
Microsoft Fabric の Data Factory とは
Microsoft Fabric の Data Factory は、Microsoft Fabric の一部としてデータの収集、統合、変換、移動を行うための機能を備えています。
従来の Azure Data Factory の機能を活用しつつ、Microsoft Fabric の統合プラットフォームの一環として提供されるため、Lakehouse アーキテクチャとの親和性が高く、Microsoft Fabric 内の他のサービスとのシームレスな連携が可能です。
【主な特徴】
- ノーコード/ローコードでのデータパイプライン構築:視覚的なデザイナーを利用して、データ処理のワークフローを直感的に作成可能です。
- Microsoft Fabric エコシステムとの統合:OneLake を活用したデータの統一管理や、Power BI とのスムーズな連携が可能です。
- クラウドネイティブなアーキテクチャ:クラウド環境でのスケーラブルなデータ統合が実現できます。
【関連記事】
OneLake とは?統合データレイクで実現する次世代データ分析基盤を解説
Microsoft Fabric とは
Microsoft Fabric の Data Factory は、Microsoft Fabric のサービスの一部として提供されていますが、Microsoft Fabric とはそもそもどのようなサービスでしょうか。
Microsoft Fabric は、Microsoft が提供する クラウドベースの統合データ分析プラットフォームです。主に以下のサービスで構成され、それぞれのデータ処理ニーズに応じた機能を提供しています。
| ワークロード | 説明 |
|---|---|
OneLake | 組織全体でデータを統合・管理するデータレイク |
Data Factory | データの収集・統合・変換を行う ETL/ELT ツール |
Data Engineering | Apache Spark ベースで大規模データ処理 |
Data Science | AI/ML モデルの開発と実装を支援 |
Data Warehouse | 高性能なデータウェアハウス機能(T-SQL 対応) |
Real-Time Analytics | ストリーミングデータのリアルタイム分析 |
Power BI | 直感的なデータ可視化・レポート作成 |
SQL Database | フルマネージドなリレーショナルデータベースサービス(T-SQL 対応) |
【関連ページ】
Microsoft Fabric の Data Factory のデータ処理の流れ
Microsoft Fabric の Data Factory では、データの取り込み (Ingestion)、変換 (Transform)、オーケストレーション & 通知 (Orchestrate & Notification)、保存 (Store) の 4 つのステップを通じて、データを統合・処理します。以下の図の流れに沿って、それぞれの役割を説明します。
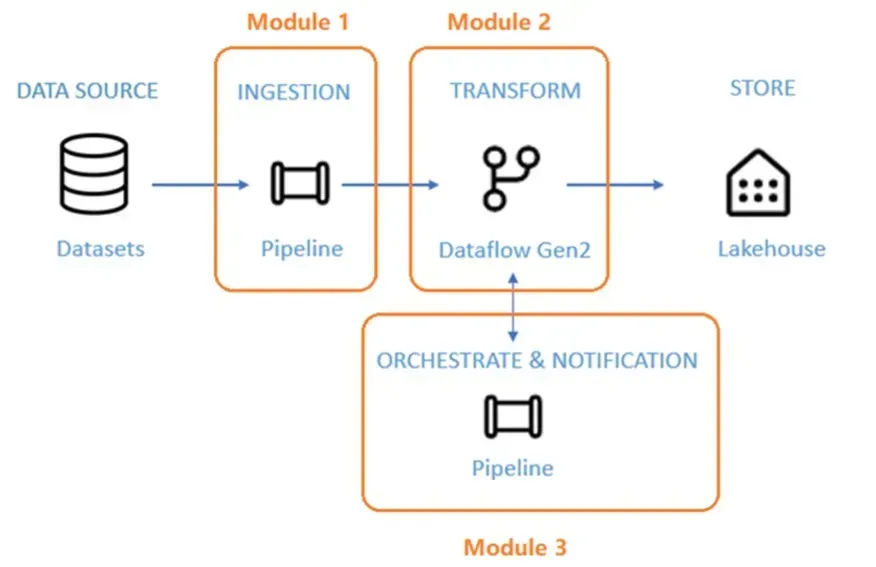
データ処理の流れイメージ(参考:Microsoft)
1. データソース(DATA SOURCE)
データの元となる データセット(Datasets) を指し、クラウド、オンプレミス、SaaS アプリケーション、データベースなど、多様なデータソースからデータを取得できます。これらのデータは Ingestion(データ取り込み) のプロセスに送られます。
2. データの取り込み(INGESTION - Module 1)
データソースからのデータを Microsoft Fabric に取り込む工程です。
- Pipeline を使用して、異なるデータフォーマットのデータを収集・統合
- OneLake への格納を前提としたデータ転送 を行う
取り込まれたデータは、次の Transform(変換) のプロセスへ送られます。
3. データの変換(TRANSFORM - Module 2)
取り込んだデータは、そのままでは分析に適した形式ではないことが多いため、Dataflow Gen2 を活用してクレンジング・変換を行います。
- Dataflow Gen2 は、Power Query を基盤としたデータ変換ツール
- GUI ベースで ETL/ELT 処理が可能 で、データを整理・統合
- OneLake とのシームレスな連携 により、Microsoft Fabric のデータストレージを最大限活用
変換されたデータは、Lakehouse への保存 へ送られます。
4. データの保存(STORE)
処理済みデータは Lakehouse に保存され、以降の分析や可視化のために活用されます。
- Microsoft Fabric の OneLake を活用し、統一されたデータ管理を実現
- Power BI や Microsoft Fabric の他のサービスとシームレスに連携 可能
- Lakehouse に格納されたデータは、そのまま Power BI で可視化や、AI/ML モデルに活用可能
5. オーケストレーション & 通知(ORCHESTRATE & NOTIFICATION - Module 3)
データの流れをスムーズに管理するために、パイプラインの オーケストレーションや通知機能 を活用できます。
- Pipeline によるワークフロー管理 (タスクの自動実行、エラーハンドリング)
- スケジューリング機能(定期的なデータ更新を自動化)
- 異常検知 & 通知機能(データ処理の失敗時にアラートを送信)
一度パイプラインを設定すれば、自動でデータ処理を管理し、定期的に監視することができるようになります。
こうしたプロセスにより、Microsoft Fabric の Data Factory は データの収集から保存、処理、管理までをシームレスに統合 できます。
Microsoft FabricのData Factory の役割
Microsoft Fabric の Data Factory は、前述のデータ処理フローの中で 「データの取り込み(INGESTION)」と「データの変換(TRANSFORM)」を中心に担う 役割を果たします。また、オーケストレーション(ORCHESTRATE & NOTIFICATION) もサポートし、データ処理の自動化を実現します。
1. データの取り込み (INGESTION)
Microsoft Fabric の Data Factory から Pipeline を利用して、外部のデータソース(クラウド、オンプレミス、SaaS など)からデータを取得し、ノーコード/ローコードで Microsoft Fabric 環境へ取り込みます。Microsoft Fabric に最適化された ETL/ELT 処理を提供し、特に OneLake との高い親和性が特徴です。
2. データの変換 (TRANSFORM)
Microsoft Fabric の Data Factory は、Dataflow Gen2(Power Query ベース)を活用して、データの変換・整理を行います。GUI ベースのデータ変換により、SQL や Python の知識がなくても、直感的にデータの整形・結合・フィルタリングを実施できます。
3. オーケストレーション & 通知(ORCHESTRATE & NOTIFICATION)
データパイプラインの実行を スケジュール管理・ワークフロー制御・異常検知・通知により自動化します。
- スケジュール設定(定期実行やイベントトリガーによる自動処理)
- エラーハンドリング & 再試行機能(異常発生時のリトライ処理)
- 通知 & アラート機能(異常時のアラート送信やレポート機能)
4. データの保存(STORE)には関与しない
Microsoft Fabric の Data Factory は OneLake / Lakehouse へデータを送る役割を担うものの、ストレージ管理そのものは Microsoft Fabric の OneLake が担当します。
また、保存後のデータ分析・可視化(Power BI など) は、Microsoft Fabric の他の機能(Real-Time Analytics, Data, Power BI)が担当します。
Azure Data Factory との違い
Microsoft Fabric の Data Factory は、もともとAzure Data Factory(ADF)の技術を基盤としているサービスですが、Microsoft Fabric のエコシステムに最適化されています。そこでここでは両者の違いについてご説明します。
Azure Data Factory とは
Azure Data Factory(ADF) は、Microsoft Azure が提供する クラウドベースのデータ統合サービス です。
異なるデータソースからデータを収集し、ETL(Extract, Transform, Load)または ELT(Extract, Load, Transform)のプロセスを実行し、Azure や他の環境にデータを転送・統合・処理 するための強力なツールです。
 Azure Data Factory イメージ(参考:Microsoft)
Azure Data Factory イメージ(参考:Microsoft)
Microsoft Fabric の Data Factory と Azure Data Factory との違い
Microsoft Fabric の Data Factory は Azure Data Factory の技術を基盤 にしているものの、Microsoft Fabric に最適化されています。 両者の違いは次のとおりです。
比較項目 | Microsoft Fabric の Data Factory | Azure Data Factory(ADF) |
|---|---|---|
提供形態 | Microsoft Fabric 内のサービス | Azure の独立したサービス |
データストレージ | OneLake を標準利用 | Azure Data Lake, Blob Storage |
データ変換 | Dataflow Gen2(Power Query ベース) | ADF Data Flow + Spark ベース |
対応データソース | Microsoft Fabric に最適化 | オンプレミス・AWS・SAP など広範囲 |
連携サービス | Power BI や OneLake と統合 | Synapse, Databricks, ML など |
ワークフロー管理 | Microsoft Fabric 内でのデータオーケストレーションに特化 | Azure 内の広範な統合・制御が可能 |
両者の活用場面の違い
Microsoft Fabric で完結するデータ分析環境は、OneLake という統一されたデータレイクと、Power BI などの分析ツールとの緊密な連携により、優れたユーザー体験を提供します。
そのため、基本的には Microsoft Fabric の Data Factory でデータ統合を完結せることができるでしょう。Microsoft Fabric のコネクタは順次増加しており、多くのユースケースをカバーできるようになっています。
Azure Data Factory は、Microsoft Fabric がまだサポートしていない特殊なデータソースとの連携が必要な場合や、既存の Azure Data Factory のワークフローがある場合に、補完的に活用することで、Microsoft Fabric の環境をさらに強化できます。
こうした補完的なアプローチにより、Microsoft Fabric の優れたデータ分析基盤を最大限に活用しながら、必要に応じて柔軟に対応することが可能です。
【関連記事】
Azure Data Factory とは?さまざまなデータの連携や統合管理をクラウドで実現
Microsoft Build 2025 で追加された Data Factory 関連の新機能
Microsoft Fabric の Data Factory に重要な新機能が追加され、データ統合、変換、管理の効率性が大幅に向上しました。
Mirroring 機能の拡張
SQL Server、Azure PostgreSQL、Cosmos DB のサポートが拡張され、リアルタイムレプリケーションと分析が可能になりました。
特に注目すべきは SQL Server 2025 への対応です。Microsoft SQL Server 2025 の発表により、このバージョンからのミラーリングも利用可能になり、SQL Server 2025 は Change Data Capture の代わりに change feed を使用します。これにより、オンプレミスからクラウドまで、幅広い SQL Server 環境からのデータ統合が可能になります。
ミラーリング機能により、複雑な ETL 設定なしで、ソースのトランザクショナル データベースを OneLake で常に最新の状態に保つことができ、レポート、高度な分析、AI、データサイエンスの強固な基盤を提供します。
Materialized Lake Views(MLV)の導入
SQL を使用した宣言的データパイプラインの構築が可能な Materialized Lake Views(MLV)がプレビューで提供されます。
MLV は、組み込みのデータ品質ルールとデータ変換の自動監視を備えた、持続的に更新されるデータビューで、メダリオンアーキテクチャと呼ばれる多段階レイクハウス処理の実装を簡素化します。
【主な特徴】
- 宣言的パイプライン構築: CREATE MATERIALIZED LAKE VIEW ステートメントを使用して、SQL だけでデータ変換パイプラインを定義可能
- 自動依存関係管理: 拡張 SQL 定義から依存関係を自動推論し、系譜ビューで視覚化
- データ品質制約: 各実行でデータ品質制約を適用・視覚化し、完了ステータスと適合性を表示
従来は各段階でカスタム Spark ジョブやノートブックを作成し、スケジューリングやオーケストレーション、データ検証の実装が必要でしたが、MLV によりこれらの複雑さが大幅に軽減されます。
OneLake Shortcut Transformations の追加
OneLake の既存ショートカット機能が拡張され、shortcut transformations という新機能がプレビューで提供されます。
この機能により、OneLake にデータを取り込む際や OneLake データアイテム間でのデータ移動時に自動的にデータ変換が可能になり、Delta Lake 形式への変換や、要約、翻訳、文書分類などの AI を活用した変換を Azure AI Foundry を使用して実行できます。
数回のクリックで OneLake 内のデータを仮想化し、分析や AI 向けに準備できるため、データエンジニアリングの効率性が大幅に向上します。
Azure DevOps クロステナント サポート
Fabric と Azure DevOps が同じテナントにある必要がなくなりました。
この機能により、異なる Microsoft テナントを使用している組織でも、既存の Azure DevOps 環境と Fabric を連携させたデータパイプラインの CI/CD が可能になります。特に、複数テナント運用や買収・合併により異なるテナント環境を持つ大企業にとって、運用の柔軟性が大幅に向上します。
Variable Libraries の拡張サポート
従来は Data Pipeline のみでサポートされていた Variable Libraries が、Notebook やショートカット、スケジューラーでもサポートされるようになりました。
この拡張により、以下のメリットが得られます:
- 設定値の一元管理: 異なるコンポーネント間で同じ変数ライブラリを共有可能
- 環境間の整合性向上: Notebook とパイプラインで同じ設定値を使用することで、環境間での不整合を防止
- 開発効率の向上: ハードコードされた値を変数に置き換えることで、環境切り替え時の手動変更が不要
開発、テスト、本番環境間での設定値管理がより統一的に行えるようになり、データエンジニアリングプロジェクトの CI/CD プロセスが大幅に改善されます。
これらの新機能により、Microsoft Fabric の Data Factory は、より統合的で効率的、かつスケーラブルなデータ統合プラットフォームとして進化し、組織のデータ活用をさらに加速させています。
Microsoft Fabric の Data Factory 料金体系
Microsoft Fabric の Data Factory 利用にかかる料金は、Microsoft Fabric の課金モデルに基づいています。
Microsoft Fabric の容量単位(CU: Capacity Unit) で計算され、データの処理やパイプラインの実行に応じて課金されます。
※上記情報は 2025 年 2 月時点の情報です。最新の情報は 公式ドキュメント でご確認ください。
Microsoft Fabric の Data Factory の利用手順
ここでは、Microsoft Fabric の Data Factory の利用手順についてご紹介します。各ステップの概要は以下となります。
- ステップ 1:データフローの作成
- ステップ 2:データの変換
- ステップ 3: データパイプラインの作成
※ 前提条件は次のとおりです。
- Microsoft Fabric のアカウントとサブスクリプション
- Microsoft Fabric 対応ワークスペース(ワークスペースの作成は、こちらを参考にしてください。)
ステップ 1: データフローの作成
まずデータフローを作成し、データの取得元(ソース)を設定します。
- Microsoft Fabric を開きます。
 Microsoft Fabric 画面
Microsoft Fabric 画面 - ① 画面左下の三点リード(・・・)をクリックし、②「作成」を押します。
 作成ボタン
作成ボタン - Data Factory の「データフロー(Gen2)」をクリックします。
 データフロー(Gen2)ボタン
データフロー(Gen2)ボタン - データフローの名前等を入力し(ここでは、teldevice-dataflow1)、「Create」を押します。
 データフロー作成画面
データフロー作成画面 - データのインポート画面から、インポート方法を選びます(ここでは、「Text ファイルまたは CSV ファイルからインポート」)
 インポート画面
インポート画面 - ①「ファイルのアップロード」を選択し、ファイルをアップロードします。ここでは、sample*data_frow_gen2.csv というファイルをアップロードし、②「次へ」をクリックします。
 データソースへの接続画面
データソースへの接続画面 - ファイルがアップロードされたら、プレビュー画面が表示されるので「作成」をクリックします。
 ファイルデータのプレビュー画面
ファイルデータのプレビュー画面
ステップ 2 データの変換
取得したデータを クレンジング・加工・統合 して、分析や保存しやすい形に整えます。
- ワークスペースから作成されたデータフローを選択します。(ここでは、teldevice-dataflow1)
 データフロー選択画面
データフロー選択画面 - この画面は Microsoft Fabric の Data Factory である Power Query エディター です。ここでは、データフロー(Dataflow Gen2) を作成し、データの取得・変換・整形を行うことができます。
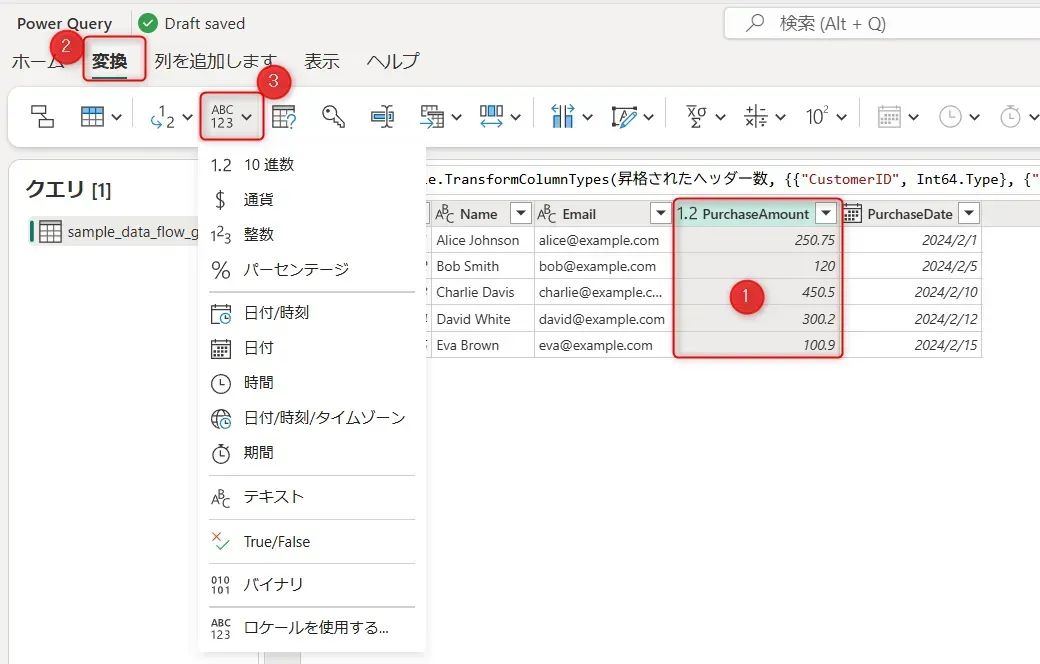
Power Query エディター
① 左パネル(クエリ一覧) クエリ(データセット)を管理するエリア です。
② メインエリア(データプレビュー) データテーブルのプレビューを表示 しており、現在のデータの中身が確認できます。
③ 上部メニュー(データ変換ツール) 「変換」タブ では、データの型変更・フィルタリング・列の追加などの編集が可能です。 「列を追加します」タブ では、新しい列を作成することができます。
④ 右パネル(クエリの設定) 「適用されたステップ」 に、データの加工履歴が表示されます。
- データ型を変更するには、① 該当列(ここでは PurchaseAmount)をクリックし、リボンの ②「変換」タブ →③「データ型」 から適切な型を選択します。
 データ型の変更
データ型の変更 - 特定の条件に一致するデータのみを残すこともできます(フィルタリング)。 例えば 120 以上の購入金額のみ表示するには、フィルタリングしたい列(例:PurchaseAmount)の 列ヘッダーの ▼ マーク をクリックし、「数値フィルター」→「次の値より大きい」をクリックします。
 フィルター画面1
フィルター画面1 - 行のフィルター処理画面に記入したら、「OK」をクリックします。
 フィルター画面2
フィルター画面2 - 120 より大きい値だけが表示されました。
 フィルター画面3
フィルター画面3 - 画面左上の「ホーム」タブにある「保存と実行」ボタン をクリックすると、データフローの変更が適用され、ワークスペースに保存 されます。
 保存と実行ボタン
保存と実行ボタン
ステップ 3: データパイプラインの作成
データの移動や処理を自動化するパイプラインを作成します。
- 既存のワークスペースを選択し、①「新しい項目」から ②「Data pipeline」をクリックします。
Data pipeline クリック
- 「新しいパイプライン」画面から任意の パイプライン名 を入力して「作成」をクリックします。(ここでは teldevice-pipeline1)
 新しいパイプライン画面
新しいパイプライン画面 - この画面は、Microsoft Fabric のデータパイプラインの作成画面 です。ここで「データコピーのアシスタント」を選択します。
 データコピーのアシスタントクリック
データコピーのアシスタントクリック - 「サンプルデータ」タブ を選択し、ここでは「Public Holidays(祝日)」データ を選択します。
 サンプルデータ選択画面
サンプルデータ選択画面 - データのプレビューを確認し、「次へ」をクリックします。
 プレビュー確認画面
プレビュー確認画面 - コピー先(データの保存先)を選択します。「レイクハウス」 を選択します。
 レイクハウス選択
レイクハウス選択 - 新しいレイクハウスを作成する画面が表示されるので、レイクハウス名を入力 し(例:teldevice*lakehousetest1)、「作成して接続」をクリックします。
 新しいレイクハウス画面
新しいレイクハウス画面 - データのマッピングをします。適切な設定をし、「次へ」をクリックします。
 データのマッピング画面
データのマッピング画面 - 設定を確認し、「保存して実行」をクリックします。
 レビューと保存画面
レビューと保存画面 - パイプラインのキャンバスに「Copy(データのコピー)」アクティビティ が追加されました。
 アクティビティ追加画面
アクティビティ追加画面
Microsoft Fabric の Data Factory のユースケース
Microsoft Fabric の Data Factory は、データの統合・変換・オーケストレーションを効率化するため、さまざまな業界で活用されています。以下に代表的なユースケースを紹介します。
小売業における販売データの統合とリアルタイム分析
小売業では、各店舗や EC サイトの販売データが異なるシステムに分散しており、リアルタイムでの分析が難しいという課題があります。
Microsoft Fabric の Data Factory を活用することで、販売データを OneLake に統合し、Power BI でリアルタイム分析を行うことが可能になります。在庫の最適化や売上トレンドの把握が迅速にでき、マーケティング施策の改善にもつながります。
製造業:IoT データの収集と異常検知
製造業では、生産ラインから収集される大量の IoT センサーデータを効率的に管理し、製品品質の分析を行うことが課題となっています。Microsoft Fabric の Data Factory を活用することで、生産ラインのセンサーデータを定期的なバッチ処理で OneLake に集約します。
これらのデータは、品質管理や傾向分析に活用できます。例えば過去データの傾向分析や品質パラメータの相関分析を行うことで、品質の変動要因を特定し、製造プロセスの最適化や品質改善につなげることができるでしょう。
医療業界:患者データの統合と予測分析
病院ごとに異なる電子カルテ(EHR)システムを使用しているため、患者の診療履歴を統合するのが困難なケースがあります。
Microsoft Fabric の Data Factory を活用し、各病院の EHR データを Microsoft Fabric の OneLake に統合し、AI/ML を活用した診断支援を実装することで、診療の効率化と診断精度の向上が期待できます。
サプライチェーン:在庫データの統合と最適化
サプライチェーンでは、倉庫や店舗の在庫データが分散しているため、適切な需給予測が難しくなることがあります。
Microsoft Fabric の Data Factory を使って在庫データを統合し、AI による需要予測を実施することで、在庫の最適化とコスト削減を実現できるでしょう。
まとめ
本記事では、Microsoft Fabric の Data Factory の概要・メリット・Azure Data Factory との違い・ユースケース・料金体系などについてご説明しました。 Microsoft Fabric の Data Factory は、クラウドベースのデータ統合サービスであり、ノーコード/ローコードでのデータパイプライン構築 を可能にします。OneLake との統合 により、データの取り込みから変換、オーケストレーションまでをシームレスに実行でき、企業のデータ活用を加速 することができるでしょう。
ぜひ Microsoft Fabric の Data Factory を導入して、データの統合から分析までをシームレスに行える環境を構築してみてください。効率的で柔軟なデータ処理基盤を構築し、迅速な意思決定とビジネス価値の向上の実現に役立つでしょう。
東京エレクトロンデバイスは、Microsoft Fabric の企業導入をサポートしています。Azure を活用したシステム構築、データ分析基盤の構築、クラウド移行など、お客様の課題や目的に合わせて幅広く支援いたします。 無料相談も受け付けておりますので、お気軽にご相談ください。



