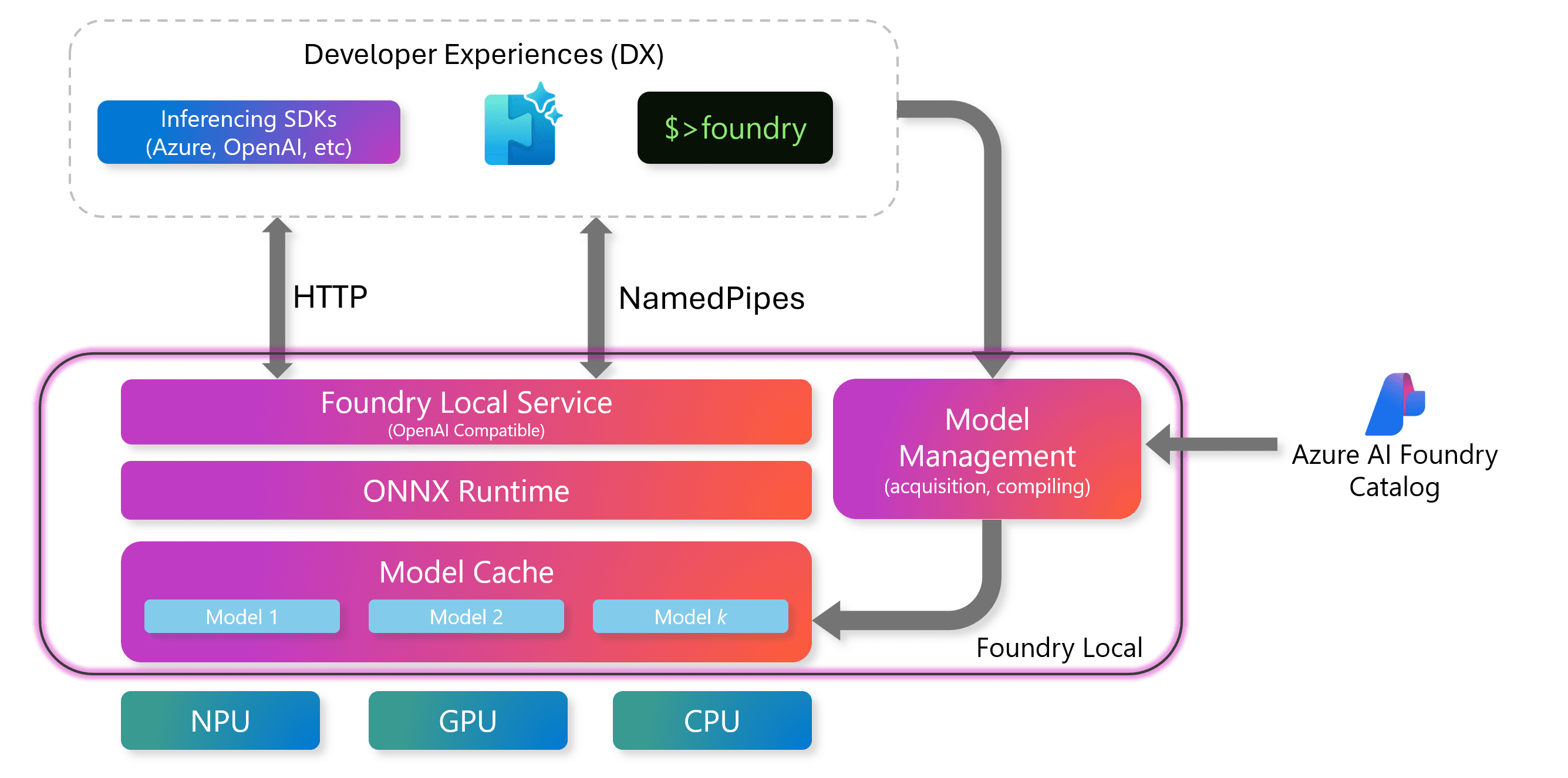
Foundry Localの主要コンポーネント
このセクションでは、Foundry Localが提供する機能についてご説明します。
オンデバイス推論機能
Foundry Localの中核となる機能は、AIモデルをローカルデバイス上で実行するオンデバイス推論です。この機能により、以下のような利点が得られます。
- データプライバシーの確保:プロンプトと出力がすべてローカルで処理され、クラウドへデータが送信されません。
- 低レイテンシ:ネットワーク遅延がなく、リアルタイムに近い応答速度を実現します。
- オフライン動作:AIモデルのダウンロード後はインターネット接続なしで動作可能です。
- コスト削減:クラウドの従量課金が発生せず、既存ハードウェアを活用できます。
複数のインターフェース対応
Foundry Localは、開発者の用途に応じて3つのインターフェースを提供しています。
CLI(コマンドラインインターフェース)
CLIは、ターミナルから直接操作できるインターフェースです。foundry model runコマンドを実行するだけで、対話形式でAIモデルを試すことができます。
初めてFoundry Localを使用する開発者が、手軽にモデルの動作を確認する際に適しています。
SDK(ソフトウェア開発キット)
SDKは、Python、JavaScript、C#、Rustに対応しており、アプリケーションへの組み込みが容易です。
特にPython SDKはpip install foundry-local-sdkコマンドでインストールでき、数行のコードでAI機能をアプリケーションに統合できます。
REST API
Foundry Localは、OpenAI互換のローカルRESTサーバーを通じて、既存アプリケーションと連携できます。既存のOpenAI SDKを使っているアプリであれば、接続先のURLをローカル環境に切り替えることで、Foundry Localをバックエンドとして利用しやすくなります。
また、このローカルRESTサーバーは、CLIとは別にFoundry Local Serviceとして動作するため、アプリケーション側からHTTP経由でモデルを呼び出せます。ローカル推論向けにエンドポイントやモデル管理を扱える点が、単なるSDK呼び出しとの差分です。
事前最適化済みモデルカタログ
Foundry Localには、複数のAIモデルが事前に最適化された状態で用意されています。
以下に、主な対応モデルを示します。
モデル | 提供元 |
Phi-4 | Microsoft |
GPT-OSS | OpenAI |
Qwen2.5 | Alibaba |
これらのモデルは、実行するハードウェアに応じてCPU版、GPU版、NPU(Neural Processing Unit:AI処理専用チップ)版が自動的に選択されます。
利用可能なモデルとパラメータサイズの一覧は、Foundry Local公式サイトをご確認ください。
幅広いハードウェア対応
Foundry Localが幅広いハードウェアに対応できる理由は、ONNX Runtimeの実行基盤を活用しているためです。
一般的に、ローカル推論ではCPU、GPU、NPUごとに利用できる実行方式や最適化手法が異なりますが、Foundry Localではその違いをある程度吸収し、開発者が統一的に扱いやすい形にまとめています。
この仕組みの中心にあるのが、Execution Providerです。Execution Providerとは、CUDA、QNN、OpenVINO、WebGPUなど、各ハードウェア向けの実行バックエンドを指します。Foundry Localは、実行環境に応じて適切なExecution Providerを利用し、GPUやNPUが利用可能な場合はそれらを活用しつつ、必要に応じてCPUへフォールバックします。
以下に、Foundry Localが幅広いハードウェアに対応できる背景を整理します。
項目 | 内容 |
|---|---|
共通実行基盤 | ONNX Runtimeを中核に、CPU/GPU/NPUをまたいで推論を実行できる |
実行バックエンド | CUDA、QNN、OpenVINO、WebGPUなどのExecution Providerを利用できる |
Foundry Localの役割 | 実行環境に応じたExecution Providerの利用や管理を開発者が扱いやすい形にまとめている |
フォールバック | GPU/NPUが利用できない場合でも、CPU実行へ切り替えやすい |
macOS対応 | Apple Silicon環境では、WebGPU経由でMetalを活用できる |
この構成により、開発者はデバイスごとに別々の推論スタックを個別実装しなくても、同じFoundry Localの操作体系でローカル推論を扱いやすくなります。Foundry Localの「幅広いハードウェア対応」は、単に対応機種が多いという意味ではなく、ONNX Runtimeを軸に共通の推論基盤を持てることに価値があります。
外部ツールとの統合機能
Foundry Localは、既存の開発エコシステムとの統合が考慮されています。
LangChain
LangChainは、大規模言語モデル(LLM)を活用したアプリケーション開発を効率化するためのオープンソースフレームワークです。
LangChainのChatOpenAIクラスを使用して、Foundry Localのエンドポイントに接続できます。これにより、RAG(Retrieval-Augmented Generation:検索拡張型生成)システムやAIエージェントの構築にFoundry Localを活用できます。
Open Web UI
Open Web UIでは、Webブラウザ上でチャットインターフェースを利用できます。Dockerコンテナで起動したOpen Web UIから、Foundry Localのエンドポイントに接続することで、視覚的にわかりやすいインターフェースでAIモデルを操作できます。
Hugging Face
Microsoft Oliveを使用して、Hugging Faceで公開されているモデルをFoundry Local向けに最適化できます。Microsoft Oliveとは、AIモデルの圧縮や最適化を自動化し、特定のハードウェア上で効率的に動作させるためのオープンソースツールです。
公式カタログに含まれていないモデルを使用したい場合に有効な機能です。
Foundry Localの料金
2026年2月時点で、Foundry Localはローカル端末上でモデル推論を行う用途なら、Azureサブスクリプションを必要とせず、サインアップなしで開始できます。ローカル推論そのものはクラウドの従量課金を前提としないため、検証やプロトタイピングを始めやすい構成です。
一方で、端末側のハードウェア(GPU/NPU)・電力・保守などの運用コストは別途発生します。
また、利用するモデルのライセンス条件はモデルごとに異なるため、商用利用を含む運用では事前に確認してください。加えて、Microsoft Foundry(クラウド側)の機能を利用する場合は、各サービスの通常レートに基づく課金が発生します。
最新の情報は、Foundry Local公式ドキュメントをご覧ください。
Foundry Localの利用手順
それでは、実際にFoundry Localの導入から基本的な操作までの手順をご説明します。
インストール
Windowsの場合
Windowsでは、PowerShellまたはWindowsターミナルで以下のコマンドを実行します。
winget install Microsoft.FoundryLocal
インストールが完了したら、ターミナルを再起動して以下のコマンドを入力し、正常にインストールされたか確認します。
foundry --version
macOSの場合
macOSでは、Homebrewを使用したインストールが推奨されます。ターミナルで以下のコマンドを順に実行します。
```bash
brew tap microsoft/foundrylocal
```
```bash
brew install foundrylocal
```
初期動作確認
インストール後、基本的な動作を確認します。以下に初期設定用の基本的なコマンドを示します。
```bash
foundry --help
```
利用可能なCLIコマンドの一覧を表示します。
```bash
foundry model list
```
利用可能なモデルの一覧を表示します。初回実行時には、ハードウェア構成に応じた実行プロバイダーが自動的にダウンロードされます。
```bash
foundry model run <model-name>
```
モデルをダウンロードし、対話形式のプロンプトを開始します。プロンプトが表示されたら、任意のテキストを入力してEnterキーを押すことで、AIの応答を確認できます。
AIの応答の確認
上記のステップで、Foundry Localを利用し、AIモデルをオンデバイスで推論させることが可能です。次のセクションでは、より実践的な活用方法を解説します。
Foundry Localの活用デモ
ここではSDKを活用し、アプリケーションにFoundry Localを組み込む場合の基本的なPythonコードを示します。
まず、以下のコマンドで必要なパッケージをインストールします。
pip install foundry-local-sdk openai
次に、以下のコードでFoundry Localを利用します。
from foundry_local import FoundryLocalManager
import openai
# Foundry Localの初期化とモデルの準備
manager = FoundryLocalManager("Phi-4")
# OpenAI互換クライアントの作成
# ローカルサーバーが起動している前提、もしくはManager経由で制御
client = openai.OpenAI(
base_url="http://localhost:11434/v1",
api_key="local" # ローカル実行のためダミー値で動作
)
# チャット完了リクエストの送信
response = client.chat.completions.create(
model="Phi-4",
messages=[
{"role": "user", "content": "Pythonでリストをソートする方法を教えてください"}
]
)
print(response.choices[0].message.content)
コードの実行結果の確認
このコードは、Foundry LocalをバックエンドとしてOpenAI互換のAPIでAIモデルを呼び出しています。既存のOpenAI SDKを使用したアプリケーションがあれば、base_urlを変更するだけでFoundry Localに簡単に移行できます。
より詳細な実装例や他言語でのコード例は、Foundry Local公式リポジトリをご覧ください。
Foundry Localの使い方のコツ
このセクションでは、Foundry Localを効果的に活用するためのコツをご説明します。
ハードウェアアクセラレーションの活用
GPUやNPUを搭載している場合は、対応するドライバーをインストールすることで、推論速度が向上します。
- NVIDIA GPUの場合、CUDAドライバーがインストールされていれば、Foundry Localが自動的にGPU最適化版のモデルをダウンロードします。
- NPUを使用する場合は、NPUドライバーを別途インストールする必要があります。ドライバーインストール後、Foundry LocalがNPUを自動検出します。
ドライバーのインストール状況に関わらず、以下のコマンドでデバイス別のモデルを確認できます。
foundry model list --filter device=GPU
foundry model list --filter device=NPU
キャッシュの管理
ダウンロード済みのモデルはローカルにキャッシュされます。ディスク容量を管理するため、不要なモデルは削除することを推奨します。
# キャッシュ済みモデルの一覧を表示
foundry cache list
# 特定のモデルをキャッシュから削除
foundry cache remove <model-name>
ライセンスの確認
各モデルには固有のライセンス条件があります。商用利用を検討する場合は、事前にライセンスを確認してください。
foundry model info <model-name> --license
MITライセンスのモデル(Phiシリーズなど)は商用利用が許可されていますが、モデルによっては制限がある場合があります。
Foundry Localの活用シーン
Foundry Localは、特に以下のようなシーンでの活用が期待されています。
機密情報を扱うプロジェクトの検証
金融機関や医療機関など、データプライバシーの要件が非常に厳しい業界では、データをクラウドへアップロードすることがハードルとなる場合があります。Foundry Localを利用すれば、ネットワークから遮断されたローカル環境でPoC(概念実証)を実施し、安全性を確認してから本番環境の設計に移ることができます。
エッジデバイスへのAI組み込み
工場の生産ラインにおける外観検査や、通信環境が不安定な現場での作業支援アシスタントなど、エッジデバイス上でAIを動作させる必要があるケースです。Foundry Localはハードウェアアクセラレーションを活用し、限られたリソースでも効率的に推論を実行できます。
開発コストの最適化
開発初期段階において、頻繁にプロンプトの修正やモデルの挙動確認を行う際、クラウドの従量課金APIを使用しているとコストが積み上がることがあります。Foundry Localで開発・テストを行い、本番展開時のみAzure OpenAI Serviceなどのクラウドサービスを利用することで、全体のコストを抑制できます。
Foundry Local利用時の注意点
このセクションでは、Foundry Localを導入・運用する際の注意点についてご説明します。
プレビュー版としての制約
Foundry Localは、2026年2月時点でパブリックプレビューとして提供されています。
正式リリースまでに機能やプロセスが変更される可能性があるため、本番環境への導入を検討する場合は、プレビュー版であることを考慮し、公式ドキュメントで最新情報を確認することを推奨します。
ハードウェアリソースへの依存
Foundry Localのパフォーマンスは、実行するハードウェアに依存します。
メモリ不足の場合、大規模なモデルを実行しようとするとメモリ不足エラーが発生することがあります。システムメモリが8GB以下の環境では、軽量なモデル(0.5B〜1.5B程度のパラメータ規模)の使用を推奨します。
GPU/NPUなしの環境では、CPU上でモデルを実行できますが、処理速度が低下します。特にリアルタイム性が求められるアプリケーションでは、アクセラレーションハードウェアの導入を検討しましょう。
セキュリティの考慮事項
ローカル実行であっても、セキュリティ対策は必要です。マルチユーザー環境でFoundry Localサービスを公開する場合は、適切なアクセス制御を設定しましょう。
また、ファインチューニング済みのモデルや機密データを含むキャッシュを保存するデバイスでは、ディスク暗号化の適用を推奨します。
まとめ
Foundry Localは、Azureサブスクリプション不要で手軽にローカルAI推論を始められる強力なツールです。プライバシー保護、オフライン対応、コスト削減といったメリットを活かし、開発者のPCやエッジデバイス上で高度なAI機能を実現します。まずはCLIから手軽に試し、慣れてきたらSDKやREST APIを使ってアプリケーションに組み込んでみるのがおすすめです。
東京エレクトロンデバイスは、Azure導入支援からAI活用、エッジコンピューティングまでをワンストップでサポートしています。
ご興味のある方はこちらからお問い合わせください。



