

Microsoft FabricがBuild 2026で示した方向性
Microsoft Build 2026では、Microsoft Fabricに関する一連の新しい発表が行われました。これまでOneLakeを中核とした分析基盤として活用されてきたFabricの範囲が、Build 2026を経てアプリケーション開発、AIエージェントの実行基盤、ガバナンスといった領域へと広がっています。
特に注目すべき動きは、次の3点に整理できます。
- エージェント向けのセマンティック層の拡張(Fabric IQの機能追加)
- アプリケーション基盤としての強化(Fabric Apps、Rayfin)
- 分析エンジンの高速化(GPU高速化されたFabric Data Warehouse)
これらは個別の機能更新ではなく、Fabricを「データ × エージェント × アプリケーション × 分析 × ガバナンス」を支える複合プラットフォームへ拡張していく取り組みです。
本記事で扱うMicrosoft Fabricの主要トピック
Build 2026で発表されたFabric関連のアップデートは多岐にわたります。本記事で扱う主要トピックの位置づけを把握するために、まず主な発表項目を以下の表で整理します。
カテゴリ | 主な発表内容 | ステータス |
|---|---|---|
Fabric IQ | Creator Agent、Improved NL2SQL、Code Interpreter Tool、Cowork/Copilot Chat連携 | プレビュー/Frontier |
アプリ開発 | Rayfin SDKおよびCLI(Fabric Apps) | プレビュー |
データウェアハウス | Fabric Data Warehouse GPU高速化(CoddSpeedエンジン) | Early Access Preview(近日提供予定) |
エージェント | Operations Agents、Fabric Graph | 一般提供(GA) |
エージェント | Planning(業務プランニング) | 2026年6月中に一般提供予定 |
Power BI | Agent Skills for Power BI(業務ロジックをスキルとして登録・共有) | プレビュー |
Microsoft 365連携 | Microsoft 365 CopilotでのFabricデータエージェント | 一般提供(GA) |
AI Functions | gpt-5-mini既定化、gpt-5.1設定対応のAI Functions | 一般提供(GA) |
データ統合 | Mirrored Database Change Feedコネクタ | プレビュー |
Microsoft Databases | Azure HorizonDB(PostgreSQL互換、AI-ready) | パブリックプレビュー |
この表からわかるように、Build 2026のFabric関連アップデートは「エージェント × アプリ × 分析」という3軸で動いています。エージェント側ではFabric IQの強化とMicrosoft 365 Copilot連携の一般提供、アプリ側ではRayfinによる開発体験の刷新、分析側ではFabric Data WarehouseのGPU高速化が中心になります。
さらに、データ統合の領域ではMirrored Database Change Feedコネクタが追加され、ミラーされたデータベースの行レベル変更をEventstreamsへ直接ストリーミングできるようになっています。
注意したい点は、Azure HorizonDBはFabricの新機能ではなく、Microsoft Databasesグループ側の発表である点です。Fabricの分析基盤と連携できる構成は想定されていますが、Fabric Data Warehouseの代替や、OneLakeの拡張ではありません。本記事の後半でこの位置関係について改めて整理します。
次のセクションからは、これらのアップデートのうち、特にBuild 2026の打ち出しとして大きい3つのトピック(Fabric IQ強化、Fabric Apps/Rayfin、Fabric Data Warehouse GPU高速化)を順番にご説明します。
Fabric IQのBuild 2026強化
Fabric IQは、OneLake上のデータをビジネス用語で理解できる形に整え、AIエージェントが業務データを正しく扱えるようにするためのワークロードです。
ここでは、Build 2026での主な強化点(差分)をご紹介します。
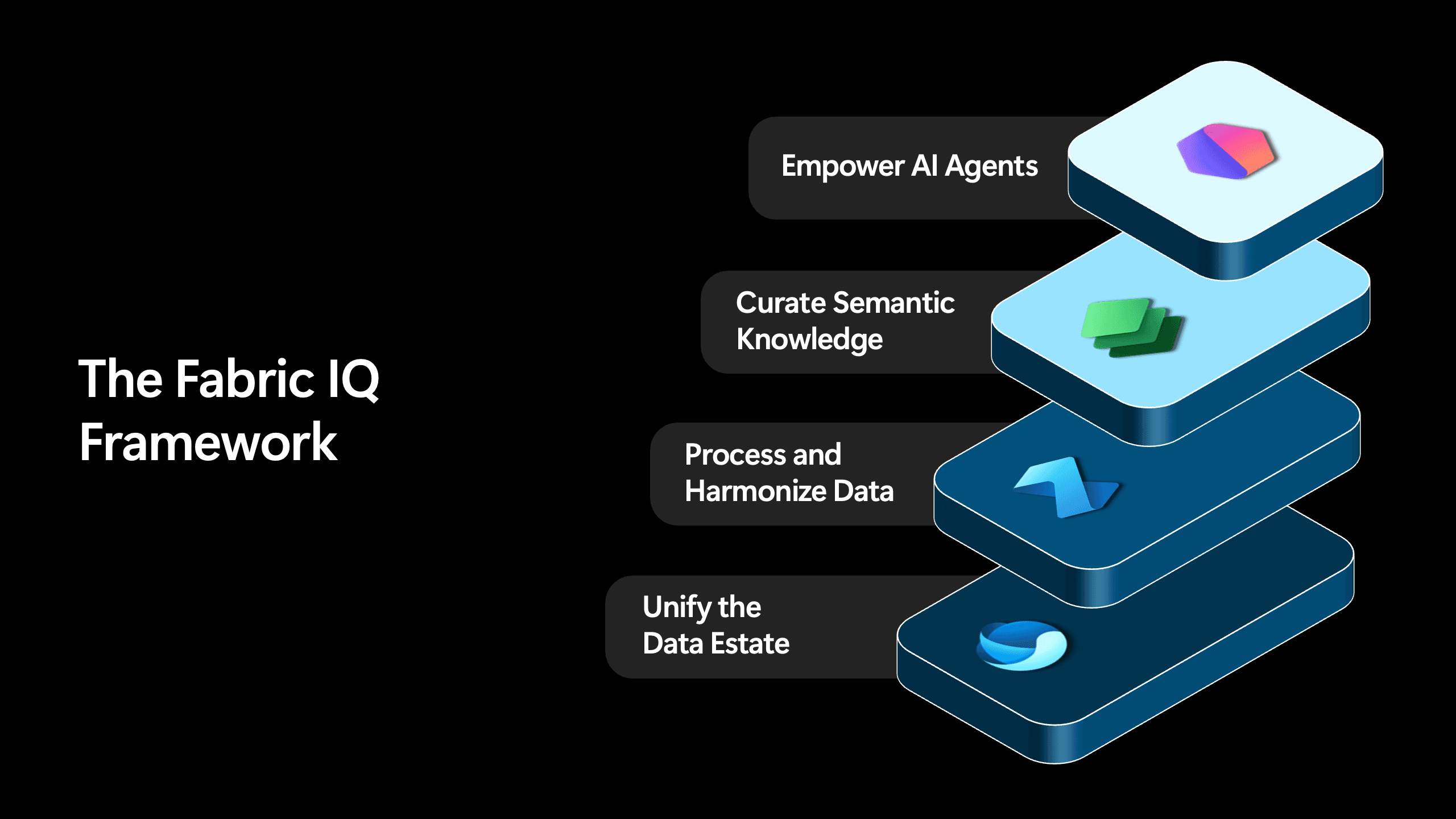
Fabric IQのフレームワーク 引用:Microsoft Learn
Build 2026で発表された主な機能強化
Fabric IQに関するBuild 2026の更新内容を以下の表に整理します。
機能 | 概要 | ステータス |
|---|---|---|
Creator Agent (SQL/Eventhouse対応) | Fabric Data Agentの構成をスキーマや対話を踏まえて自動生成 | プレビュー |
Improved NL2SQL Engine | 自然言語→SQL変換の精度・診断・例外処理を強化 | プレビュー |
Code Interpreter Tool | Fabric Data Agent内でPython実行が可能(統計・予測・可視化) | プレビュー |
Microsoft 365 CopilotでのFabric Data Agent | M365 Copilot上でガバナンス済みFabricデータと対話 | 一般提供(GA) |
Service Principal対応 (Fabric Data Agent) | アプリやFoundryエージェントがSPN認証でデータエージェントAPIを呼べる | プレビュー |
これらの強化のポイントは、Fabric Data Agentを「Fabric内部のチャットインターフェース」から「業務エージェントの一部」として組み込みやすくする方向に変えてきたことです。各機能の意味を順に見ていきます。
Creator Agent
Fabric Data Agentの構成作業そのものをAIエージェントが補助する仕組みです。これまでは、対象データソースの選定、エージェントへの指示文の作成、データソースごとのガイダンス記述、サンプルクエリの整備などを手作業で進める必要がありましたが、Creator Agentはスキーマやユーザーとのやりとりからこれらをまとめて提案します。SQLとEventhouseが対象のため、製造現場のセンサーデータ(Eventhouse)と基幹データ(SQL)を組み合わせたエージェント構築の初期工数が下がります。
Improved NL2SQL Engine
自然言語からSQLへの変換精度を高めるアップデートです。サンプルクエリを参照してパターンを学習し、意図が曖昧な場合は確認質問を投げかけ、構造化された診断情報を出力する設計になっています。これにより、「集計対象がどの期間なのか」「どのテーブルを指しているのか」といった、業務ユーザーが質問を投げる際に発生しがちな曖昧さを、エージェント側が補完できるようになります。
Code Interpreter Tool
Fabric Data Agentの中でPythonを直接実行できる機能です。データベースクエリの結果に対して、統計分析、予測モデル、コホート分析、Pythonによる可視化を行えるため、SQLだけでは表現しづらい分析パターンをエージェントワークフローの内側に取り込めるようになります。
Foundryエージェントからの利用
Build 2026の発表に伴い、Foundryエージェント側からもFabric IQをサーバーサイドツールとして登録し、自然言語タスクを委譲できる構成が公式に提供されました。詳細はConnect agents to Microsoft Fabric with Fabric IQ (preview)で公開されています。
この仕組みでは、Foundry側のエージェントが「四半期で1万ドル以上の注文を行った顧客は?」のような自然言語クエリをFabric IQに渡すと、Fabric IQがNL2Ontology変換とデータ取得を行い、結果を返します。
Fabric IQ側の処理は、サインインユーザーの文脈でFabricの権限とガバナンスポリシーを尊重して実行されます。
ただし、Fabric IQ tool経由でAzure AI Agent Serviceから利用する場合、追加コストやAzure compliance boundary外での処理可能性、Foundry projectとFabric workspaceのリージョン差、Fabric容量課金、組織のデータ所在地要件は事前に確認しておく必要があります。
これとは別のアップデートとして、Fabric Data Agent側でService Principal(SPN)認証が新たにプレビューでサポートされました。こちらは、業務アプリケーションやFoundryエージェントが、ユーザー委任トークンではなくアプリケーション識別情報としてFabric Data Agent APIを呼び出す構成を可能にするものです。
Fabric IQツール経由の利用とSPN対応のFabric Data Agent利用は別経路であり、用途に合わせて使い分けることになります。
Fabric Apps/Rayfin:エンタープライズ向けアプリバックエンド
Build 2026でMicrosoftが発表した新しい開発体験のひとつがRayfinです。Rayfinは、データモデル、API、認証、アクセス制御、ビジネスロジックといったアプリケーションのバックエンドを、コードとして定義してMicrosoft FabricにデプロイするためのオープンソースSDKおよびCLIです。
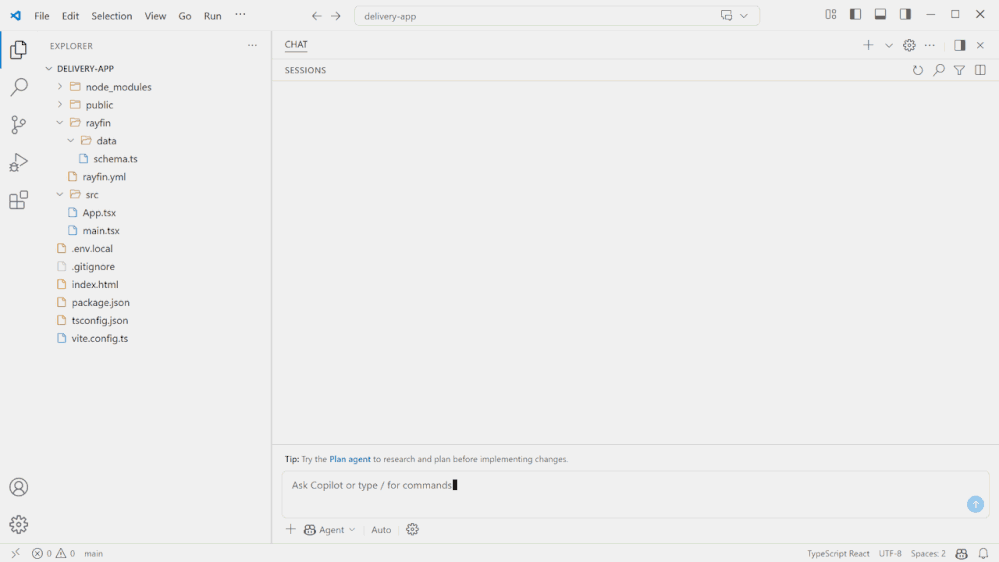
Rayfinを使ったVS Code上での開発画面(rayfin.ymlやschema.tsなどのプロジェクト構造) 引用:Microsoft Fabric Updates Blog
Rayfinの開発体験はVS Code上で完結する設計になっています。rayfin/配下にバックエンド構成(rayfin.yml、データモデルschema.ts)を、src/配下にフロントエンドのコードを置き、Copilotとの対話を通じて両方を同じプロジェクトとして扱えます。
公式発表記事Introducing Rayfin: A new AI-first way to build, deploy, and govern application backendsでは、Rayfinは「プロトタイプはすぐに作れるが、本番運用にスケールさせるのが難しい」という従来の課題に対応するものとして紹介されています。
AIによってフロントエンドの試作は短時間で行えるようになった一方で、データベース、認証、アクセス制御といったバックエンドの構築には依然として多くの工数がかかり、ガバナンス対応が後付けになる課題が指摘されてきました。
Rayfinはこの課題に対し、バックエンドの定義とFabricへのデプロイを一連の開発体験として統合する仕組みを提供します。
Rayfinの基本構造
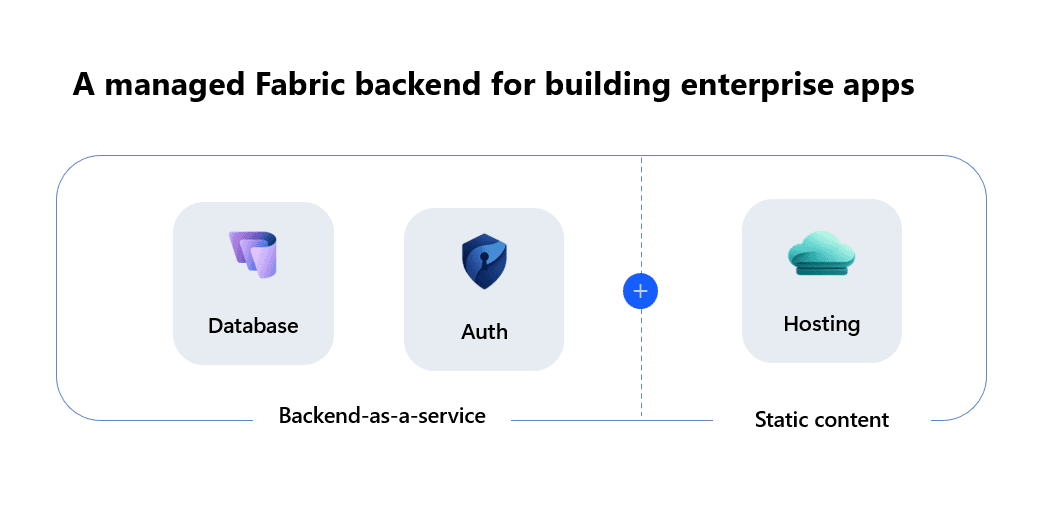
Fabric Appsのアーキテクチャ 引用:Microsoft Learn
Fabric Appsは「Backend-as-a-service(Database+Auth)」と「Static content(Hosting)」の組み合わせで、エンタープライズアプリのバックエンドをFabric上のマネージドサービスとして提供する仕組みです。Rayfinはこの仕組み向けに、データモデル・API・アクセス制御・ホスティング設定をコードで定義してデプロイできるSDKおよびCLIとして位置づけられています。
データモデル・アクセス制御・APIをコード上で一元定義できるため、データ構造を変更した際にアクセス制御や型情報が追従する設計になっている点と、Fabric Appsのデプロイ時にOneLakeへの直接アクセスが組み込まれる点がポイントです。
デプロイ手順や具体的なAPIリファレンスは、Microsoft LearnのDeploy a Fabric app to Fabricに整理されています。
コーディングエージェントとの親和性
Rayfinが特徴的なのは、開発者だけでなく、GitHub Copilotなどのコーディングエージェントが直接利用することを前提に設計されている点です。データモデルもアクセス制御も、すべてコードとして表現されているため、エージェントはアプリケーション全体を一貫したコードベースとして扱うことができます。
公式のWhat is Fabric Apps (Preview)?では、Fabric Appsが向くシナリオとして次の4点が挙げられています。
- 迅速なプロトタイピング(アイデアからライブURLまで短時間で到達)
- 社内向けの認証付きダッシュボード(バックエンドの定型コードなし)
- データ可視化アプリ(GraphQLでFabricデータを参照)
- AIエージェント向けの永続化バックエンド(エージェントの状態管理)
製造業の現場で例えるなら、品質検査の現場アプリや、設備稼働状況を確認する社内ダッシュボード、現場作業者向けの帳票閲覧アプリといった、Fabric上の業務データを参照しながら動く小規模なアプリケーションが、Rayfinの想定ユースケースに合致します。
Build 2026時点でのプレビュー状況
Build 2026の段階で公開されている内容は、SDKおよびCLIのプレビュー版です。あわせてFabric Apps自体もプレビュー段階で、What is Fabric Apps (Preview)?で公開されているとおり、利用にはテナント管理者による有効化、Fabric容量に割り当てられたワークスペース、容量ユニット(CU)の消費が前提となります。
Fabric Apps services consume capacity units という課金前提までは公式に明記されているため、既存Fabric容量を持つ企業であれば、Rayfinデプロイ時の課金経路自体は既知の枠組みの中で扱えます。
一方で、Fabric Apps固有の追加料金の有無、エンタープライズ運用での制限事項、ガバナンス設定の細部については、今後の追加情報を待つ必要があります。最新の仕様や運用上のチェックポイントは、Fabric Apps公式ドキュメントをご参照ください。
開発者向けには、Rayfin GitHubリポジトリおよびRayfin公式ドキュメントがBuild 2026に合わせて公開されています。製造業や半導体関連の企業で、業務アプリケーションのバックエンドをFabricに集約していく方針を検討する場合には、Rayfinをいち早く検証する価値があるアップデートと言えます。
Fabric Data WarehouseのGPU高速化
Build 2026のFabric関連発表のなかで、分析エンジンとして特に大きな進化となるのがFabric Data WarehouseのGPU高速化です。Microsoftはフルマネージド型のデータウェアハウスにGPUアクセラレーションを組み込む大きなアップデートとしてこの取り組みを位置付けています。
公式発表は次の2本のブログで公開されています。
- A new analytics frontier: GPU-accelerated Fabric Data Warehouse (Early Access Preview)
- Building the agentic analytics stack: Fabric Analytics at Build 2026
CoddSpeed:GPU高速化を支えるエンジン
GPU高速化の中核となっているのは、Microsoft内部で「CoddSpeed」と呼ばれるGPU実行エンジンです。CoddSpeedはNVIDIAのアクセラレーテッドコンピューティング基盤をFabric Data Warehouseのクエリエンジンに直接組み込むことで、SQLクエリの実行をGPU上で高速化する設計となっています。
このエンジンを支える研究論文「CoddSpeed: Hardware Accelerated Query Processing in Microsoft Fabric」は、データベース分野の国際学会であるACM SIGMOD 2026のBest Industry Paperを受賞しています。
研究成果が直接プロダクトに反映されている点は、エンタープライズデータウェアハウスとしては珍しい背景と言えます。ベンダーが提供する高速化機能の多くは、データ配置の最適化やキャッシュ強化が中心ですが、CoddSpeedはクエリ実行そのものをハードウェアアクセラレートする方向に踏み込んでいます。
性能と利用方法
公式ブログによれば、2026年5月時点での内部ベンチマーク(64ユーザー同時実行)において、競合する3つのクラウドデータウェアハウスと比較して最大7倍の性能が確認されています。さらに、Fabricデータエージェントと組み合わせた場合のエンドツーエンド応答時間は最大50%短縮されたとされています。
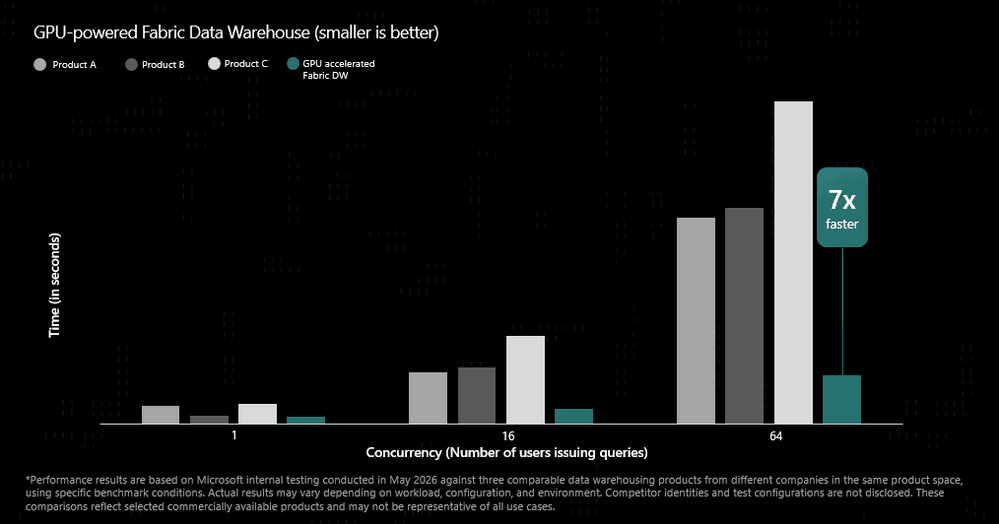
GPU高速化されたFabric Data Warehouseの性能比較 引用:Microsoft Fabric Updates Blog
利用にあたって特に重要なのは、次の3点です。
- クエリの書き換えは不要
- 新たなクラスタの管理は不要
- ワークスペース設定からの有効化のみで適用される
有効化すると、対象ワークスペース内のすべてのSQL Analytics EndpointおよびFabric Data Warehouseに反映されます。これは既存運用への影響を最小限に抑えながらGPU高速化を導入できる設計であり、運用チームにとっての導入ハードルを大きく下げます。
Fabric Data Warehouseの基本機能やSQL Analytics Endpointの位置づけはWhat is Fabric Data Warehouse?に整理されていますので、初めて触れる方はあわせてご確認ください。
既存ワークロードへの想定される影響
GPU高速化の恩恵が大きいのは、大規模なJOIN処理、集計、フィルタリングが組み合わさるレポーティングクエリです。製造業や半導体関連で多い、設備別・ロット別・期間別の生産実績集計、品質指標のクロス分析、長期トレンドのドリルダウン分析などは、まさにこのパターンに該当します。
また、Fabricデータエージェントと組み合わせる際の応答時間が改善される点は、自然言語からの問い合わせを業務ユーザーが頻繁に行うシナリオにおいて、体感品質の向上に直結します。これまで「集計に時間がかかるためエージェント経由の問い合わせを避けていた」というケースでも、Early Access Preview開始後にあらためて適用範囲を検討する余地が生まれてきます。
提供時期
Fabric Data WarehouseのGPU高速化は、Early Access Previewとして今後数週間以内に提供される予定となっています(出典:A new analytics frontier: GPU-accelerated Fabric Data Warehouse)。リージョン展開、対応クエリの範囲、料金体系の詳細は、Early Access Preview開始後に公開されていく見込みです。
製造業の現場で生産実績データ、品質データ、設備稼働データを大規模に分析しているケースでは、クエリ書き換えなしで性能改善を見込めるため、Early Access Previewが開始されたタイミングでの検証が有効と考えられます。
Azure HorizonDB:Microsoft Databases側のAI-ready PostgreSQL
Build 2026でMicrosoftが発表したAzure HorizonDBは、PostgreSQL互換のフルマネージド型データベースサービスです。
重要な点として、Azure HorizonDBはMicrosoft Fabricの新機能ではなく、Microsoft Databases側でのAI-ready PostgreSQLの発表として位置づけられています。
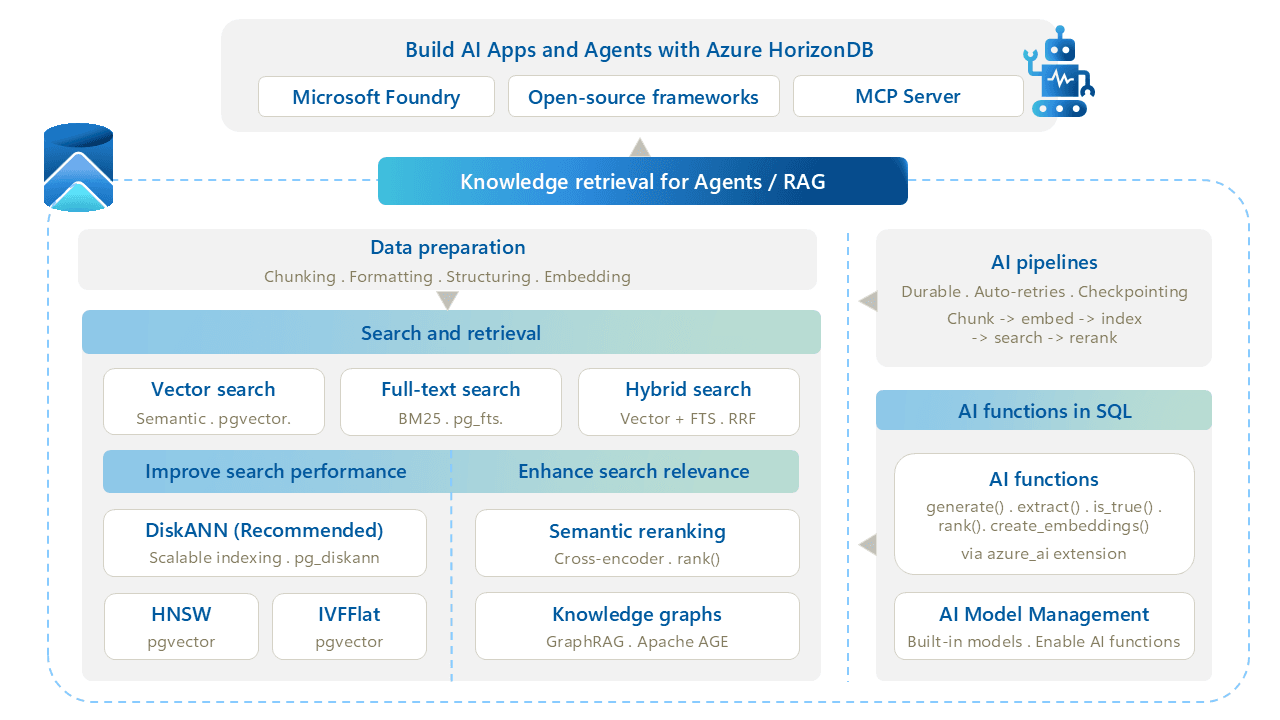
Azure HorizonDBのAI機能概要 引用:Microsoft Learn
位置づけとMicrosoft Fabricとの関係
Azure HorizonDBは、Foundry / オープンソースフレームワーク / MCPサーバーから利用できる「AIエージェント向けの知識検索基盤」として、ベクトル検索、フルテキスト検索、AIパイプライン、AI Functionsを単一のPostgreSQL互換データベース内に統合する構成です。AIアプリケーションのRAGや推奨機能の基盤として活用するイメージです。
Microsoft Fabricとの関係でいうと、Azure HorizonDBはFabric Data Warehouseの代替やOneLakeの拡張ではない点が重要です。Build 2026のタイミングでパブリックプレビューが開始され、AzureエコシステムにおいてはOneLakeへのミラーリングを通じて、トランザクションデータをFabric側の分析基盤と連携できる構成が想定されています。
製品仕様(データベースサイズ・レプリカ構成・対応リージョン・料金体系・運用時の制約)については、プレビュー段階の情報が中心となるため、本記事ではFabricとの関係性のみご紹介しました。
Azure HorizonDB単体の詳細は、Azure HorizonDB公式ドキュメントおよびMicrosoft Tech Community(adforpostgresql)をご参照ください。
Fabric AppsとMulti-Agent Workflow:データ基盤上で業務アプリとエージェントを動かす
Build 2026のFabric関連セッションを通じて繰り返し打ち出されていた方向性が、「アプリケーションがデータプラットフォームの上に集約されていく」という流れです。
この方向性は、Build公式セッションBRK225「Data, apps, and agents: the future of app dev with Rayfin」でも示されています。
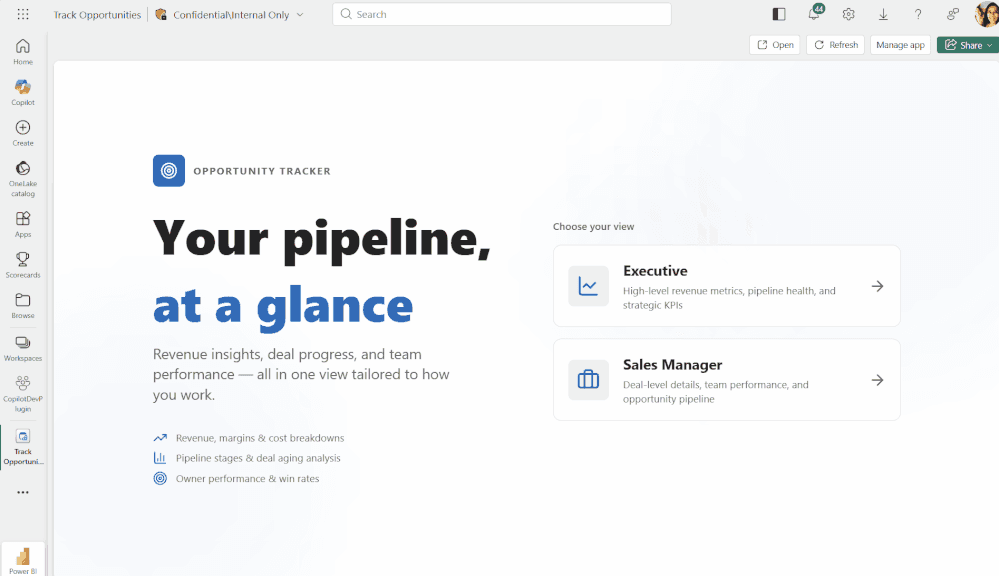
Fabric上で動作するOpportunity Tracker(営業パイプライン管理のFabric Data App例) 引用:Microsoft Fabric Updates Blog
Opportunity Trackerは、Fabric上に構築された営業パイプライン管理アプリの一例です。Executive向けの俯瞰ビューとSales Manager向けの詳細ビューを切り替えられる構成で、Fabricのデータエージェントから自然言語で問い合わせる利用シナリオが想定されています。このようなFabric Data Appは、エージェントが業務データや操作画面と接続するための業務側の接点になり得ます。
Fabric上でのフルスタックアプリ生成
Build 2026の以下のセッションでは、AIエージェントがFabric上のデータエステートを参照しながら、データベース・認証・バックエンドサービスを含めたフルスタックアプリケーションを生成する流れがデモされています。
- BRK225「Data, apps, and agents: the future of app dev with Rayfin」
- DEM313「Build agentic apps in minutes with Rayfin and Microsoft Fabric」
同様の流れは、ラボセッションLAB514「Ship AI apps fast with Rayfin, a new managed backend as a service」でも実装ベースで紹介されています。
これらのセッションが示しているのは、データ・アプリ・エージェントが分離されている従来の構成から、データプラットフォームの内側でアプリケーションとエージェントを構築する方向への移行です。Rayfinはこの動きを支える開発者向けの仕組みとして整理できます。
製造業や半導体関連の文脈で考えると、これまで個別に作っていた現場アプリ(作業指示、品質報告、設備点検など)が、Fabric上の分析基盤と一体化した形で構築できるようになる流れです。アプリ側でデータを別途持つのではなく、OneLake上の業務データを直接参照する構成が組みやすくなります。
Multi-Agent Workflow on Fabric
Build 2026のFabric関連セッションでは、Multi-Agent Workflowが具体的な実装パターンとして紹介されています。Microsoft IQ全体はFoundry IQ・Fabric IQ・Work IQ・Web IQの4層で構成されます。
一方、デモセッションDEM362「Building a Multi-Agent Workflow in Microsoft Fabric」では、このうちFabric IQ・Work IQ・Foundry IQの3つを中心に、計画、検索、要約、実行を担う複数のエージェントが協調する構成が示されました。
エージェントの役割 | 主な処理 | 主に活用するIQ |
|---|---|---|
プランナー | タスク分解と実行計画の作成 | Foundry IQ(知識)+ Work IQ(業務文脈) |
検索担当 | データ取得とオントロジーベースの推論 | Fabric IQ(業務データ) |
要約担当 | 取得結果の要約と整形 | Foundry IQ |
実行担当 | アクションの実施、データ更新 | Fabric IQ + Work IQ |
この表からわかるのは、Fabric IQは単独で完結するのではなく、他のIQと連携して業務エージェントの実行基盤として動作することを前提に拡張されている点です。
製造業で言えば、設備異常のアラート対応をエージェント化するケースなどがこのパターンに当てはまります。プランナーが対応手順を組み立て、検索担当が過去の類似事例と現在の設備データをFabric IQから取得し、要約担当が現場へ通知すべき内容を整形し、実行担当が作業指示の発行や記録更新を行う、といった流れが想定できます。
エンタープライズ統合:Fabric × Foundry × Purview
Build 2026のFabric関連発表で繰り返し触れられているもうひとつの軸が、Fabric・Foundry・Purviewのエンタープライズ統合です。AIエージェントを業務に組み込む場合、データ基盤・エージェント実行基盤・ガバナンスの3層が揃って初めて、本番運用に耐える構成になります。
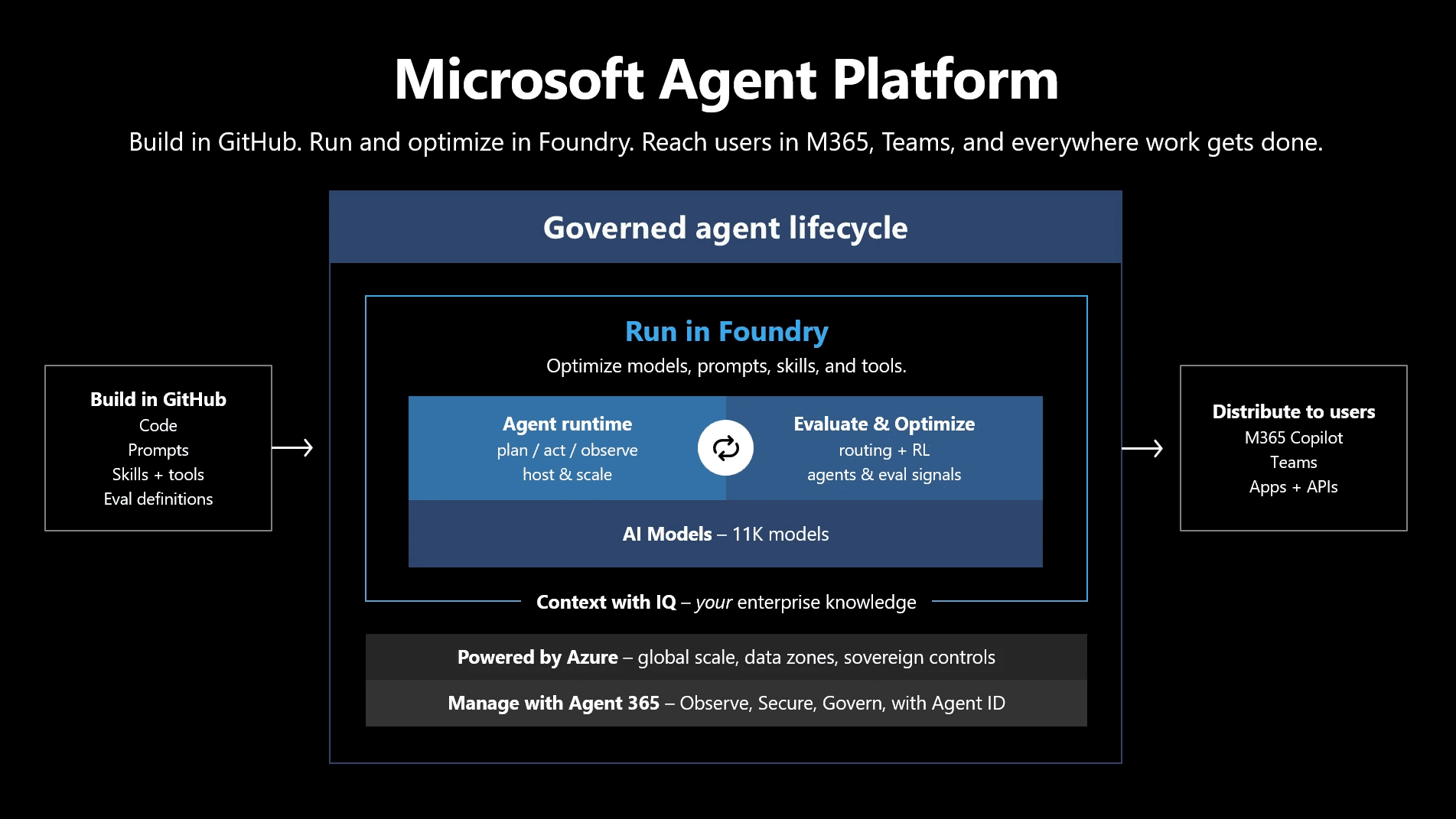
Microsoft Agent Platform:GitHubでビルド→Foundryで実行→M365/Teams/Copilotで配信、Agent 365で統制 引用:Microsoft Foundry Blog
Microsoft Agent Platformは「GitHubでビルド → Foundryで実行 → M365/Teams/Copilotで配信」の3工程に整理されています。
中央の「Run in Foundry」には、Agent runtime、Evaluate & Optimize、AI Models(11K models)が含まれ、外周をAgent 365による「Observe、Secure、Govern with Agent ID」が囲む設計です。
「Context with IQ」はFoundry IQ・Fabric IQ・Work IQ・Web IQが提供する企業ナレッジ層を指しており、Fabric IQはこの「Context with IQ」の一翼を担っています。
これがFabric単体ではなく、Foundry・Microsoft IQ・Agent 365・Purviewが組み合わさってエンタープライズエージェントが成立する全体像です。
LAB513に見る本番構成例
ラボセッションLAB513「Build an AI app with Azure SQL Hyperscale, Microsoft Fabric, & Foundry」では、RAGベースのFAQアシスタントを題材に、Azure SQL、Microsoft Fabric、Microsoft Purview、Microsoft Foundry Agentsを組み合わせる構成例が紹介されています。
具体的な要素としては、次の組み合わせが示されています。
- Azure SQL Hyperscale:トランザクションデータと社内ナレッジ
- Azure OpenAI Service:埋め込みベクトルと回答生成
- Microsoft Fabric(OneLake):分析データと業務指標
- Microsoft Foundry Agents:エージェントオーケストレーション
- Microsoft Purview:DLP、機密ラベル、データセキュリティポスチャ管理
このラボが示しているのは、Fabric単体ではなく、Foundry側のエージェント機能とPurview側のガバナンス機能を組み合わせて初めて、エンタープライズ要件を満たすAIアプリケーションが構築できるという考え方です。
3層構成の責務を整理すると、次のようになります。
層 | 主な責務 | 主な構成要素 |
|---|---|---|
データ基盤 | データの集約、セマンティック整理、分析処理 | OneLake、Fabric Data Warehouse、Fabric IQ |
エージェント実行 | エージェントのオーケストレーション、ツール呼び出し | Foundry Agent Service、Foundry IQ、Fabric IQ |
ガバナンス | DLP、機密ラベル、Insider Risk Management、データ保護 | Microsoft Purview、Entra ID |
この表からわかるとおり、Fabricは「データ基盤」層を担うコンポーネントとして、Foundry側のエージェント実行とPurview側のガバナンスと組み合わせて使うことを前提に位置づけられています。
Lightning TalkにみるエンタープライズAIエージェントの実装例
Lightning Talk LTG407「From Fragmented Data to Agentic Intelligence at Enterprise Scale—Powered by Fabric + Foundry」では、顧客フィードバックを起点に、Fabric上で構造化された知見へ変換し、リアルタイムにエージェント主導の判断を回す事例が紹介されています。
ここでは、Microsoft Entra IDによるセキュリティ、DLP、ガードレール、エンドツーエンドのテレメトリが、設計段階から組み込まれている点が強調されています。
これらの実装例から見えるのは、「Fabricを単独の分析基盤として使う」のではなく、Foundry・Purviewと統合してエージェント実行基盤として整えるという、本番運用を見据えた使い方が増えてきていることです。製造業や半導体関連の現場でも、エージェント導入の検討時には、データ基盤・エージェント・ガバナンスの3層を揃えて設計する視点が重要になります。
とくに、品質データ、設計図面、生産レシピなど機密度の高いデータを扱う場合は、Purview側の機密ラベルとDLPルールを設計フェーズから組み込むことで、後工程での手戻りを避けることができます。
Build後のFabric活用を既存コンポーネントと接続する
ここまでBuild 2026で発表された新方向についてご説明してきました。実際にFabricを活用していくうえでは、新規機能だけでなく既存コンポーネントとの組み合わせが重要になります。
具体的にはOneLake、Real-Time Intelligence、Power BI、Synapse Data Engineering、Data Factory、Fabricデータエージェント、Fabric IQが連携の中心です。
新規発表との関係を整理すると、次のようになります。
既存コンポーネント | Build 2026の新発表が加わる位置 |
|---|---|
OneLake | Rayfin / Fabric Apps からの直接アクセス、Azure HorizonDBミラーリング先 |
Power BI / セマンティックモデル | Fabric IQやFabric Data Agentが参照する業務指標・セマンティックモデルの接続点 |
Real-Time Intelligence | Mirrored Database Change Feedコネクタ、Eventstream SQL operator GA、Real-Time Dashboards Live Refresh GA |
Synapse Data Engineering | AI Functions(gpt-5-mini既定・gpt-5.1構成可)GA、Resource Profiles |
Data Factory | dbtの拡張、AI支援Airflow、private-network mirroring |
Fabric Data Warehouse | CoddSpeedによるGPU高速化(Early Access Preview) |
Fabricデータエージェント | Microsoft 365 Copilot連携GA、Creator Agent、Improved NL2SQL、Code Interpreter Tool、SPN認証対応 |
Fabric IQ | FoundryエージェントからのFabric IQツール呼び出し |
この表からわかるのは、Build 2026の新発表は、既存コンポーネントを置き換えるのではなく、それぞれに新しい機能を上乗せしていく形になっている点です。既存のFabric活用を、Build 2026の更新内容に合わせて段階的に拡張していくアプローチが有効です。
実務での検証順序を考えると、まず既存運用に直接効くアップデート(Fabric Data Warehouse GPU高速化、Fabricデータエージェントの強化)から評価し、続いて新しい使い方を広げるアップデート(Rayfinによるアプリ開発、Multi-Agent Workflow、HorizonDB連携)に進むのが効果的です。前者は既存ワークロードの性能や品質改善に直結し、後者は活用範囲の拡張に時間を要するためです。
特に、Fabric Data Warehouseを既に運用中の場合は、GPU高速化のEarly Access Previewを検証する価値があります。また、業務アプリケーションのバックエンドをFabricに集約する流れに対応したい場合は、Rayfinの試用が選択肢となります。
まとめ
本記事では、Microsoft Build 2026で発表されたMicrosoft Fabric関連のアップデートについて、Fabric IQ強化、Fabric Apps/Rayfin、Fabric Data Warehouse GPU高速化を中心に、関連するAzure HorizonDB、Multi-Agent Workflow、エンタープライズ統合の動きまで整理しました。
Build 2026の発表全体から見えるのは、Microsoft Fabricが「データ × アプリケーション × エージェント × ガバナンス」を統合したプラットフォームへと拡張されていく流れです。特に、CoddSpeedによるGPU高速化は、フルマネージド型データウェアハウスのクエリ実行そのものをハードウェアアクセラレートするアップデートであり、分析処理の性能をクエリ書き換えなしで引き上げられる点で実務的な影響が大きい更新と言えます。
3つの主要トピックを振り返ると、それぞれ次のように整理できます。
- Fabric IQ強化:エージェントによる業務データ活用の前提条件を整える更新
- Fabric Apps/Rayfin:アプリケーション開発を「Fabric上のコードベース」へと統合する仕組み
- GPU高速化:既存ワークロードに対する性能改善
これらに加えて、Azure HorizonDBの登場により、Fabric単独ではカバーしにくい高負荷トランザクション処理の選択肢も広がりました。まず既存のFabric活用状況を棚卸ししたうえで、Fabric IQ強化、Fabric Apps/Rayfin、GPU高速化の順に、自社のユースケースや既存基盤との適合性を検証していくことが推奨されます。
東京エレクトロンデバイスでは、Microsoft Fabricを中心としたデータ基盤の設計・構築をワンストップでサポートしています。Fabric IQを活用したAIエージェント実装、Fabric Apps/Rayfinによるアプリ開発、Fabric Data WarehouseのGPU高速化、Microsoft FoundryおよびPurviewと組み合わせたエンタープライズ統合まで、Build 2026の新発表を踏まえた構成を一括でご支援できます。
製造業・半導体・電子部品分野で業務データをBuild 2026の新発表に合わせて活用していきたい方は、ぜひお気軽にご相談ください。



