
Azure AI Search とは
Azure AI Search は、企業が大量のデータを効率よく検索・分析できる、フルマネージドの AI ベースの検索サービスです。
以前は「Azure Cognitive Search」として提供されていましたが、名称変更に伴い、AI 機能も強化されています。
従来のキーワードベースの検索エンジンとは異なり、Azure AI Search は AI を活用することで、単にキーワードを探すだけでなく、コンテキストを理解し、意味に基づいた高度な検索が可能です。
Azure AI Search の処理フロー
まず、Azure AI Search の処理フローついて説明します。
以下の図は、Azure AI Search を使用したデータ処理の流れを 3 つの主要なステップで示しています。
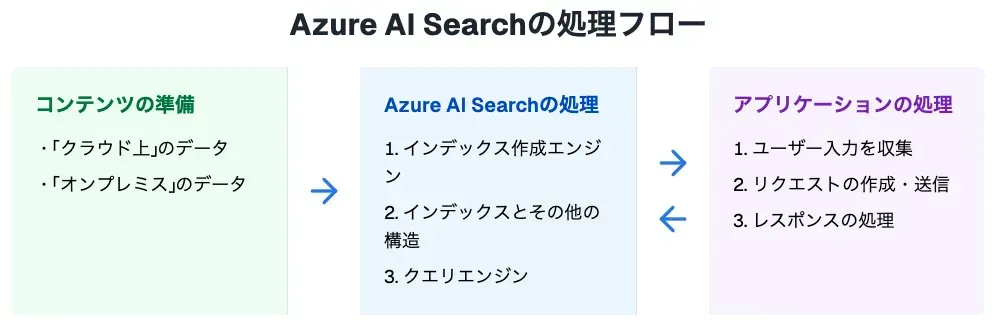
1. コンテンツの準備 (緑色)
Azure AI Search は、様々なソースからデータを取り込むことができます。この段階では、検索対象となるデータが準備されます。
- 「クラウド上」のデータ:Azure Blob Storage、Azure SQL Database などに格納されたデータ。
- 「オンプレミス」のデータ:企業の内部サーバーやデータセンターに保存されたデータ。
これらのデータは、Azure AI Search のインデックス作成プロセスの入力として使用されます。
Azure AI Search の処理 (青色)
この段階では、準備されたデータが実際に処理され、検索可能な形式に変換されます。
1.インデックス作成エンジン:データを解析し、全文検索用のインデックスを生成します。
2.インデックスとその他の構造:生成されたインデックスと関連メタデータを保存します。
3.クエリエンジン:受信した検索クエリを処理し、関連性に基づいて結果を返します。
収集されたデータは、インデックス作成エンジンによって処理され、効率的に検索できる形式に変換されます。
作成されたインデックスは保存され、クエリエンジンによって高速に検索されます。
アプリケーションの処理 (紫色)
ユーザーインターフェースと Azure AI Search 間の相互作用が行われます。
- ユーザー入力を収集:ウェブインターフェースやアプリケーション UI を通じて検索クエリを受け取ります。
- リクエストの作成・送信:受け取ったクエリを Azure AI Search API に適合する形式に変換し、送信します。
- レスポンスの処理:Azure AI Search から返された検索結果をユーザーインターフェースに表示します。
各ステップの間には青い矢印が描かれており、データが左から右へと流れていく様子を表しています。この流れに沿って、データは準備され、処理され、最終的にユーザーに結果として提示されます。
Azure AI Search の特徴
ここでは、Azure AI Search の特徴について説明します。
従来の検索エンジンとの違い
Azure AI Search は検索サービスであることから、従来の検索エンジンと何が違うのかと思われる方も多いかと思います。その違いとは次のような点にあります。
1. 意味理解
単純なキーワード一致ではなく、言葉の意味や文脈を理解して検索することができます。
たとえば、従来の検索エンジンは「車の運転」と「運転手」という 2 つのキーワードを、まったく別物として扱います。
一方、Azure AI Search では、「車の運転」というフレーズを見た時に、それが「運転手」という言葉と意味的に関連していると紐づけられるのです。
そのため、ユーザーが入力したキーワードに近い関連概念も高精度で検索できます。
2. AI 技術の活用
自然言語処理や画像認識、感情分析を使い、より高度な検索が可能です。画像の内容やテキストの感情まで分析できます。
パーソナライズ
ユーザーの検索履歴や閲覧データをもとに、個々に最適な検索結果を調整して、表示することができます。ユーザーの行動パターンに応じてクエリやスコアリングをカスタマイズし、興味や好みに合わせたパーソナライズされた検索体験を実現します。
4.多様なデータに対応
構造化データと非構造化データの両方を効率的に検索できます。さまざまなデータソースから統合された結果を提供します。
- 構造化データ(例:データベースやスプレッドシートの表形式データ)は、行や列などのフィールドごとに整理されたデータです。Azure AI Search では、このようなデータに対してフィールドごとの正確な検索や並べ替えが可能です。
- 非構造化データ(例:テキスト、PDF、画像、音声ファイル)は、決まった形式や構造がないデータです。Azure AI Search は、これらのデータに対して内容の意味解析や特徴抽出を行い、検索可能な形に変換します。
これにより、例えば顧客情報データベース(構造化)と顧客とのメールのやり取り(非構造化)を同時に検索対象とし、総合的な顧客対応履歴を一度の検索で取得できるようになります。
Azure AI Search は、このようなデータの多様性に柔軟に対応し、ユーザーに統合された洞察を提供します。
Azure Cognitive Search からの進化
Azure AI Search は、以前の Azure Cognitive Search から進化したサービスです。
AI 機能が大幅に強化され、さまざまな活用シーンに対応するため、名前が変更されました。主な変更点は次の通りです。
主な機能拡張
- ベクトル検索の導入:テキストや画像を数値に変換し、意味的に似た内容をより高度に検索できます。
- 自然言語理解の強化: 複雑なクエリや曖昧な質問にも対応できるようになりました。
- マルチモーダル検索の改善: 画像や音声を理解する能力が向上し、統合的な検索が可能です。
Azure OpenAI Service との統合
より自然な会話型の検索や、複雑な質問に対して自動で最適な検索方法を選択できるようになりました。
こうした進化により、Azure AI Search は、企業のデジタルトランスフォーメーションを促進するより重要なツールとなっています。
Azure Open AI Service ついては、以下の記事をご覧ください。
Azure OpenAI Service とは?主な特徴や使い方、ChatGPT との違いについて解説
Azure AI Search の主要機能
では、次に Azure AI Search の主要機能である、「3 種類の検索機能」と「インデックス化」についてご紹介します。
3 種類の検索機能
Azure AI Search では、「フルテキスト検索」、「ベクトル検索」、「セマンティック検索」という 3 つの検索機能が提供されています。
1.フルテキスト検索
フルテキスト検索は、従来型のキーワードベースの検索のことです。
ユーザーが入力したクエリに基づき、データベースに保存されたドキュメント全体から一致するテキストを見つけ出します。
【例】
EC サイトで「赤い T シャツ」と検索した場合、「赤い T シャツ」と記載されている商品がヒットします。
キーワードそのものがデータに含まれている場合には正確にヒットしますが、キーワードが異なる場合や表現が違うと、例えば「赤のシャツ」と書かれた商品は見逃される可能性があります。
2. ベクトル検索
ベクトル検索とは、データをベクトル化し、類似性を基に検索する方法です。
- ベクトル化:データやクエリをベクトル(数百個の数字のセット)に変換します。
- 類似性の計算:その数値が「どれだけ似ているか」を比較します。
このようなベクトル検索をすることで、文章に使われている言葉が違っても、意味が似ているものを見つけることができます。
【例】
赤い T シャツを検索する場合について考えてみましょう。
この「赤い T シャツ」というクエリ(検索したい内容)をベクトルに変換すると、
たとえば [0.3, 0.5, 0.2] のようなベクトルになります。
そして、検索対象の 2 つの文書はそれぞれ以下のようなベクトルを持っているとします。
- 「青いシャツ」について書かれた文書 1 → ベクトル [0.2, 0.4, 0.3]
- 「赤いシャツ」について書かれた文書 2 → ベクトル [0.29, 0.51, 0.21]
結果:
- 文書 1 のベクトルはクエリとは異なりますが、「シャツ」という点で関連性があります。
- 文書 2 のベクトルはクエリのベクトルと非常に近く、意味的にも「赤いシャツ」と類似しています。
最終的な検索結果として、「赤いシャツ」についての文書 2 が最も類似性が高いと判断され、上位に表示されます。
ベクトル検索はこのように、単語そのものではなく、意味の類似性に基づいて検索結果を提供します。
3. セマンティック検索
セマンティック検索は、単語やフレーズの意味を理解して検索結果を提供する高度な検索機能です。
セマンティック検索には、主に自然言語処理(NLP)やディープラーニングが活用されており、文脈の理解やユーザーの意図理解などが可能となっています。
【例】
ユーザーが「赤い T シャツ」と検索した場合、ユーザーの検索背景や意図を考慮し、「秋に合う T シャツ」や「最新のデザイン」といった関連する商品や提案も表示されます。
つまり、単純なキーワードの一致にとどまらず、コンセプトや関連カテゴリも反映することができるのです。
3つの検索機能の比較
このように、それぞれが異なる目的で活用できるため、システムや検索要件に応じて使い分けることが重要となります。
検索機能 | フルテキスト検索 | ベクトル検索 | セマンティック検索 |
|---|---|---|---|
検索基準 | キーワードの一致 | 商品の視覚的特徴や物理的な類似性 | 図や文脈の理解、意味的な関連性 |
例 | 「赤い T シャツ」と記載されている商品 | 色や形が「赤」や「T シャツ」に似ている商品 | 赤い T シャツ」に関連するカテゴリや季節、スタイルなどの提案 |
利点 | 明確なキーワードに基づく精度の高い結果を返す | 外見や物理的な類似性に基づいて幅広い商品を発見できる | 意図や文脈に基づいて関連性の高い提案を行う |
欠点 | 表現が異なると見逃すことがある | 意味的な関連性は考慮されない | 検索結果が広がりすぎてピンポイントの商品を見つけにくいことがある |
また、Azure AI Search には、フルテキスト検索とベクトル検索を組み合わせたハイブリッド検索や、セマンティック検索とベクトル検索を組み合わせたセマンティックハイブリッド検索といった高度な検索機能も用意されています。
こうした機能を活用することで、さらに精度の高い検索結果を提供できるようになります。
インデックス化
インデックス化は、取り込んだデータを効率よく整理して検索可能にするプロセスです。
Azure AI Search のインデックス化には、いくつかの高度な特徴があります。
1. データの自動インデックス化
Azure AI Search は、データソースから取り込んだ情報を自動的にインデクサーによってインデックス化します。
この機能により、データが追加・更新されるたびにインデックスがリアルタイムで更新され、常に最新のデータが検索可能な状態となります。
2. AI を活用したデータ処理
インデックス化の過程で、AI エンリッチメント機能が使われ、OCR や翻訳などの AI 技術で画像や非テキストデータも処理されます。
つまり、テキストだけでなく、PDF や画像から抽出されたデータも検索可能となるのです。
3. スキーマ設定によるカスタマイズ
インデックスのスキーマ設定により、どのフィールドを検索対象にするか、どのデータを並べ替えやフィルタに使用するかをカスタマイズできます。
そのため、データ構造に合わせて最適な検索ができるインデックスを作成することができます。
このように Azure AI Search のインデックス化は、AI 技術を活用した高度な検索機能を備えており、他の検索エンジンとは一線を画す特徴を持っています。
Azure AI Search を使った RAG(Retrieval-Augmented Generation)
次にこのセクションでは、独自データへの回答を可能にする Azure AI Search を使った RAG の仕組みについて説明します。
RAG とは
RAG は、検索と生成の 2 つのアプローチを統合した手法で、大規模言語モデル(LLM)が外部のデータソースからリアルタイムに情報を取得し、その情報を元に精度の高い回答を生成します。
従来の LLM は、事前にトレーニングされたデータセット内の知識に依存していましたが、RAG は新しい情報にアクセスできるため、最新の状況や動的なコンテンツに対する応答が可能です。
RAG の仕組み
具体的な活用場面を用いて、Azure AI Search を使った RAG の仕組みをご紹介します。
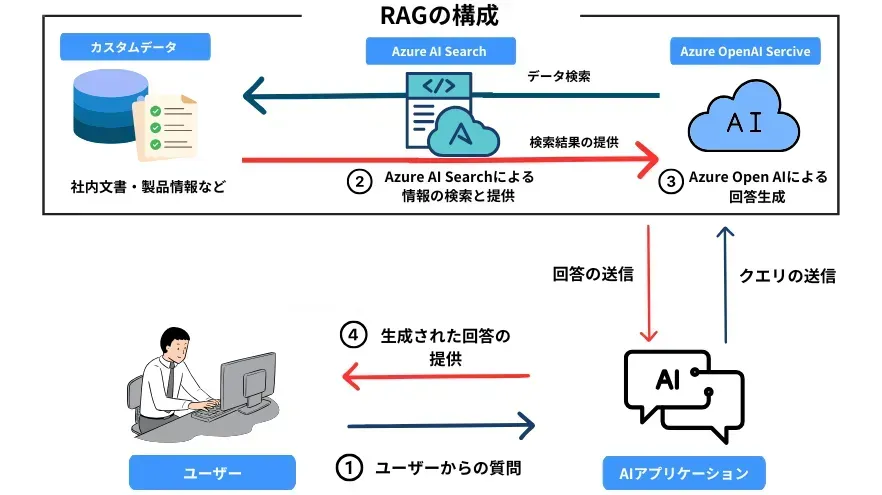
RAG の仕組み
1. ユーザーの質問
ユーザーは、例えば「最新の AI 技術トレンドについて教えてください」といったクエリを、AI 対応のアプリケーション(例: Microsoft Teams やチャットボットなど)を通じて入力します。
このクエリは、単にキーワードマッチングを行うのではなく、文脈的な意味も考慮されるべきです。
2. Azure AI Search による情報の検索と提供
クエリが受信されると、Azure AI Search はインデックス化された社内ドキュメント、FAQ、データベース、API レスポンスなどの複数のデータソースを横断的に検索し、最も関連性の高い情報を抽出します。これは RAG の情報検索フェーズにあたります。
Azure AI Search の特長は、自然言語処理(NLP)や意味的ベクトル検索を駆使し、文脈的な意味を理解して情報を提供する点です。
3. AI による回答生成
次は生成のフェーズです。検索されたデータが「Azure OpenAI Service」に渡され、「Azure OpenAI Service」は、利用者からの質問と検索されたデータを基に回答を生成します。
生成プロセスでは、LLM が事前トレーニングされた知識に加え、検索された最新の情報を組み合わせて文脈に合った自然言語の回答を生成します。
4. 生成された回答の提供
生成された回答は、AI アプリケーション(Microsoft Teams など)を通じて利用者に返され、利用者がみている画面に表示されます。
このプロセスでは、生成された情報がユーザーに提示されるだけでなく、応答の品質を評価するフィードバックループを導入することで、さらにモデルを改善することも可能です。
つまり、Azure AI Search を RAG に活用することで、高速かつ高精度な検索能力によって、リアルタイムで最新の情報を AI に提供できるため、より正確で関連性の高い回答を生成できるのです。
Azure における RAG を用いた自社データの活用方法は Azure OpenAI On Your Data の解説記事をご覧ください。
Azure AI Searchの最新機能:エージェント検索(Agentic Retrieval)
2025年5月、Azure AI Searchは従来のRAGをさらに進化させた新機能「エージェント検索(Agentic Retrieval)」をパブリックプレビューとして発表しました。
これは、複雑な質問に対してAIエージェント自らが検索プランを立てて実行する、マルチターン型の自動化されたクエリエンジンです。従来の単発的なRAGと比較して、複雑な質問への回答の関連性を最大40%向上させることができます。
エージェント検索の仕組み
- クエリの計画と分解
LLMがユーザーとの対話履歴全体を分析し、一つの複雑な質問を、より焦点を絞った複数のサブクエリに自動で分解します。 - ハイブリッド検索の並行実行
分解された各サブクエリを、テキストフィールドとベクトル埋め込みの両方で同時に並行して実行します。これにより、キーワードの一致と意味的な類似性の両方を一度に捉え、高い再現率で情報を収集します。 - 結果の再ランク付けと統合
すべてのサブクエリから得られた結果を、Azure AI Searchのセマンティックランカーを使って再ランク付けし、最も関連性の高い情報を統合して、一貫性のある単一の回答データとして提供します。また、構造化された参照メタデータも併せて返されます。 - アクティビティログの提供
検索プロセスの各ステップ(生成されたサブクエリ、トークン数、ヒット数、適用されたフィルター、実行時間など)の詳細なログが提供され、検索の挙動を透明化し、関連性の問題を迅速にトラブルシューティングできます。
エージェント検索は、単純な情報検索(Retrieval)から、AIエージェントが自律的に思考し、多段階の検索戦略を実行する「知識獲得(Knowledge Retrieval)」へと、検索のあり方を大きく進化させる機能といえます。
Azure AI Search の使い方
さて、ここからは Azure AI Search の構築手順について段階的に説明していきます。
全体の流れは以下の通りです。
- Azure AI Search リソースの作成
最初に Azure ポータルで AI Search のリソースを作成します。
- インデックスの作成
インデックスを作成して、検索対象データのフィールドを定義します。ここで検索可能な項目(フィールド名、データ型、属性など)を決めます。
- データソースの接続
Azure AI Search は多様なデータソースと接続できます。
主な接続先には以下のようなものがあります。
- Azure Cosmos DB: グローバル分散が可能なスケーラブルなマルチモデルデータベースで、大規模 NoSQL データ(ドキュメント、キー/バリュー、グラフ、列指向など)を扱うことができる。
- Azure Blob Storage: 非構造化データ(ドキュメント、画像など)の格納に適したスケーラブルなオブジェクトストレージ。
- Microsoft Fabric OneLake: Microsoft Fabric の一部であり、大規模データレイク向けに設計されたデータストレージサービス。複数のデータソースからの統合と分析をサポート。
- SharePoint Online: 企業内ドキュメントやリストデータの管理用のプラットフォーム。
- その他: Azure SQL Database 、MySQL、PostgreSQL、Azure Table Storage など
これらのデータソースを接続することで、企業内外の様々なデータを一元的に検索可能にします。データソースの選択は、データの種類、量、更新頻度、セキュリティ要件などを考慮して行います。
Azure AI Search で利用可能なデータソースはこちらからご確認ください。
- インデクサーの追加
データソースからインデックスに自動的にデータを取り込むインデクサーを追加します。これにより、定期的な更新や自動データ取得が可能となります。
- スキルセットと AI 強化
必要に応じて AI スキルを追加し、テキスト分析や画像認識などを使ってデータを強化します。
前提条件
前提として、以下の条件が満たされている必要があります。
- Azure のサブスクリプションとリソースグループが既に作成済み。
- データ保管用のストレージとコンテナ作成済み(コンテナにデータを保存しておきます。)
Azure AI Search リソースの作成
まず、Azure AI Search リソースを作成します。
- Azure ポータルにログインし、検索バーに「AI Search」と入力して、検索結果から選択します。
AI Search 検索画面
- 「+ 作成」ボタンをクリックします。
AI Search 作成ボタン
- 次の情報を入力します。
- リソースグループ
- 検索サービス名
- リージョン
- プランや価格設定の選択
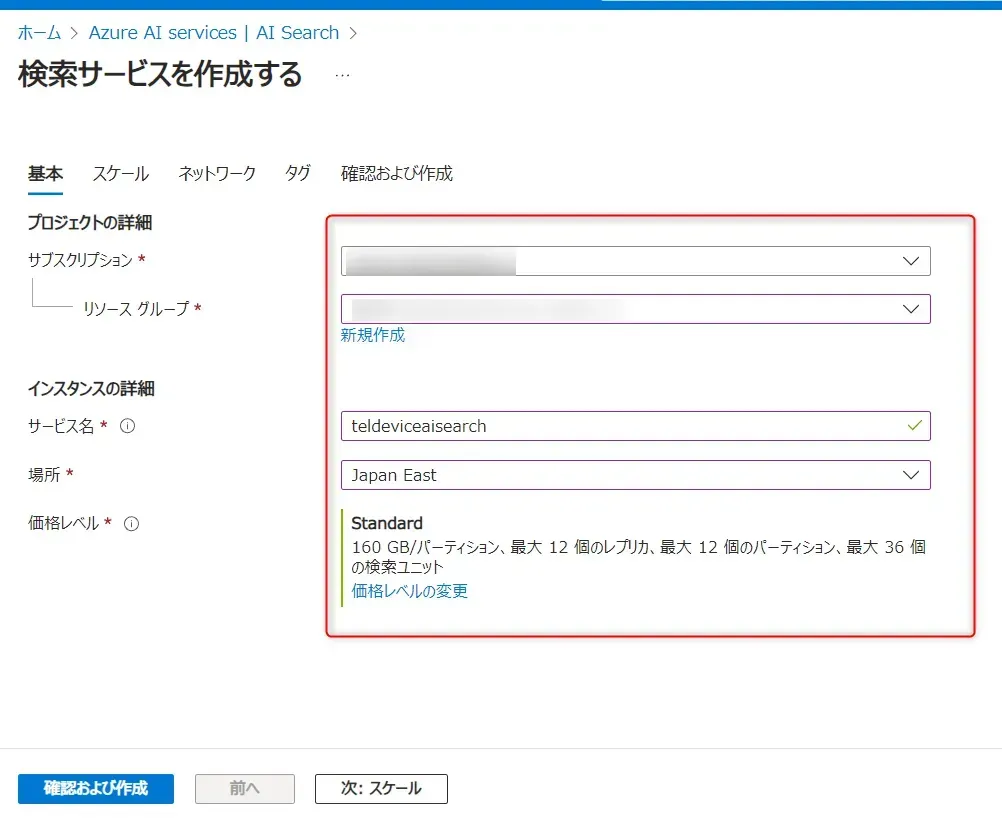
検索サービス作成の入力画面
- 設定の確認と作成
「確認および作成」画面で設定を確認し、「作成」をクリックします。
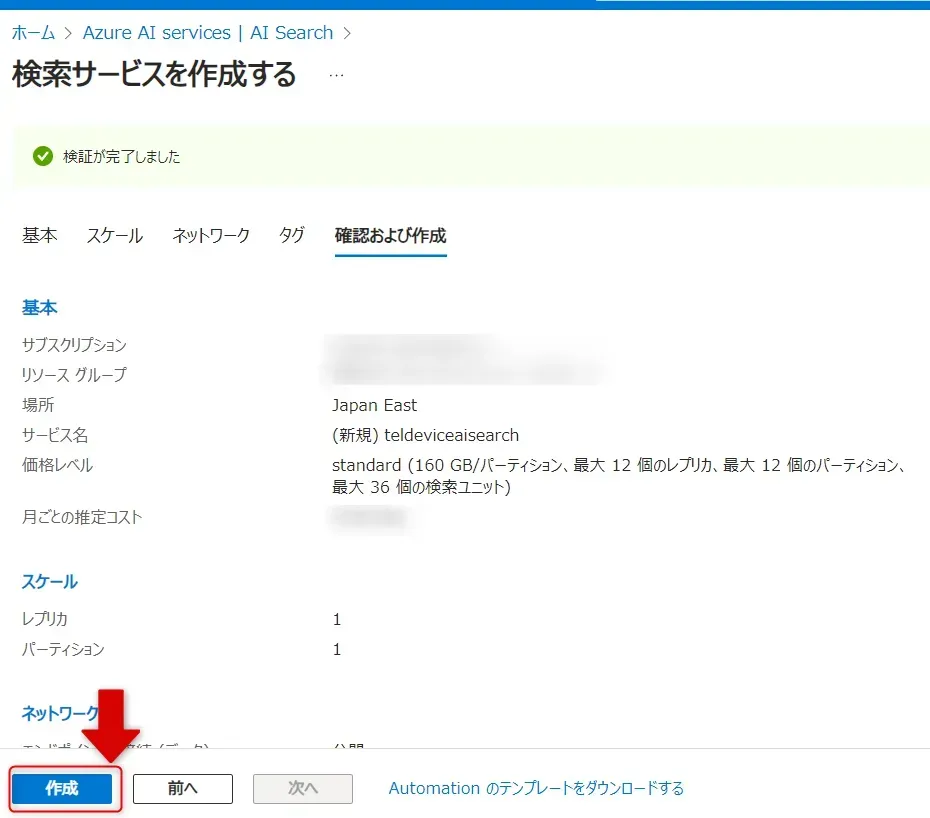
検索サービスの作成ボタン
これで検索リソースが作成されました。
インデックスの作成
ここからは、インデックスを作成していきます。
インデックスとは、「検索対象として整理できるデータの種類や範囲」を定義するものです。
たとえば、会社が「製品情報、顧客情報、技術マニュアルといった複数のデータベース」を持っている場合、それぞれがインデックスに対応します。
インデックスを通じて、どんな項目をどんな風に検索できるかを定義するという訳です。
- Azure ポータルで先ほど作成した Azure AI Search サービスの「+インデックスの作成」を選択します。
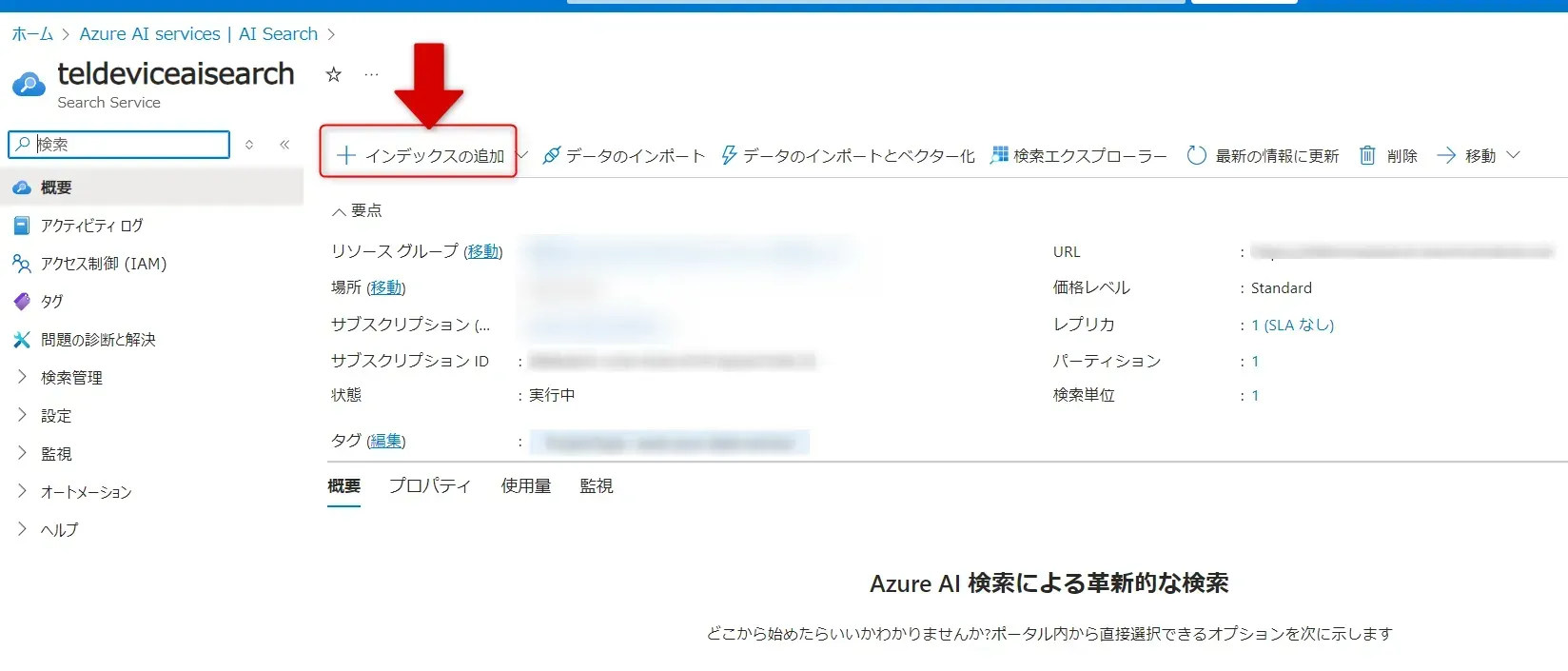
インデックスの追加ボタン
- この画面でインデックスに含めるフィールド(項目)を設定していきます。
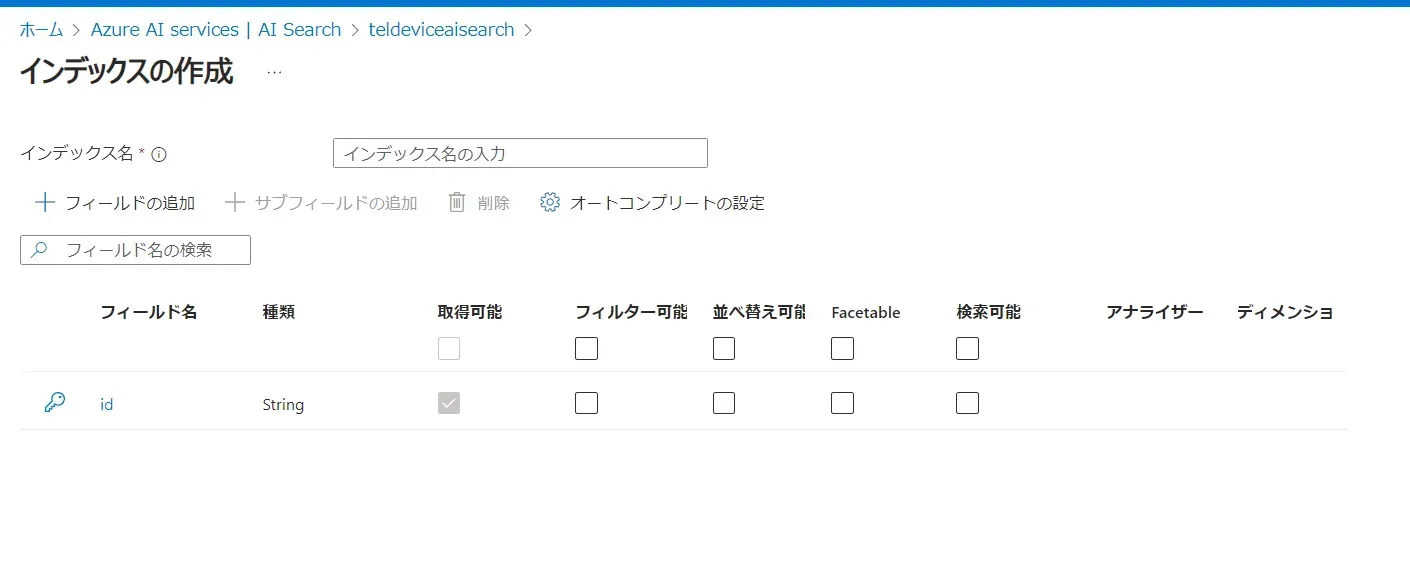
インデックスの作成設定画面
- フィールドの追加をクリックして、各フィールドを設定します。
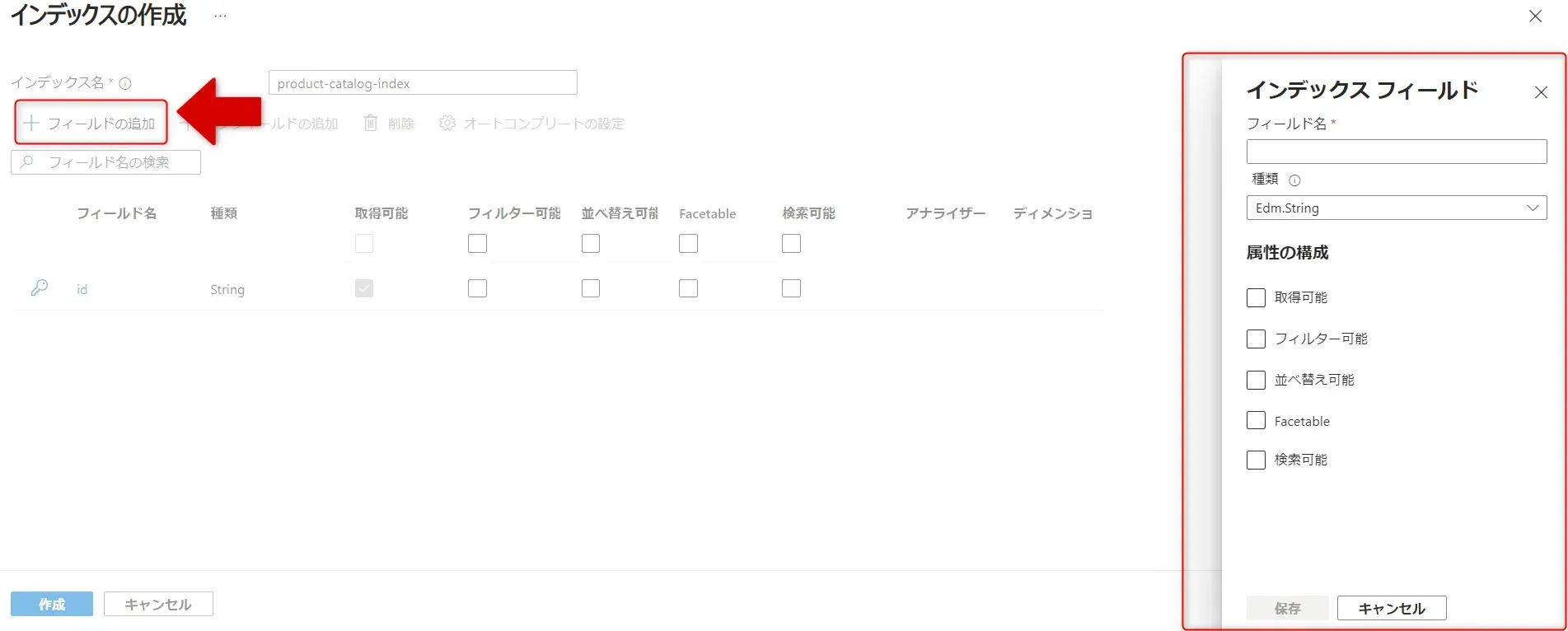
インデックスフィールド画面
項目 | 説明 |
|---|---|
フィールド名 | データを識別するための名前です。各フィールドに一意の識別子を付けます。 |
種類 | データの型を指定します。例えば、文字列(テキストデータ)、数値、日付などがあります。 |
取得可能 | 検索結果として、このフィールドの値を表示するかどうかを設定します。 |
フィルター可能 | 検索結果を絞り込むために、このフィールドを使うかどうかを設定します。例:「価格 1,000 円以下」など。 |
並べ替え可能 | 検索結果をこのフィールドを基に昇順や降順に並べ替えるかどうかを設定します。例:「価格の高い順」など |
Facetable | 検索結果を特定の条件でグループ化できるかどうかを設定します。例:「カテゴリ別」「メーカー別」など。 |
検索可能 | このフィールドを検索対象にするかどうかを設定します。例:商品説明などのテキストを検索対象に含める。 |
- 「作成」ボタンをクリックします。
インデックスを正しく設計することで、検索性能や結果の質に大きな影響を与えることができます。
データソースの接続
データソースを接続することで、Azure AI Search は外部のデータストレージから情報を取得し、そのデータをインデックスに登録できます。
今回は、「Azure Blob Storage」をデータソースとして設定します。
- Azure AI Search サービスのリソースページの、サービスの左メニューから「データソース」を選択し、ページ上部にある「+データソースの追加」ボタンをクリックします。
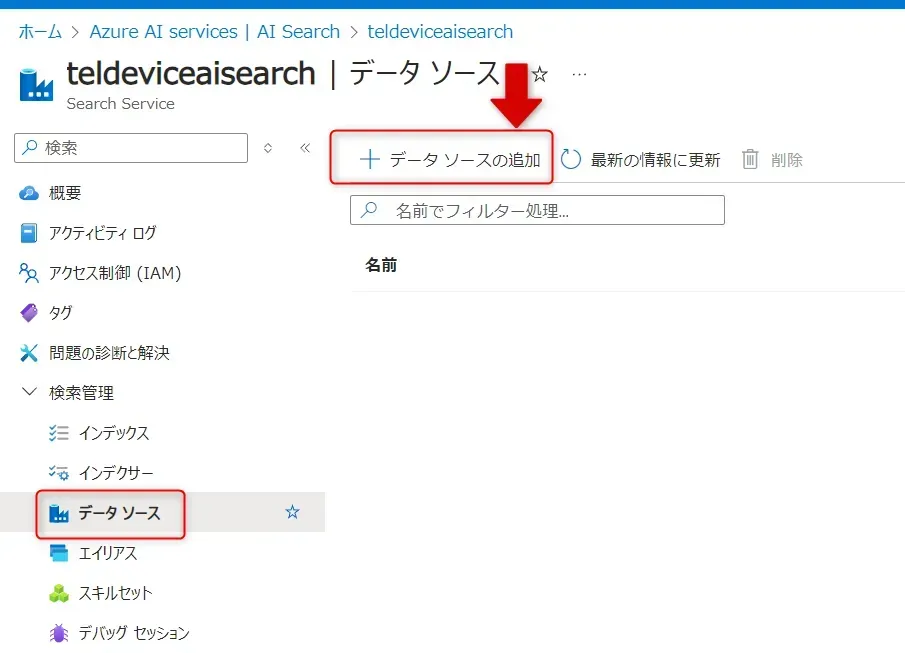
データソースの追加ボタン
- データソースの追加画面が現れるので、以下の事項を入力します。完了したら、「保存」をクリックします。
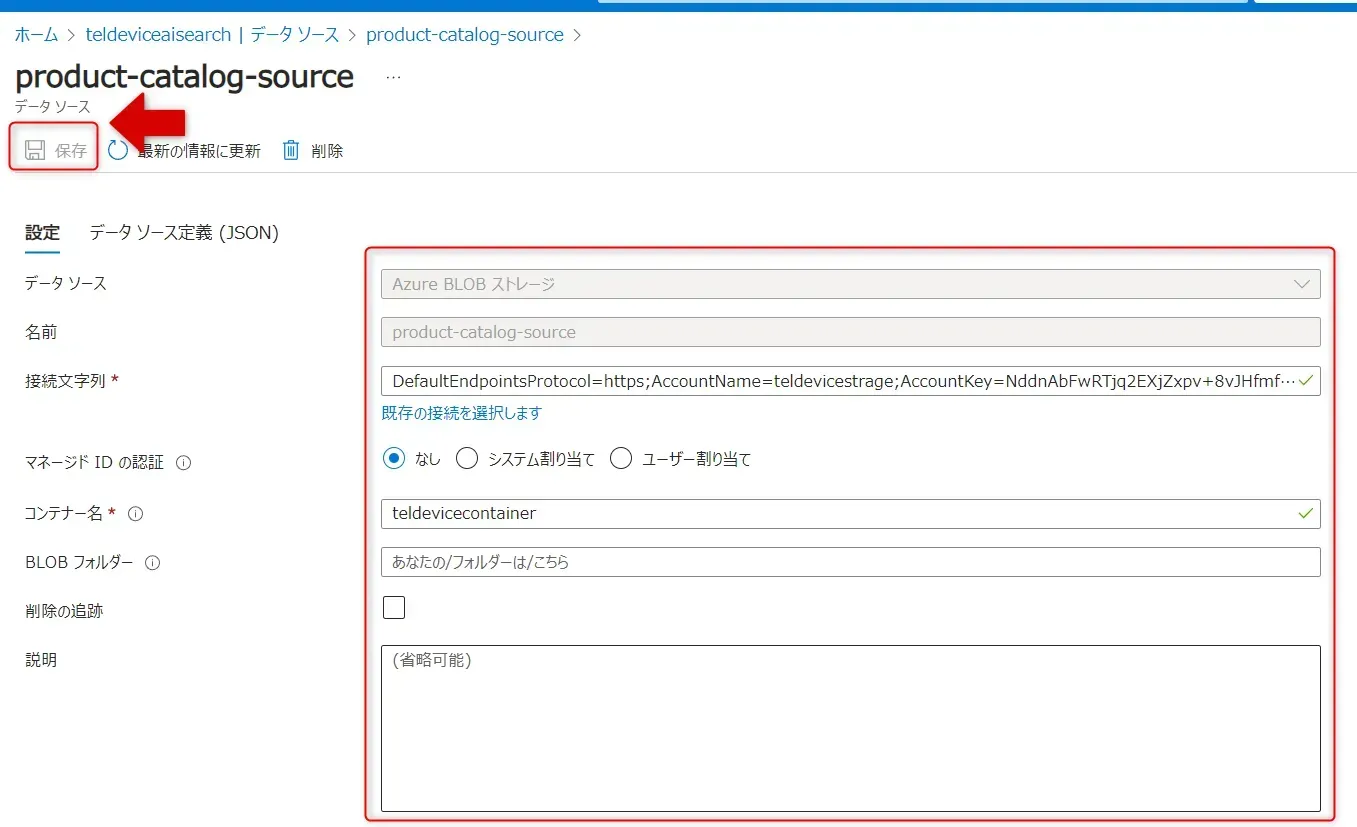
データソースの追加画面
- データソースの選択メニューが表示されるので、「Azure Blob Storage」を選択します。
- データソース名
- 接続文字列:Azure Blob Storage への接続文字列を入力します。これは Azure Storage アカウントの「アクセスキー」メニューから取得できます。
- Blob コンテナ名:データが保存されている Blob コンテナの名前を指定します。
インデクサーの追加
インデクサーはデータソース(例えば、Azure Blob Storage や Cosmos DB など)から定期的にデータを取得して、Azure AI Search のインデックスに追加・更新する役割を担ってくれるものです。
- Azure AI Search の左メニューに「インデクサー」という項目を選択し、「+ インデクサーの追加」を選択します。
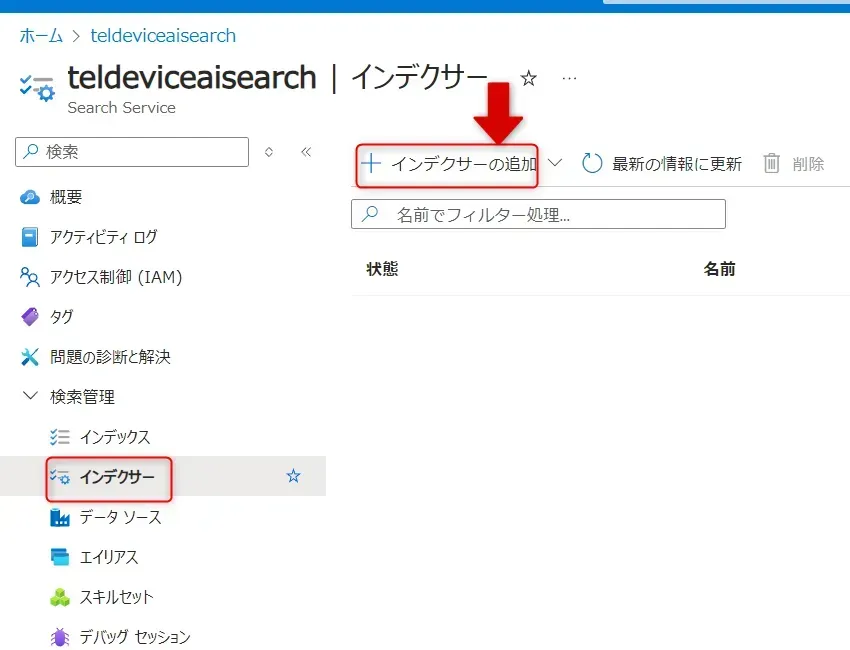
インデクサーの追加ボタン
- インデクサーの追加画面が現れます。
ここではインデクサーを設定する際に、インデックスにデータを取り込むタイミングや頻度(リアルタイム、スケジュール更新など)を指定することができます。
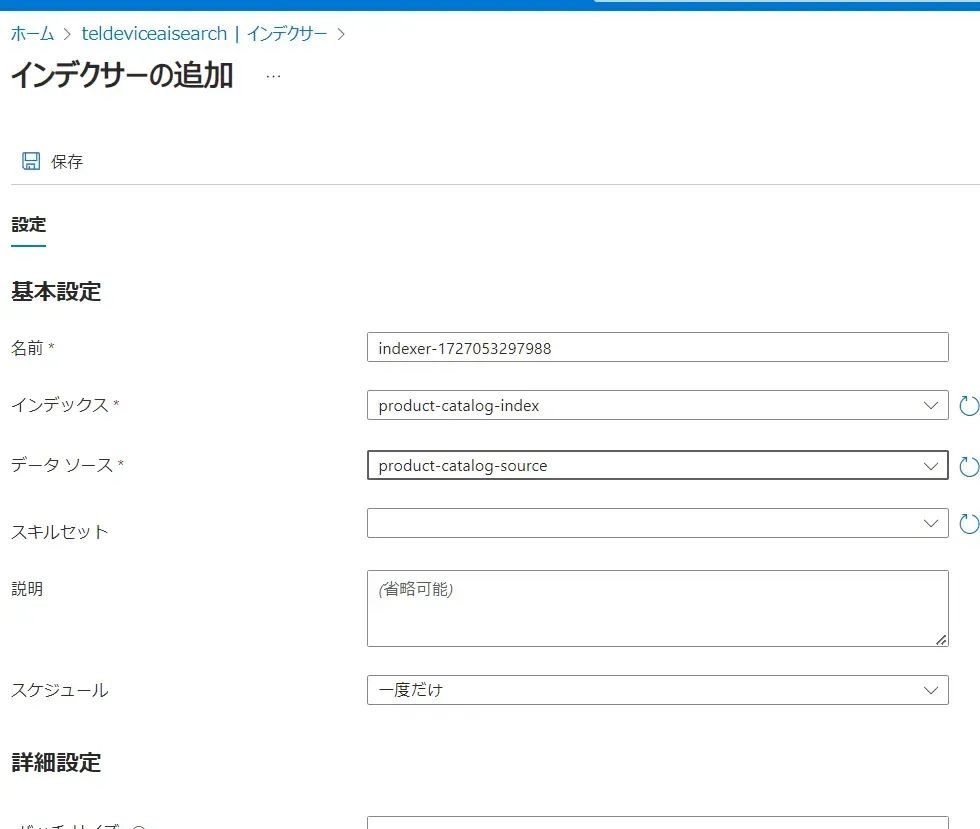
インデクサーの追加画面
- 入力したら、「保存」をクリックします。
スキルセットと AI 強化
Azure AI Search には、データを自動的に解析し、インデックスに追加する前に情報を補完する「スキルセット」という仕組みがあります。スキルセットを活用すると、AI を使ってテキストの分析や画像認識などが行えます。
- Azure AI Search の「スキルセット」メニューから「+スキルセットの追加」を選択します。
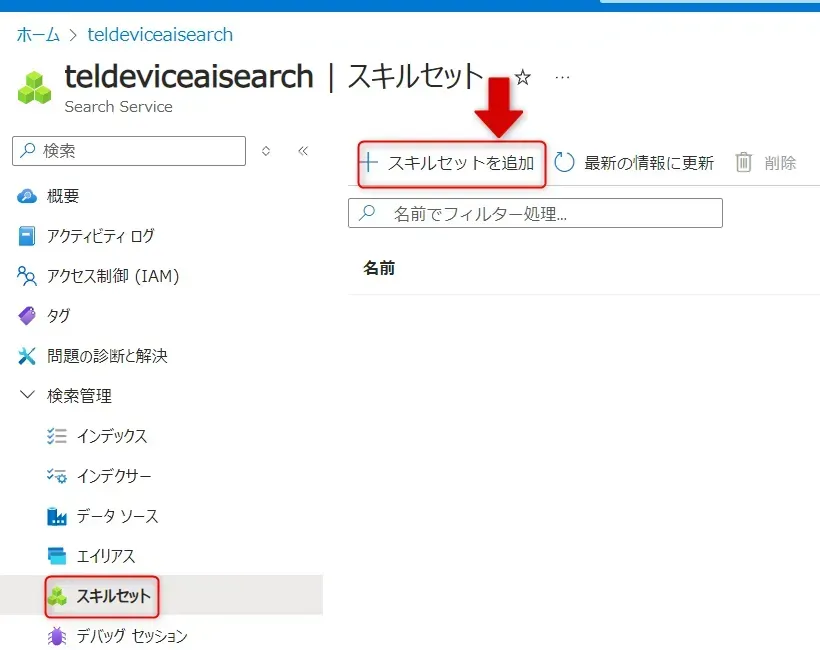
スキルセットを追加ボタン
- データに適用するスキルを右側の「スキル定義テンプレート」の「技能」から選びます。
たとえば、テキストからの感情分析や画像認識などがあります。
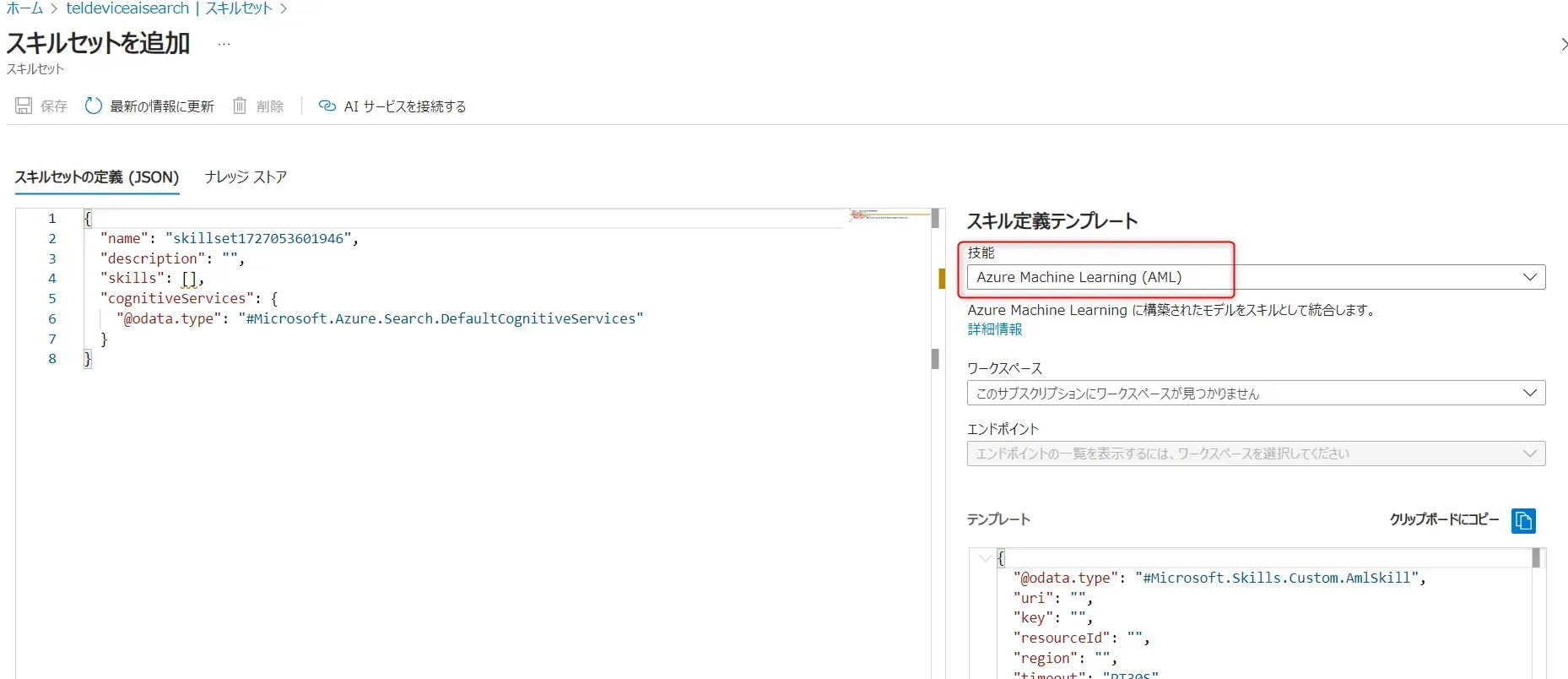
スキルセットを追加画面
- 「技能」を選択したら、「クリップボードにコピー」ボタンを押し、「スキルセットの定義」の skills の配列部分 [] の中に、テンプレートで生成されたスキル定義のコードをコピーします。
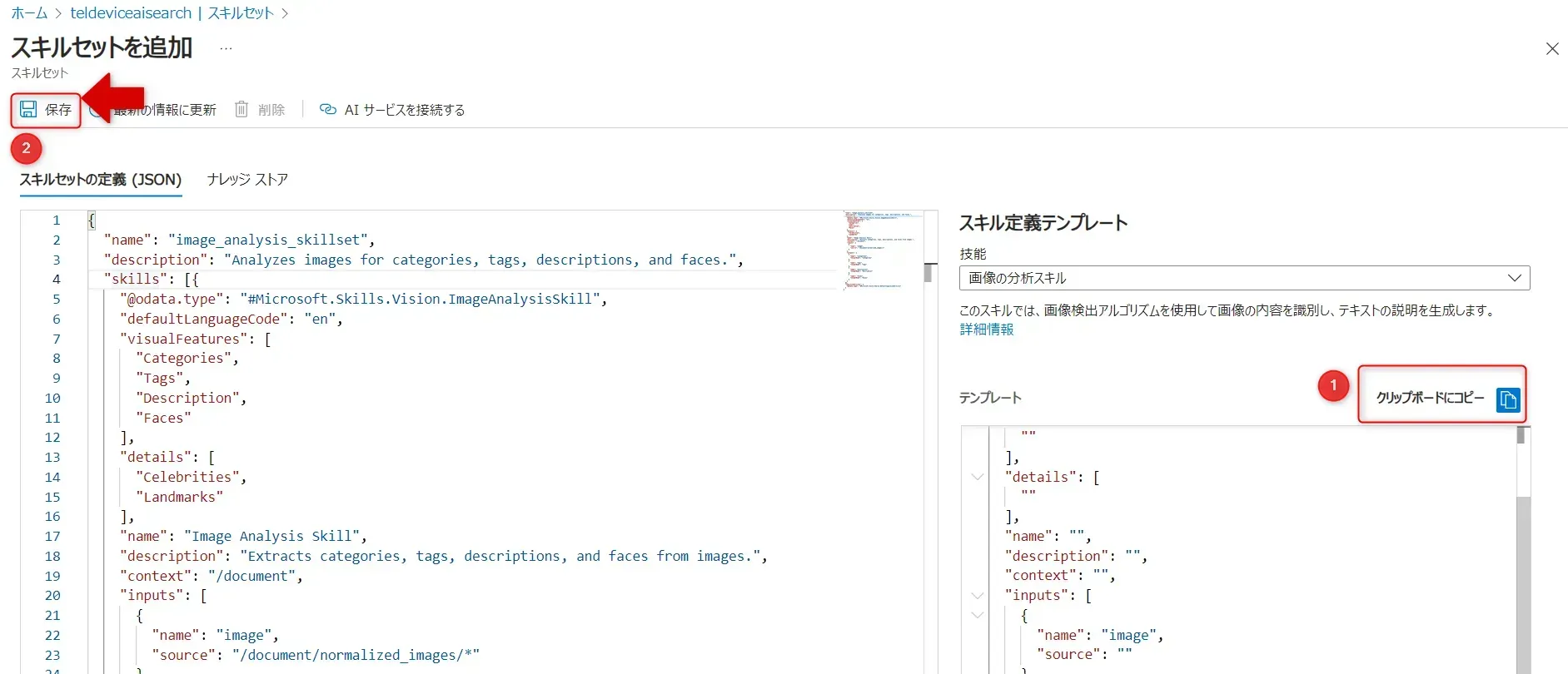
保存ボタン
入力が完成したら、「保存」をクリックします。
これでスキルセットを使用できるようになります。
Azure AI Search と他の Azure サービスとの連携
Azure AI Search は、Azure の他のサービスと緊密に連携することで、より便利で強力な検索システムを作ることができます。
Azure OpenAI Service との統合
Azure AI Search と Azure OpenAI Service 組み合わせると、以下ような高度な検索体験が実現できます。
- 質問の意味を理解: 複雑な質問でも、AI が意味を正しく理解して検索します。
- 検索結果を要約: 大量の検索結果を短くまとめてわかりやすく表示します。
- 質問に直接回答: 検索結果をもとに、AI がその場で質問に答えます。

Azure OpenAI Service イメージ
AI を利用する際は、結果の正確性、個人情報の保護、そして公平性の確保について、十分な検証を行うことが不可欠です。
Azure AI Services との連携
Azure AI Search と Azure AI Services を連携させることで、検索機能がさらに強化され、以下のような多様なデータタイプの高度な分析や理解が可能になります。
- Computer Vision: 画像の内容を理解し、分析。
- Speech Services: 音声の認識や合成を行う。
- Language Understanding: 自然言語を理解し、意図を解釈。
- Text Analytics: 感情分析、キーフレーズの抽出、エンティティ(固有名詞など)の認識を行う。

Azure AI Services イメージ
Azure AI Search の料金体系
Azure AI Search には、Free(無料)から Storage Optimized(大容量対応)まで幅広い料金プランが展開されています。
選択するプランによって、提供されるストレージ容量(Azure AI Search が保存できるデータの量)や機能が異なります。
(※2024 年 10 月現在の価格です。1USD = 144.515 JPY)
プラン | ストレージ | サービスあたりの最大インデックス数 | スケールアウトの制限 | SU (スケール ユニット) あたりの価格 |
|---|---|---|---|---|
Free | 50 MB | 3 | 該当なし | ¥0/時間 |
Basic | 15 GB (サービスごとに最大 45 GB) | 15 | サービスあたり最大 9 ユニット (最大 3 パーティション、最大 3 レプリカ) | ¥19.23/時間 |
Standard S1 | 160 GB (サービスごとに最大 1.9 TB) | 50 | サービスあたり最大 36 ユニット (最大 12 パーティション、最大 12 レプリカ) | ¥64.17/時間 |
Standard S2 | 512 GB (サービスごとに最大 6 TB | 200 | サービスあたり最大 36 ユニット (最大 12 パーティション、最大 12 レプリカ) | ¥256.37/時間 |
Standard S3 | 1 TB (サービスごとに最大 12 TB) | 200 または 1,000/高密度モードのパーティション | サービスあたり最大 36 ユニット (最大 12 パーティション、最大 12 レプリカ) | ¥513.32/時間 |
Storage Optimized L1 | 2 TB (サービスごとに最大 24 TB) | 10 | サービスあたり最大 36 ユニット (最大 12 パーティション、最大 12 レプリカ) | ¥554.80/時間 |
Storage Optimized L2 | 4 TB (サービスごとに最大 48 TB) | 10 | サービスあたり最大 36 ユニット (最大 12 パーティション、最大 12 レプリカ) | ¥1,109.45/時間 |
※HD モード(Standard S3 のみ):インデックス数を最大 1,000 まで増やせる特別なモード。
追加機能の料金
特定の追加機能を利用する場合は、使用量に応じて料金が発生します。
- カスタムエンティティ検出: データ内の特定の単語やフレーズを定義し、それを検出してラベル付けする機能。
- 画像の抽出: ドキュメントの中から画像を抽出して、検索可能にする機能。
- セマンティックランカー: AI を使って、ユーザーの検索内容に意味的に関連する結果を優先的に表示する機能。
※ 料金は変更される可能性があるため、最新の情報はMicrosoft の公式ドキュメントをご確認ください。
また、Azure OpenAI Service の料金体系はこちらをご確認ください。
まとめ
本記事では、Azure AI Search の包括的な概要と、企業における効果的な活用方法について詳しく解説しました。
Azure AI Search は、膨大なデータを持つ企業にとって、効率的なデータアクセスと分析を実現する強力な検索ソリューションです。単なるキーワードベースの検索を超え、自然言語処理(NLP)を活用してユーザーの検索意図を深く理解し、AI の力で意味ベースの検索やマルチモーダル検索をすることも可能です。今後の技術進化により、さらなる可能性が開かれていくことが期待され、ビジネスの成長に大きな貢献を果たすでしょう。
ぜひ Azure AI Search を効果的に活用することで、データ駆動型の意思決定と革新的なユーザー体験の創出を実現してください。
東京エレクトロンデバイスは Azure OpenAI Service をすぐにお試し頂ける環境(Try it! Azure OpenAI Service EXPRESS)を提供しています。
企業での Azure Open AI Service の活用、SaaS への導入など、Azure AI サービス開始にあたっての手続きから、ご利用時の技術サポートまでご支援いたします。
Azure OpenAI service の利用をご検討中の企業担当者様は、東京エレクトロンデバイスまでお気軽にご相談ください。



