
Azure Data Lake Storage Gen2 とは
Azure Data Lake Storage Gen2(ADLS Gen2)は、ビッグデータ処理と分析のために設計された Azure のクラウドストレージサービスです。
大規模データを効率的に保存し、柔軟な処理を可能にする特長を備えています。
データレイクについて
データストレージサービスとして Azure には、Azure Blob Storage があります。Azure Blob Storage は Azure の汎用オブジェクトストレージ で、画像、動画、ログ、バックアップデータなどの保存に最適なサービスです。
Azure Data Lake Storage Gen2 は、この Azure Blob Storage を基盤とし、データレイクとしての機能 (主に階層型名前空間) を追加実装した ストレージサービスです。
データレイクの特徴は以下のとおりです。
- 多様な形式のデータをそのまま統合 構造化データ(データベースのテーブルなど)、半構造化データ(JSON、XML など)、非構造化データ(画像、動画、テキストなど)を、従来の ETL(抽出・変換・ロード)プロセスを事前に実施することなく、そのままの形式で一元的に保存できます。 必要に応じて、後から「ELT」(Extract, Load, Transform)プロセスで変換や加工を行うことで、迅速なデータ活用が可能となります。
- 将来の多様なビジネスニーズに柔軟に対応 保存されたデータは、将来的なビジネスの変化に応じて、さまざまな用途に活用できます。 たとえば、既存のデータウェアハウス(DWH)との連携による分析、AI・機械学習モデルのトレーニング、リアルタイム分析、コンプライアンス対応のための長期保管など、幅広い目的に対応が可能です。
- ペタバイト級のデータにも対応可能な拡張性 数百ギガバイトからペタバイト級まで、ビジネスの成長に合わせてデータ量が爆発的に増加しても、パフォーマンスを劣化させることなく、柔軟に対応できます。 これにより、将来的なデータ量の増加を気にせず、安心してデータを蓄積することが可能です。
 データレイク機能イメージ(参考:Microsoft)
データレイク機能イメージ(参考:Microsoft)
Gen1 の課題
Azure Data Lake Storage は以前まで Gen1(Azure Data Lake Storage Gen1)というバージョンが提供されていました。 Gen1 は、データレイクとしての役割は果たしつつも、独立したストレージサービスであり、Azure Blob Storage と統合されていませんでした。
そのため、以下のような課題があり、汎用性や柔軟性が限られていました。
- コスト効率 Blob Storage のようなストレージ階層(ホット、クール、アーカイブ層)がなく、データ保存のコスト最適化が困難でした。
- スケーラビリティ グローバル対応が限定的で、拡張性に制約がありました。
- 互換性 Azure の他サービスやサードパーティツールとの連携が限定的でした。
Gen1 は独自設計のストレージサービスであったため、Blob Storage が提供するメリットを享受できませんでした。
Gen2 への進化
その後、現在のGen2(Azure Data Lake Storage Gen2)に進化し、Azure Blob Storage との統合がされ、上記課題についての改善が実現しました。
- Azure Blob Storage との統合 Azure Blob Storage を基盤に構築され、Blob Storage のすべてのメリット(スケーラビリティ、コスト効率など)を活用可能となりました。
- Hierarchical Namespace の高速化 GEN1 でも階層型名前空間(Hierarchical Namespace)をサポートしていましたが、GEN2 では Blob Storage 基盤の恩恵で検索や操作がさらに高速化されています。
- ファイルやディレクトリ単位でのアクセス権管理が可能 GEN1 でのアクセス制御リスト(ACL)にさらに、Blob Storage のアクセス制御機能(RBAC など)も統合され、セキュリティと柔軟性が向上しました。
- コスト効率 Blob Storage の料金体系を採用し、ホット、クール、アーカイブ層でストレージコストを最適化可能となりました。 アクセス頻度の低いデータをクールやアーカイブ層に移すことでコスト削減ができます。
- スケーラビリティとリージョン対応 Blob Storage を基盤としているため、ほぼすべての Azure リージョンで利用可能となりました。 Geo-Redundancy(ジオレデンダンシー)やゾーン冗長性(ZRS)をサポートし、データの耐障害性が向上したほか、大量データの保存と処理に対してスケーラブルなパフォーマンスを提供しています。
両者の違い
Azure Data Lake Storage Gen1 と Gen2 の違いをまとめた表は次のとおりです。
| 項目 | Gen1 | Gen2 |
|---|---|---|
基盤 | 独自設計 | Azure Blob Storage を基盤とする |
コスト効率 | ストレージ階層がなく最適化が困難 | ホット、クール、アーカイブ層で最適化可能 |
スケーラビリティ | 拡張性に制約 | 高いスケーラビリティ |
名前空間 | 階層型名前空間は対応するが限定的 | 階層型名前空間をさらに高速化 |
アクセス権管理 | ACL のみ対応 | ACL に加え RBAC を統合 |
互換性 | Azure サービスやツールとの連携が限定的 | 多くの Azure サービスとシームレスに連携 |
Azure Data Lake Storage Gen2 の主な機能とメリット
Azure Data Lake Storage Gen2 は、大規模なデータ分析を効率化するために設計された次世代型のデータストレージサービスです。その特徴を説明します。
Hierarchical Namespace(階層型名前空間)
Azure Data Lake Storage Gen2 は 階層型名前空間を採用しています。そ のため、従来のデータレイクや Blob ストレージの採用している フラット型名前空間と比較して、データ操作(コピー、移動など)を効率的に行うことができます。
両者の違いは次のとおりです。
フラット型名前空間(Azure Blob Storage の特徴) Azure Blob Storage はフラット型名前空間を採用しています。すべてのデータ(Blob)は 1 つのコンテナー内で管理され、ディレクトリやフォルダ構造の概念はありません。 そのため以下のような課題がありました。
- 大量データの操作(例えば削除や名前変更)を行う際に、データ数に比例して操作が増えるため効率が低下
- データ分析のユースケースではパフォーマンスが劣る可能性
 フラット型名前空間イメージ(参考:Microsoft)
フラット型名前空間イメージ(参考:Microsoft)
階層型名前空間 Azure Data Lake Storage Gen2 では、階層型名前空間が採用されています。 階層型名前空間とは、ファイルシステムのようにデータをディレクトリやフォルダ構造で整理して管理できる仕組みを指します。
以下の特徴があります。
- ディレクトリ構造のサポート データをフォルダやサブフォルダに整理でき、管理が容易になります。
- 操作の効率化 フォルダ全体の削除や名前変更が 1 回の操作で実行可能です。
- 高いパフォーマンス: データが整理されて保存されるため、保存や取得時のパフォーマンスが向上します。
 階層型名前空間イメージ(参考:Microsoft)
階層型名前空間イメージ(参考:Microsoft)
Hadoop 互換の ACL とセキュリティ機能
Azure Data Lake Storage Gen2 は、以下の仕組みによりビッグデータ分析ツールを効率的に活用しながらも、高度なセキュリティ管理が可能です。
- Hadoop 互換 Hadoop 分散ファイルシステム(HDFS)の操作をそのまま利用できる機能が備わっています。 HDFS とは、大規模なデータを効率的に格納・管理し、並列処理を実現するために設計された分散型のファイルシステムです。 Apache Hadoop や Spark といったビッグデータ分析ツールを ADLS Gen2 上で動作させることが可能です。
- ACL(アクセス制御リスト) ACL は、ユーザーやグループごとに、ディレクトリやファイルへのアクセス権限を細かく設定する仕組みです。データのセキュリティとプライバシーを保護するのに役立ちます。
高いスケーラビリティとパフォーマンス
Azure Data Lake Storage Gen2 は、非常に高いスケーラビリティとパフォーマンスを提供しています。 そのため、大規模なデータワークロードにも対応可能です。
データ解析ツールとの連携容易性
ADLS Gen2 は、Azure Databricks や HDInsight、Synapse Analytics などのデータ解析ツールとスムーズに統合することができます。
Azure Data Lake Storage Gen2 の料金
Azure Data Lake Storage Gen2 の料金は、ストレージ容量、トランザクション数、データ転送量、データアクセス頻度、およびストレージ階層(ホット、クール、コールド、アーカイブ)などに基づいて算出されます。
ストレージ容量料金
ストレージ容量の使用量に応じて料金が発生します。使用量はバイナリギガバイト(GB)単位で計算され、ストレージ階層ごとに異なる料金が適用されます。
| ストレージ層 | 料金 |
|---|---|
Premium | 無制限 - ¥27.902/GB |
ホット | 最初の 51,200 GB/月 - ¥2.853/GB |
次の 460,800 GB/月 - ¥2.744/GB | |
512,000 GB/月を超える - ¥2.620/GB | |
クール | 無制限 - ¥1.551/GB |
コールド | 無制限 - ¥0.669644/GB |
アーカイブ | 無制限 - ¥0.311/GB |
トランザクション料金
データ操作(読み取り、書き込み、クエリなど)の回数に基づき課金されます。
| トランザクション | Premium | ホット | クール | コールド | アーカイブ |
|---|---|---|---|---|---|
書き込み操作 (4 MB ごと、10,000 あたり) | ¥4.23178 | ¥10.07565 | ¥20.15130 | ¥43.55781 | ¥24.18156 |
読み取り操作 (4 MB ごと、10,000 あたり) | ¥0.33793 | ¥0.80606 | ¥2.01513 | ¥24.18156 | ¥1,209.07800 |
クエリ アクセラレーション - スキャンされたデータ (GB あたり) | 利用できません | ¥0.37203 | ¥0.37203 | ¥0.37203 | 利用できません |
クエリ アクセラレーション - 返されたデータ (GB あたり) | 利用できません | ¥0.13021 | ¥1.86012 | ¥1.86012 | 利用できません |
データ転送料金
データを Geo レプリケーション(GRS や RA-GRS)で別の Azure リージョンに複製する場合、帯域幅に応じた料金が発生します。詳細はこちらを参照してください。
その他の操作料金
その他の主な料金は以下のとおりです。
操作タイプ | Premium | ホット | クール | コールド | アーカイブ |
|---|---|---|---|---|---|
反復読み取り操作 | ¥4.23178 | ¥10.07565 | 該当なし利用できません | 該当なし利用できません | 該当なし |
優先度が高い読み取りのアーカイブ (10,000 あたり) | 該当なし | 該当なし | 該当なし | 該当なし | ¥12,090.7800 |
反復書き込み操作 (100 件) | ¥4.23178 | ¥10.07565 | ¥10.07565 | ¥10.07565 | ¥10.07565 |
削除 (無料) 以外のその他すべての操作 (10,000 件あたり) | ¥0.33793 | ¥0.80606 | 該当なし利用できません | 該当なし利用できません | 該当なし利用できません |
データ取得(GB あたり) | — | 無料 | ¥1.55010 | ¥5.58036 | ¥3.72024 |
優先度が高い取得のアーカイブ (GB あたり) | 該当なし | 該当なし | 該当なし | 該当なし | ¥18.6012 |
データ書き込み (GB あたり) | 該当なし利用できません | Free | Free | Free | Free |
インデックス (GB/月) | ¥27.90180 | ¥4.07677 | 該当なし利用できません | ¥4.07677 | 該当なし利用できません |
コスト効率化のポイント
コスト面で効果的に利用するためには、以下のポイントを押さえておくことが重要です。
- ストレージ階層の選択が重要 データのアクセス頻度に応じて、適切なストレージ階層を選択することでコストを最適化できます。 例えば、頻繁にアクセスされるデータはホット層に保存し、あまりアクセスされないバックアップデータやログデータはクール層やアーカイブ層に保存することで、料金を抑えることが可能です。
- 予約容量での割引 長期的に大量のデータを利用する場合、ストレージの予約容量を活用することでコスト削減が見込めます。1 年または 3 年間の契約で、使用料金が最大 35%割引されます。
- 早期削除に注意 クール層やアーカイブ層に保存したデータを規定の期間内に削除または階層変更すると、早期削除料金が発生します。 保存期間を考慮し、適切な階層にデータを配置することで、不要なコストを回避することができます。
※本記事に記載されている情報は、2025 年 2 月時点の情報です。変動する可能性があるため、最新の情報については、公式ページで確認してください。
Azure Data Lake Storage Gen2 の作成手順
ここでは、Azure Data Lake Storage Gen2 の作成手順についてご紹介します。
※ 前提条件として、以下のリソースが有効であることをご確認ください。
- Azure アカウント、サブスクリプション、リソースグループ
- Azure ポータル画面の「リソースの作成」で「storage account」で検索し、「ストレージ アカウント」をクリックします。
 ストレージアカウント選択画面
ストレージアカウント選択画面 - 「ストレージアカウントを作成する」画面、「基本」タブで適切な設定をします。 「次へ」をクリックします。
 基本タブ画面
基本タブ画面 - 「詳細」タブで、「階層型名前空間を有効にする」にチェックを入れます。 この設定をするだけで本ストレージアカウント内で作成するコンテナやデータはべて Azure Data Lake Storage Gen2(ADLS Gen2)として機能します。
他の事項も入力したら、「次へ」をクリックします。 詳細タブ画面
詳細タブ画面
- 「ネットワーク」タブで適切な設定をします。 「次へ」をクリックします。
 ネットワークタブ画面
ネットワークタブ画面 - 「データ保護」タブで適切な設定をします。 「次へ」をクリックします。
 データ保護タブ画面
データ保護タブ画面 - 「暗号化」タブで適切な設定をします。 「確認と作成」をクリックします。
 暗号化画面
暗号化画面 - 「確認と作成」タブで適切な設定がされていることを確認します。 「作成」をクリックします。
 確認と作成画面
確認と作成画面 - デプロイ完了後「リソースに移動」をクリックします。
 デプロイ完了画面
デプロイ完了画面
Azure Data Lake Storage Gen2 と Microsoft Fabric との連携
Azure Data Lake Storage Gen2 と Microsoft Fabric は、データ統合および分析の分野で密接に関連しています。ここでは、両者の関連についてご説明します。
Microsoft Fabric とは
Microsoft Fabric は、データ統合、分析、レポート作成を統一的に行うための、クラウドベースのデータプラットフォームです。 データの収集、保存、分析、視覚化までのプロセスを包括的に提供し、データ活用を効率化します。
 Microsoft Fabric イメージ(参考:Microsoft)
Microsoft Fabric イメージ(参考:Microsoft)
Microsoft Fabric のデータ基盤としての ADLS Gen2
Microsoft Fabric は、OneLake という統一データプラットフォームを中心に設計されています。 この OneLake は ADLS Gen2 上に構築されており、以下の役割を担っています。
- データの一元管理 ADLS Gen2 を利用して、構造化データや非構造化データを統合的に管理することができます。ディレクトリやフォルダで整理されたデータがそのまま Microsoft Fabric で利用可能です。
- リアルタイムアクセス Microsoft Fabric の分析ツールは、ADLS Gen2 に直接アクセスできるため、データ移動の必要がありません。そのため、リアルタイムでのデータ処理や視覚化が実現します。
【関連記事】 OneLake とは?統合データレイクで実現する次世代データ分析基盤を解説
Dataflow Gen2 を使った ADLS Gen2 の連携手順
Microsoft Fabric の Data Factory では、Azure Data Lake Storage Gen2 (ADLS Gen2) に接続するためのコネクタが用意されています。 このコネクタは、Dataflow Gen2 とデータパイプラインの両方で利用でき、ADLS Gen2 に格納されたデータの活用を容易にします。
- Dataflow Gen2: Power Query の使い慣れたインターフェースで、ADLS Gen2 への接続とデータ変換処理を定義できます。
- データパイプライン: ADLS Gen2 と Microsoft Fabric 内の他のデータストア間でデータを移動したり、ADLS Gen2 から取得したデータをパイプラインの他のアクティビティで使用したりできます。
Dataflow Gen2 から ADLS Gen2 に接続する場合、以下の 2 つの方法があります。
- Dataflow Gen2 の「Azure Data Lake Storage Gen2」コネクタを使用する: Dataflow Gen2 の接続設定で、ADLS Gen2 の URL と認証情報を直接入力する方法です。
- OneLake ショートカットを使用する: Microsoft Fabric の OneLake に ADLS Gen2 へのショートカットを作成しておき、Dataflow Gen2 では「OneLake data hub」からショートカットを選択する方法です。
今回は、設定が比較的容易で、Power Query を活用できる Dataflow Gen2 の「Azure Data Lake Storage Gen2」コネクタを使った連携方法 について、詳細な手順を説明します。
前提条件
- ADLS Gen2 ストレージアカウント、ファイルシステム (コンテナー) が事前に作成済みであること。
- 組織アカウント、アカウントキー、SAS トークン、またはサービスプリンシパルのいずれかの認証情報が取得済みであること。
新規データフロー (Gen2) の作成
- Microsoft Fabric のワークスペースのページから、「新しい項目」を選択します。
- 新しい項目の選択画面*
- 次のような画面が表示されるので、「データフロー(Gen2)」を選択します。
 ショートカットの選択画面
ショートカットの選択画面 - データフローの名称を設定し、「Create」を選択します。
- 「別のソースからデータを取得する」を選択します。
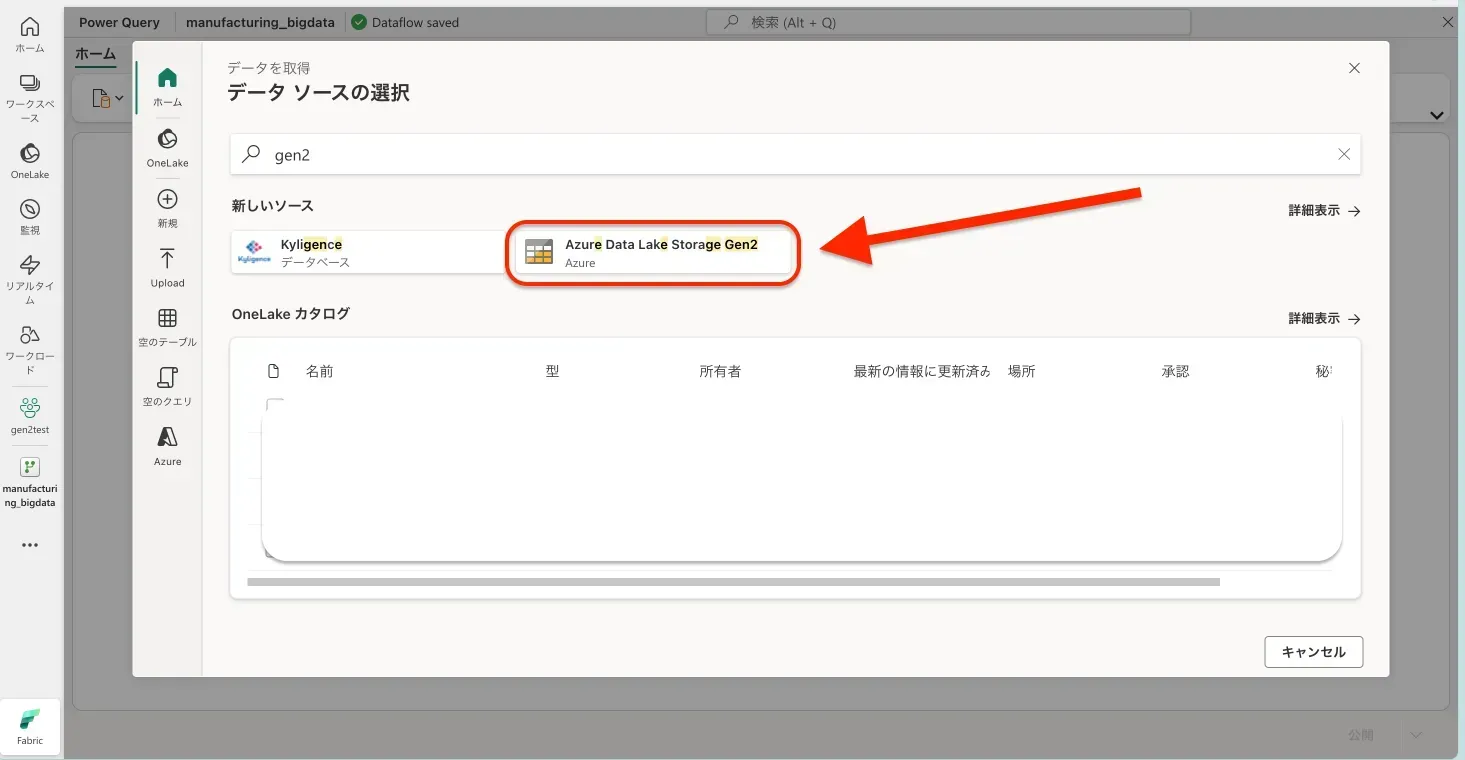
- 検索窓に「gen2」と入力し、「Azure Data Lake Storage Gen2」のアイコンを選択します。
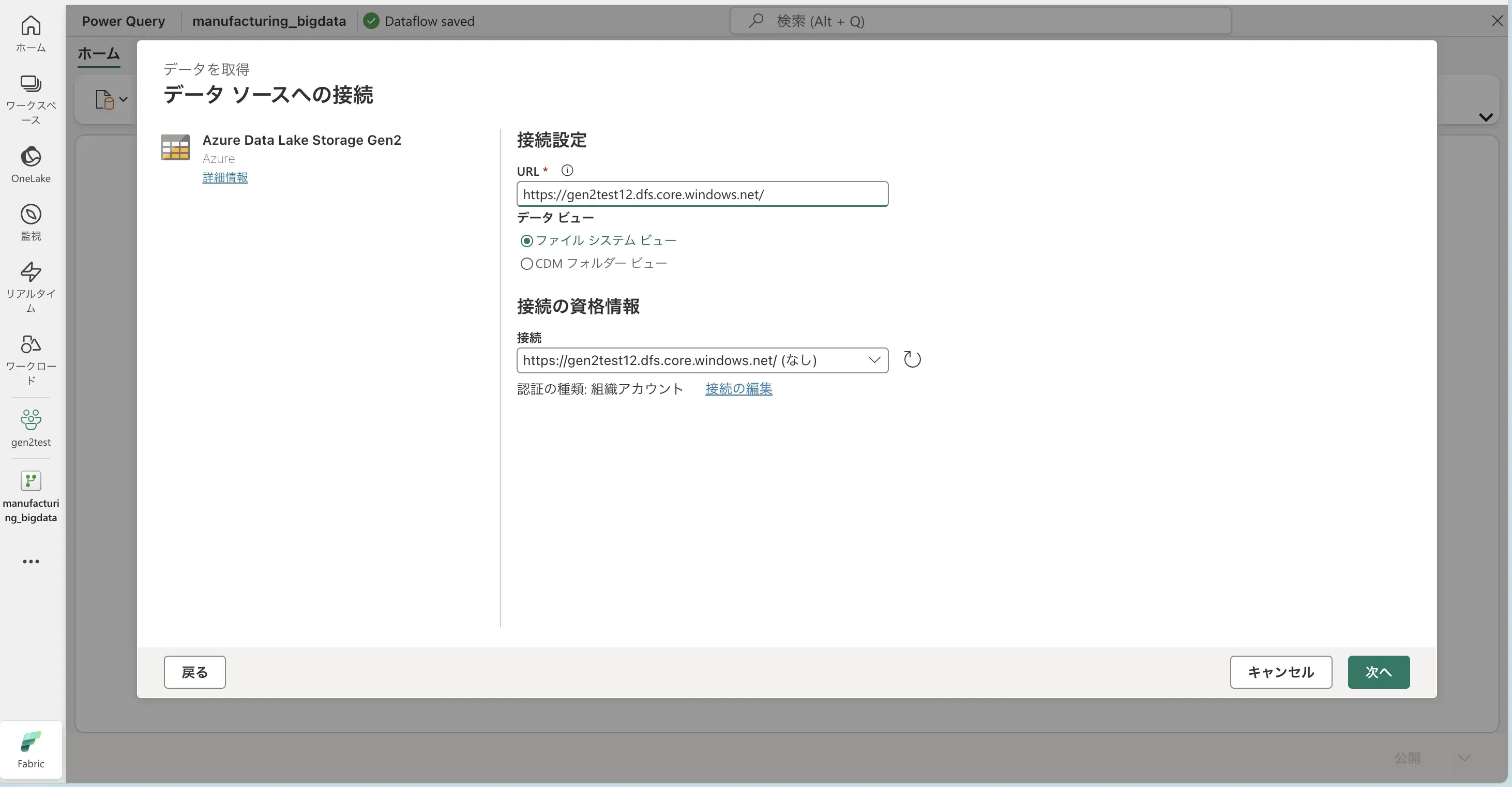
- 「データソースへの接続」ダイアログが表示されるので、情報を入力します。 入力が完了したら、「次へ」を選択します。
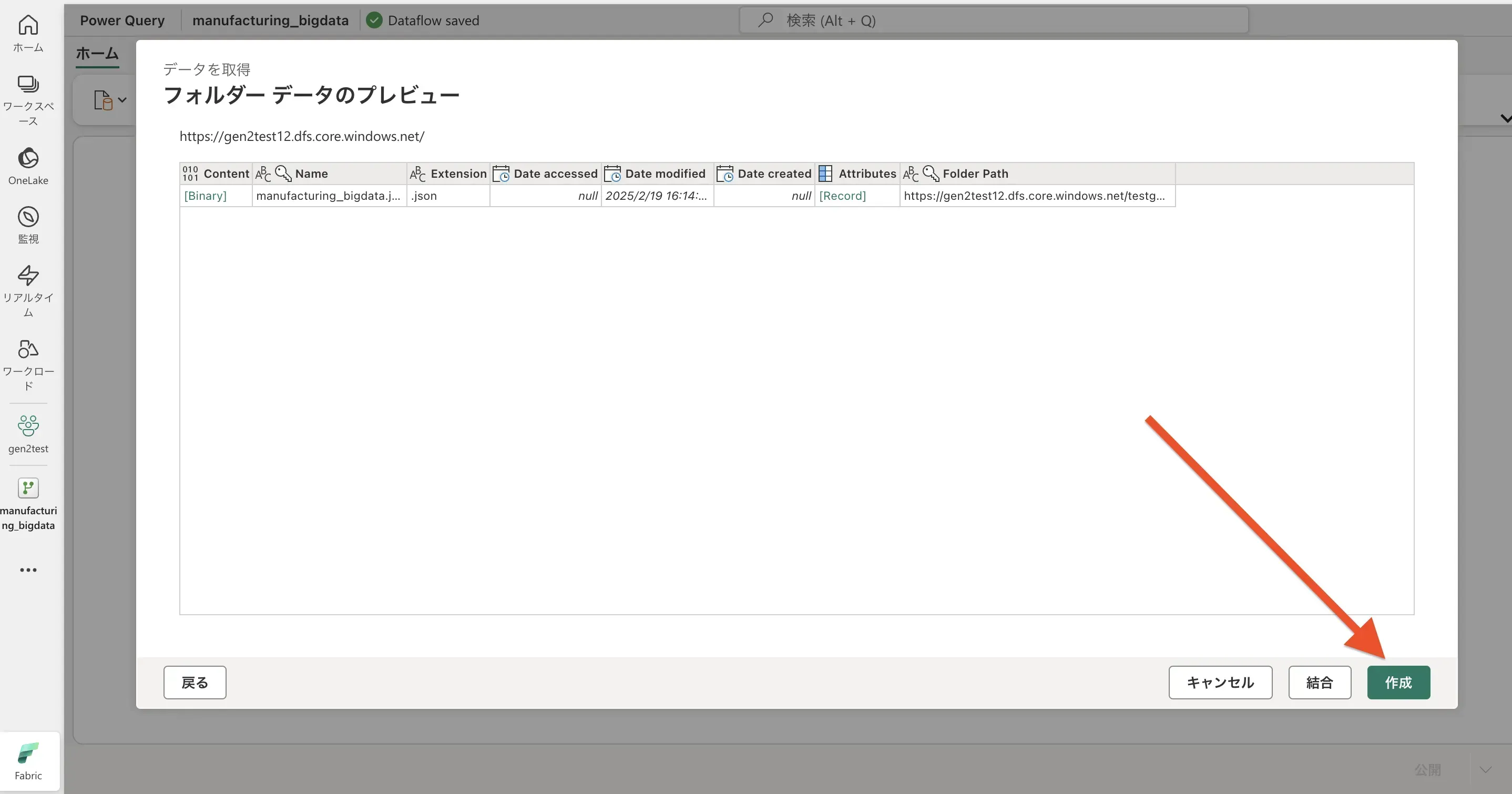
- すると、接続先のフォルダデータのプレビューが表示されるので、問題がなければ「作成」を選択します。
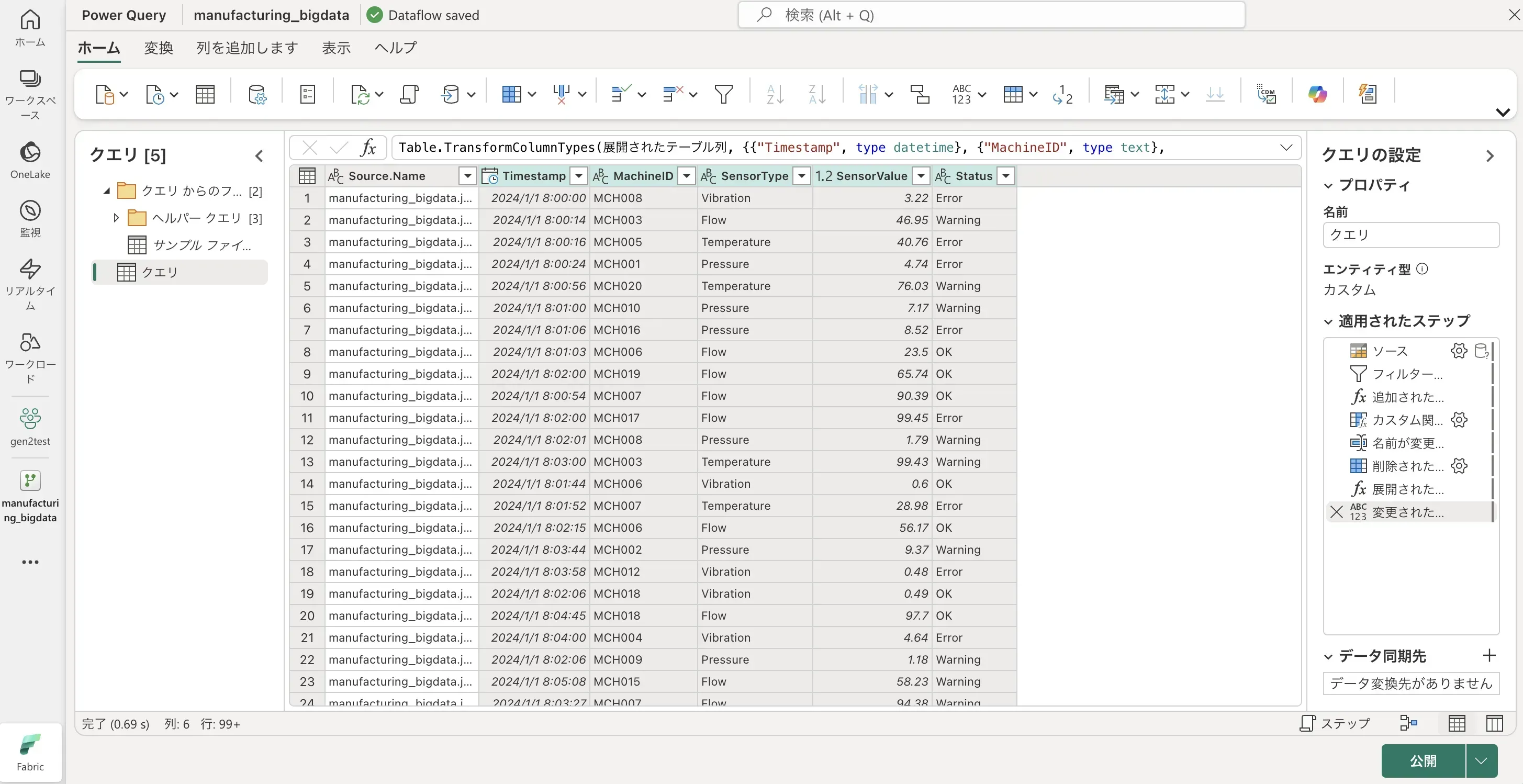
- Power Query のプレビュー画面に接続したデータが表示されます。
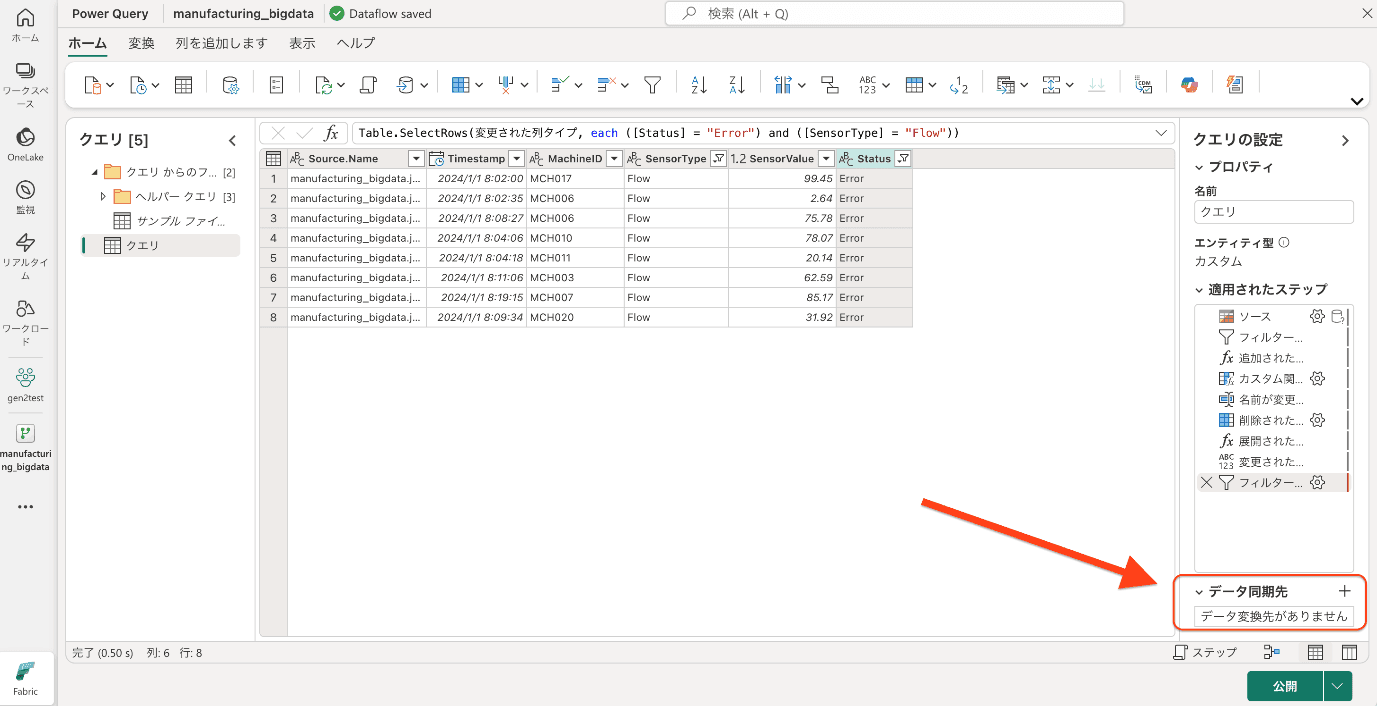
データ変換(Power Query)
Power Query の豊富な変換機能を使って、データを加工・整形します。 画面上部のリボンメニュー、各列のヘッダーのメニュー、右クリックメニューなどから、様々な変換操作を選択できます。
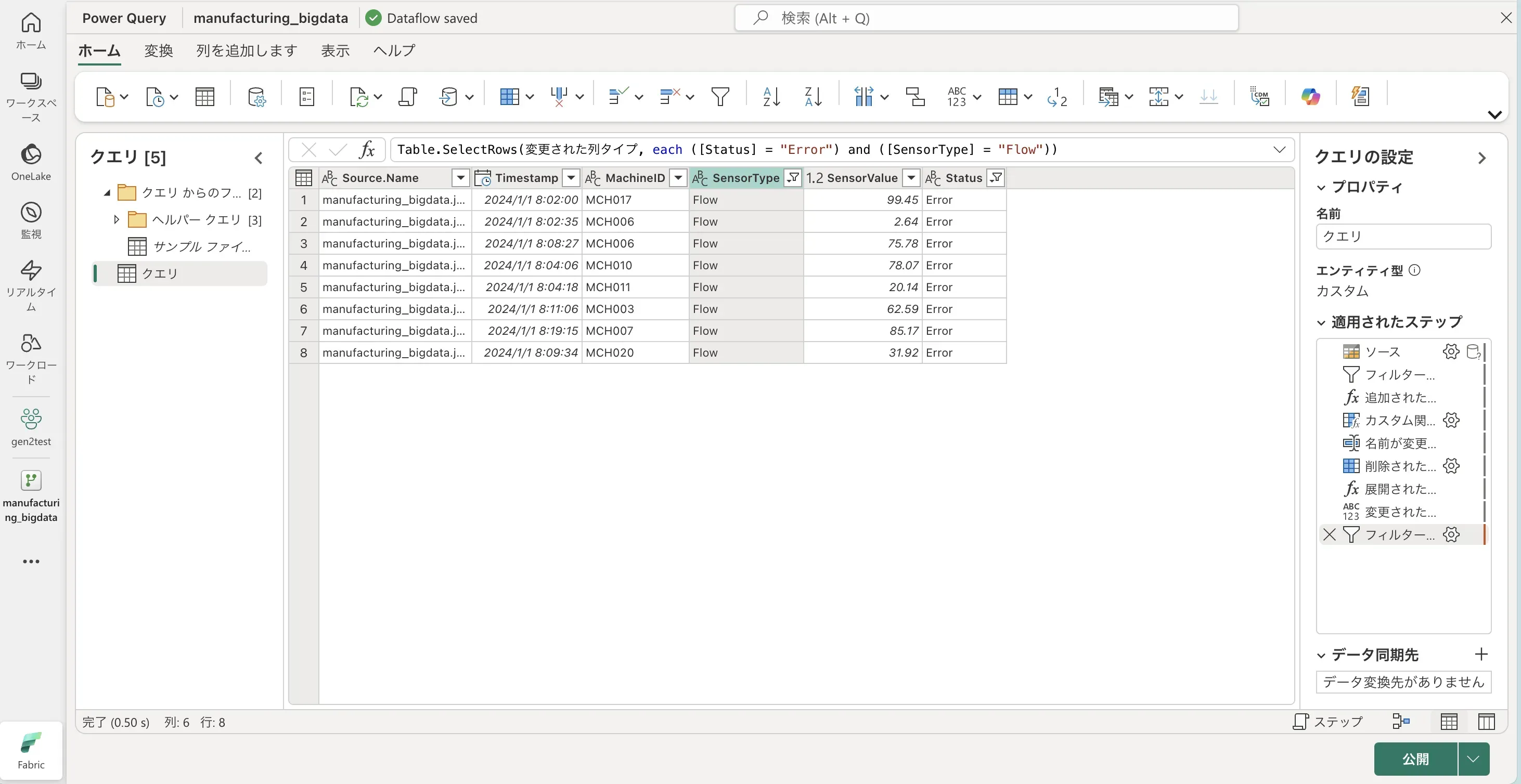
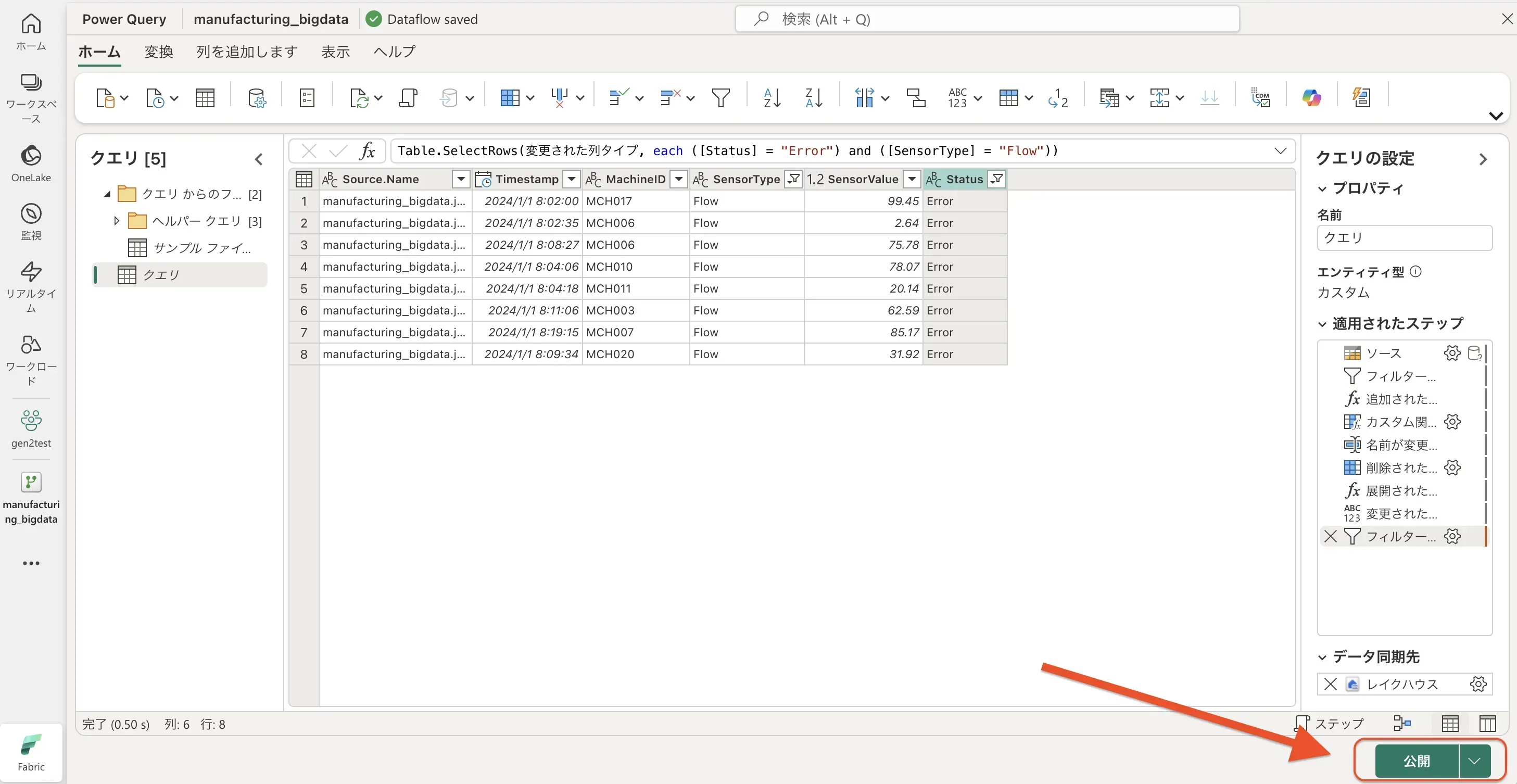
以下は一部のデータ(「SensorType 列」→Flow、「Status 列」→Error をソートした例です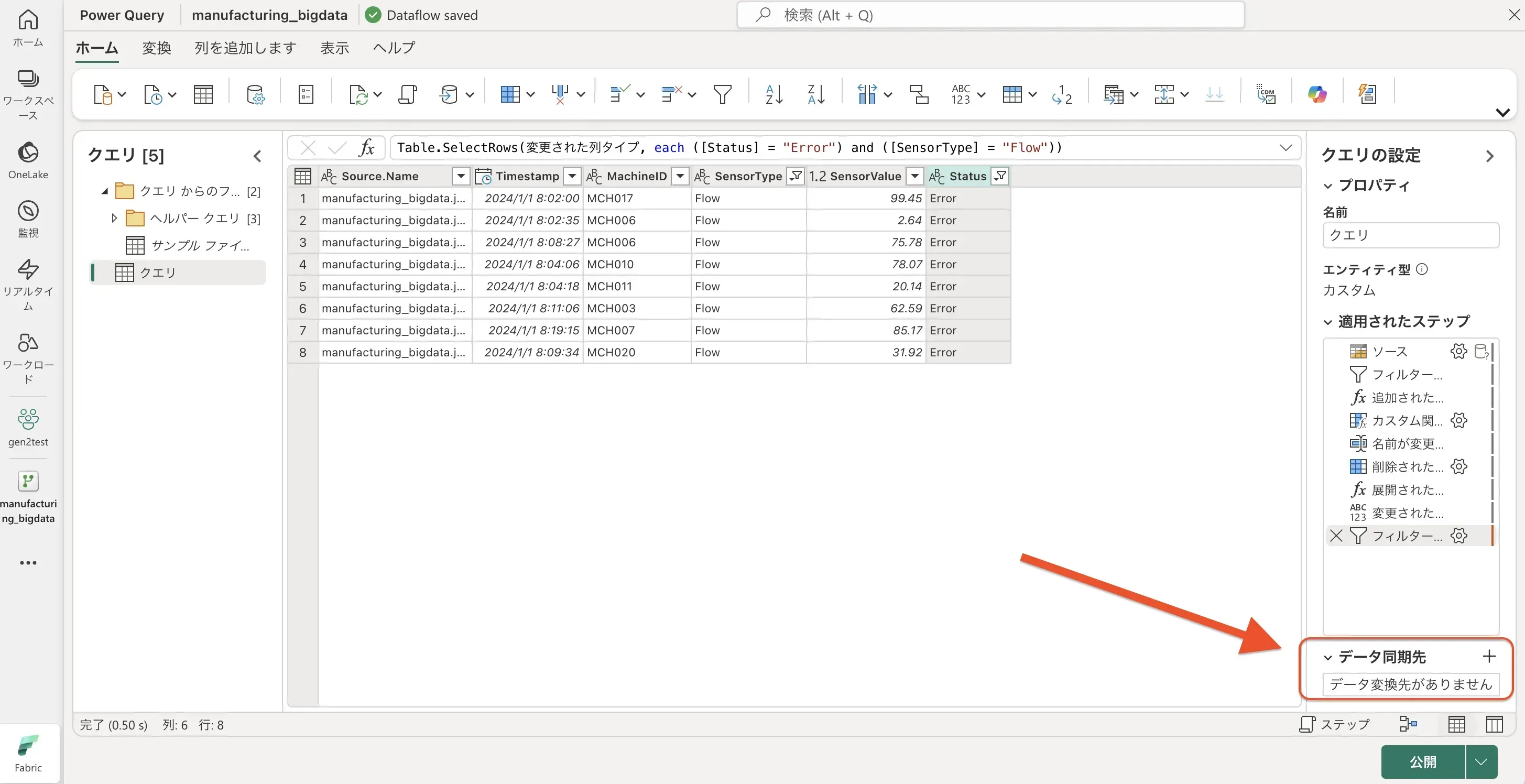
適用した変換ステップは、右側の「クエリの設定」ペインの「適用されたステップ」に順次記録されます。 適用されたステップの参照
適用されたステップの参照
各ステップをクリックすると、その時点でのデータの状態を確認できます。
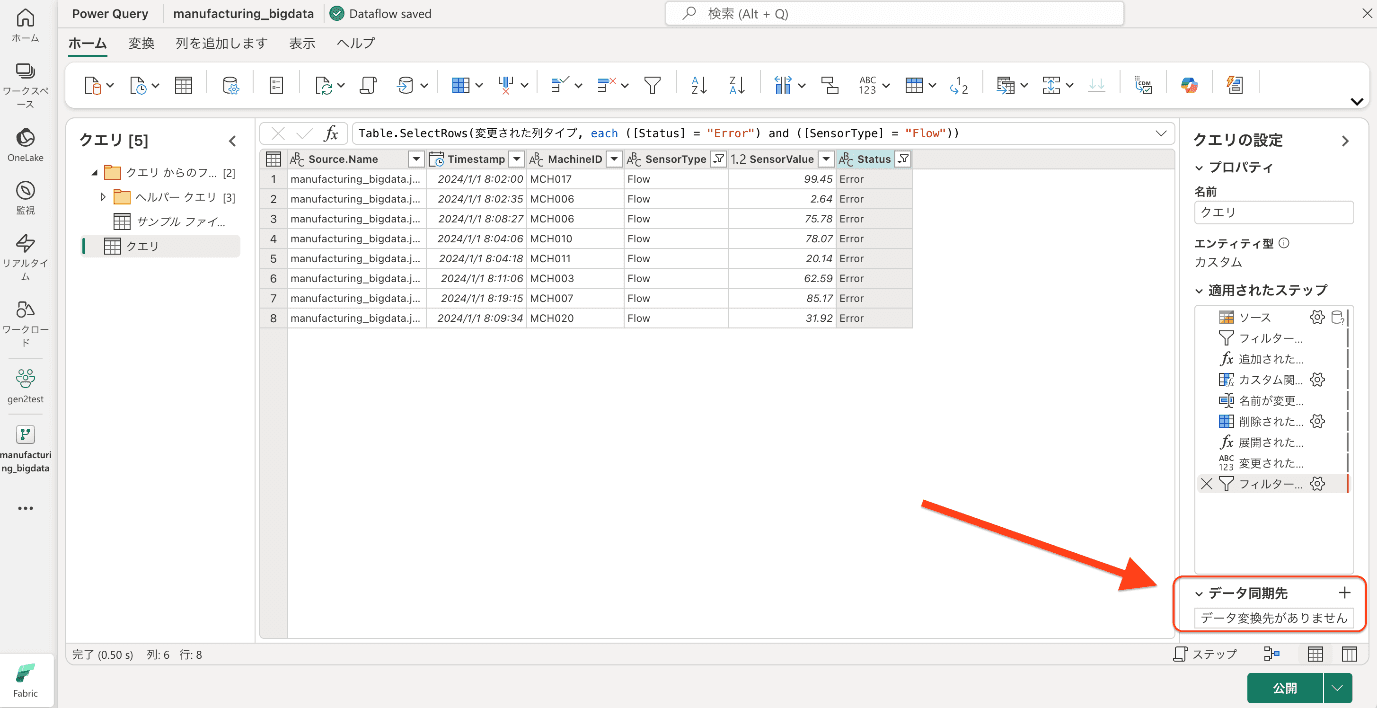
出力先の設定
Power Query エディターでのデータ変換が完了したら、変換後のデータの出力先を設定します。
- 画面右下の「データ同期先」横の「+」ボタンをクリックします。
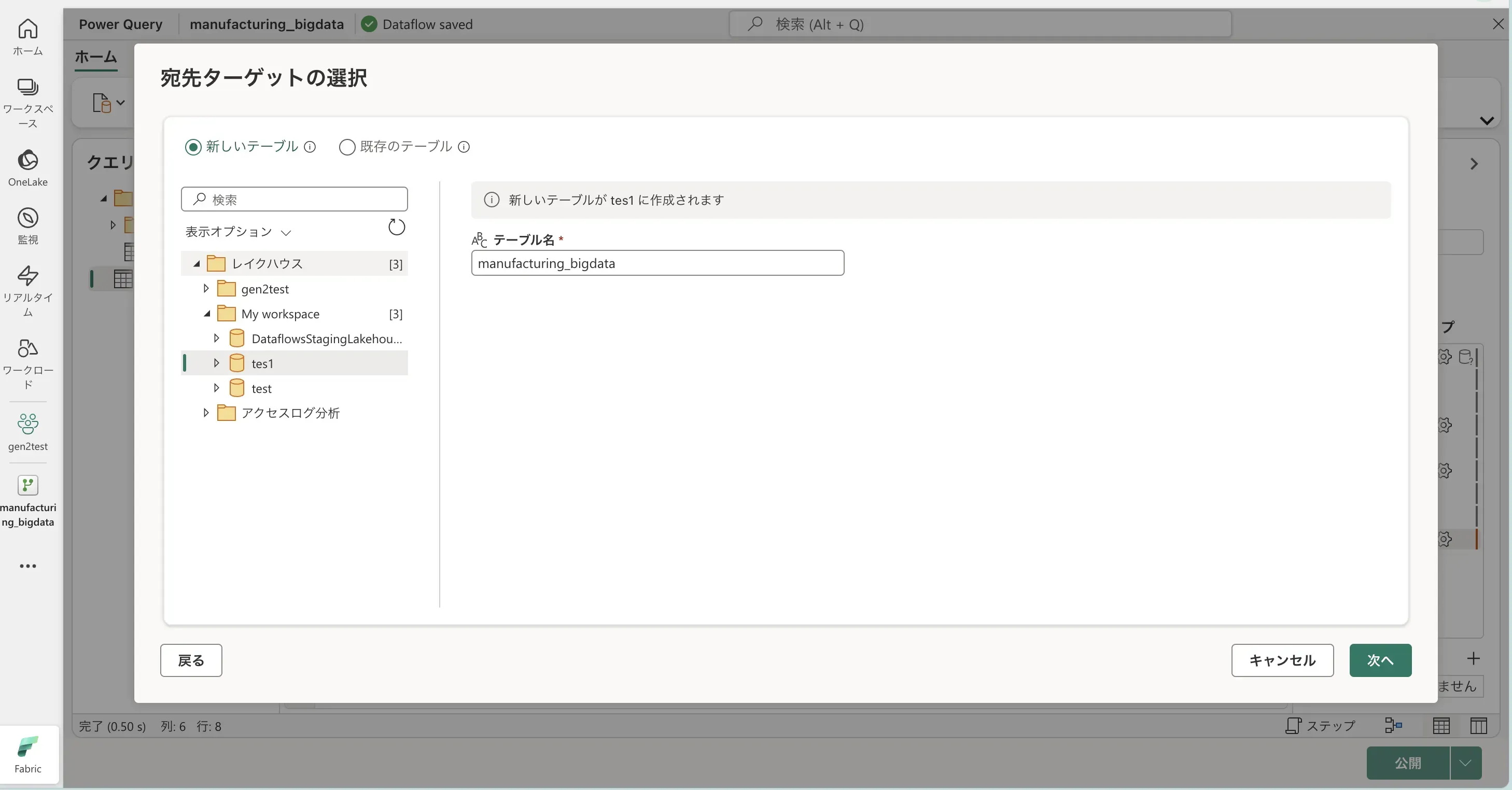
- 出力先を選択します。今回は、レイクハウスに出力します。
- 既存のテーブルを選択するか、新しいテーブルを作成して「次へ」を選択します。
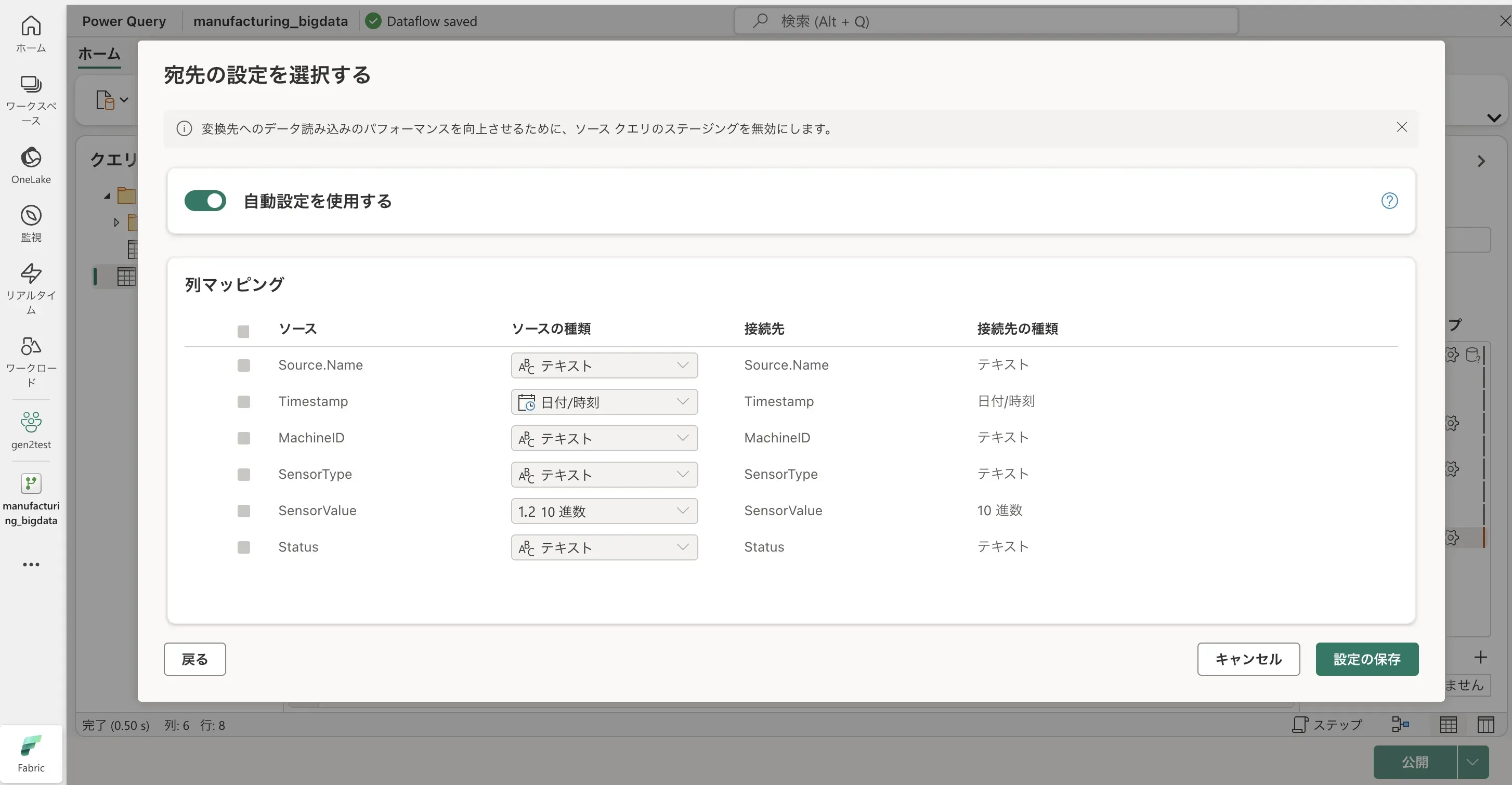
- 宛先の設定を選択します。今回は、自動設定を使用します。 設定が完了したら、「設定の保存」を選択します。
- これで、出力先の設定は完了です。
データフローの実行
- 接続先の設定が完了したら、画面右下の「公開」を選択します。
「公開」ボタンの右側の下向き矢印 (▼) をクリックすると、「今すぐ公開」と「後で公開」(スケジュール公開) を選択できます。
- すぐに Dataflow を実行したい場合は、「今すぐ公開」を選択します。
- 定期的に Dataflow を実行したい場合は、「後で公開」を選択し、スケジュールを設定します。
- Dataflow の実行が成功すると、指定した出力先(今回はレイクハウスのテーブル)に、変換後のデータが格納されます。
- Dataflow の実行状況は、Microsoft Fabric のワークスペース、または Dataflow Gen2 の編集画面の「更新履歴」で確認できます。
- 実行に失敗した場合は、更新履歴に表示されるエラーメッセージを参考に、Dataflow の設定 (接続情報、変換処理など) を修正し、再度「公開」してください。
Dataflow Gen2 を使った ADLS Gen2 連携の活用例
Dataflow Gen2 を使うと、Power Query の直感的なインターフェースで ADLS Gen2 のデータを簡単に加工・変換し、Microsoft Fabric の他のサービスで活用できるようになります。 以下に、代表的な活用例を紹介します。
- 複数データソースのマッシュアップ ADLS Gen2 のデータと、他のデータソース (CRM、Excel、SQL Database など) のデータを Power Query で結合・加工し、多角的な分析を行うことができます。
- 高度なデータクレンジング・変換 Power Query の高度な変換機能を活用し、ADLS Gen2 のデータを分析しやすい形に加工できます(例: テキストデータのクレンジング、JSON データの展開、日付/時刻データの変換、欠損値の補完、外れ値の処理、カスタム関数の作成・適用)。
- セルフサービス BI のためのデータ準備 ビジネスユーザーが Power BI でレポートを作成しやすいように、ADLS Gen2 のデータを事前に加工・整形できます (例: 不要な列の削除、列名の変更、データ型の変換、集計、ピボット/逆ピボット)。 以上のように、Microsoft Fabric の各サービス間の連携を活用することで、さまざまなデータ分析・活用シナリオを実現できます。
東京エレクトロンデバイスでは、Microsoft Fabric を使ったデータ活用基盤の構築を、伴走型支援サービスとして提供しています。
サービスの詳細につきましては、下記のリンクからご確認ください。 [AI 時代のデータ活用基盤「Microsoft Fabric」
他のデータ解析ツールとの連携
前述のセクションでは、Microsoft Fabric との連携について詳しく解説しましたが、Azure Data Lake Storage Gen2 は、Microsoft Fabric 以外の Azure の主要なデータ分析ツールとも高度な互換性を持ち、簡単に統合することができます。
主な連携サービスは次のとおりです。
Azure Databricks
Azure Databricks は、機械学習やデータサイエンスに特化した分析プラットフォームです。
ADLS Gen2 は Azure Databricks と直接接続できるので、ストレージ内のデータにそのままアクセス可能です。 Hadoop 互換のファイルシステム(HDFS)として利用できるため、Azure Databricks でのデータ処理を効率的に行うことができます。
Azure HDInsight
Azure HDInsight は、オープンソースのビッグデータフレームワーク(Apache Hadoop、Apache Spark、Kafka など)を利用したフルマネージド型クラウドサービスです。 大量データの処理やリアルタイムストリーミング分析に適しています。
ADLS Gen2 は Hadoop ベースの環境でそのまま利用可能なため、HDInsight クラスタから直接データを処理することができます。 Hadoop や Spark の既存知識を活用しつつ、クラウド上で大規模なデータ処理を実現可能です。
Azure Synapse Analytics
Azure Synapse Analytics は、エンタープライズ向けの統合型データ分析サービスです。 データ統合、ETL(抽出、変換、ロード)、データウェアハウス、ビッグデータ分析を一つのプラットフォームで提供しています。
Synapse は ADLS Gen2 と統合されており、Synapse 内から直接 ADLS Gen2 のデータにクエリを実行可能です。クラウド上のデータウェアハウス環境でのスピーディな分析が実現します。
Azure Machine Learning
Azure Machine Learning は、機械学習モデルの構築、トレーニング、デプロイを効率化するための統合プラットフォームです。
ADLS Gen2 は Azure Machine Learning と連携可能で、トレーニングデータセットやモデル結果を直接ストレージに保存・読み取りできます。 そのため、大量データを扱うモデルでもスムーズなトレーニングプロセスを実現します。
Azure Data Factory
Azure Data Factory は、クラウドネイティブなデータ統合および ETL ツールです。
ADLS Gen2 とシームレスに連携し、さまざまなデータソースからデータを収集、変換、格納するプロセスを自動化できます。 Hadoop 互換のデータストレージとして利用できるため、データの取り込みやデータフロー設計の構築が可能です。
【関連記事】 Azure Data Factory とは?さまざまなデータの連携や統合管理をクラウドで実現
Azure Data Lake Storage Gen2 導入時のポイント・注意点
ここでは、Azure Data Lake Storage Gen2 の導入時に考慮すべきポイントについてご紹介します。
設計段階でのストレージ階層構造・命名規則
ストレージの階層構造やファイル名の命名規則を以下のように適切に設計することで、運用がスムーズになります。
- 階層構造の設計 冗長であってもわかりやすいディレクトリ構造を採用することで、運用やデータ検索が効率化されます。 例えば、年別・月別フォルダを設定することで、特定期間のデータを簡単に特定することができます。
- 命名規則の標準化 ファイル名にタイムスタンプや識別子を含めることで、データ管理が容易になります。 例:「sales_2024_01.csv」。
セキュリティ・コンプライアンス要件
データの安全性を確保し、企業のコンプライアンス要件を満たすために以下の対策を行うことも重要です。
- データの暗号化 サーバーサイド暗号化(Azure が自動でデータを暗号化)やクライアントサイド暗号化(データの保存前にクライアント側で暗号化)を行うことで、さらにセキュリティを強化しましょう。
- アクセス制御(RBAC・ACL 設定) Role-Based Access Control(RBAC)や Hadoop 互換 ACL を使用して、必要な権限のみをユーザーやグループに割り当てることで、不正アクセスを防ぎます。
パフォーマンス最適化
大量データを効率的に処理するために、パフォーマンスを最適化する以下のような工夫が必要です。
- スケーリング戦略 複数のストレージアカウントを使用して負荷を分散し、大量ファイルへの同時アクセスに対応します。
- 列指向フォーマットの活用 Parquet や ORC などの列指向フォーマットを使用することで、読み書き速度を向上し、ストレージ使用量を削減します。
Azure Data Lake Storage Gen2 のユースケース
Azure Data Lake Storage Gen2 は、多様なユースケースに対応できる柔軟なデータストレージサービスです。
ここでは、想定されるユースケースをご紹介します。
製造業における IoT データの管理と異常検知
例えば、工場内の IoT センサーから収集したデータを活用する場合、以下のような課題が生じます。
【課題】
- データ量増加でオンプレミスの管理が限界。
- 分析用データの抽出・統合に時間がかかる。
- 異常検知アルゴリズムのリアルタイム性不足。
そのような場合 ADLS Gen2 を導入し、データを階層型名前空間で整理しつつ、リアルタイム分析を Azure Stream Analytics や Azure Databricks で実施することで、以下の効果が得られるでしょう。
【効果】
- コスト削減:オンプレミス保管コストを約 30%削減。
- 効率化:異常検知の反応時間を大幅に短縮。
- 稼働率向上:設備ダウンタイムを 20%低減。
小売業における顧客データの統合とマーケティング
例えば、小売企業が複数のチャネル(POS、EC、ロイヤルティプログラム)から収集するデータが分散している場合、次のような課題が生じます。
【課題】
- 顧客の購買行動を全体的に把握できない。
- パーソナライズされたマーケティングが困難。
ADLS Gen2 を基盤として Azure Data Factory でデータを統合し、Synapse Analytics や Machine Learning を活用することで、以下のような効果の実現が考えられます。
【効果】
- 収益向上:パーソナライズキャンペーンの効果がアップ。
- 統合効率化:データ統合時間の短縮。
- 顧客満足度向上:ターゲットを絞った施策により満足度が改善
金融業における取引データの分析と不正検知
例えば、大量の取引データを処理する金融機関で、不正検知に以下の課題が生じたとします。
【課題】
- データ量が膨大でモデルトレーニングが非効率。
- 異常検知の遅れによるリスク増加。
ADLS Gen2 に取引データを保存し、Parquet 形式で効率化します。Azure Databricks と Event Grid を活用し、以下を実現することができます。
【効果】
- 検知率向上:不正検知率の向上。
- 処理速度改善:モデルトレーニング時間の削減。
- リスク削減:新たな不正パターンへの迅速対応。
公共機関での気象データの長期保管と分析
例えば、気象データの長期保存と分析を行う場合、以下の課題が想定されます。
【課題】
- 過去データの検索に時間がかかる。
- 大量データの保管コストが高い。
ADLS Gen2 を活用し、CSV を Parquet 形式に変換して保存し、Synapse Analytics と Machine Learning で災害リスク予測を実施すれば以下の効果が期待できます。
【効果】
- 検索効率化:クエリ時間の短縮。
- コスト削減:保管コストの削減。
- 公共サービス改善:予測精度向上による迅速な対応。
まとめ
本記事では、Azure Data Lake Storage Gen2 の概要、特徴、活用事例、導入手順、料金体系などについてご紹介しました。
Azure Data Lake Storage Gen2 は、大容量データの分析や管理に特化した Azure ストレージサービスであり、Hierarchical Namespace と Hadoop 互換のセキュリティ機能が特長となっています。 さらに、Azure Databricks、Synapse Analytics、HDInsight などのデータ分析サービスと連携することで、データの収集、格納、分析、視覚化までのプロセスを統一的に管理できます。
Azure Data Lake Storage Gen2 を導入することで、膨大なデータの効率的な管理と分析基盤の構築を実現してください。データ活用に基づく迅速で的確な意思決定が可能となり、業務効率の向上や競争力の強化といった効果が期待できるでしょう。
東京エレクトロンデバイスは、Azure の企業導入をサポートしています。Azure を活用したシステム構築、データ分析基盤の構築、クラウド移行など、お客様の課題や目的に合わせて幅広く支援いたします。
無料相談も受け付けておりますので、お気軽にご相談ください。



