

AzureのCustom Speechとは?
Custom Speechとは、MicrosoftのクラウドサービスAzure AI Speech(Azure AI 音声)における音声認識モデルのカスタマイズ機能です。
標準の音声認識モデルに対し、ユーザー独自の音声データやテキストデータを追加トレーニングすることで、特定の分野や用途に特化した高精度な認識モデルを作成できます。
たとえば専門用語の多い業界向けに語彙を強化したり、固有名詞の発音を教えたりすることが可能です。また、リアルタイムの音声認識や音声翻訳だけでなく、テキスト翻訳にも対応しており、幅広い用途で利用できます。作成したカスタム音声モデルは、これらの機能を標準モデルと同様に活用できます。
 Custom Speech 引用:Custom Speech
Custom Speech 引用:Custom Speech
Azure AI Speech(Azure AI 音声)とは?
Azure AI Speech(Azure AI 音声)は、Microsoft Azureで提供されている音声関連AIサービス群のひとつです。 これらは「Azure AI Services」のカテゴリに含まれ、企業向けにはAzure AI Foundryの統合ポータルからも利用できる主要AI API群のひとつとして位置づけられています。
 Azure AI Services
Azure AI Services
標準モデルの限界とCustom Speechの役割
Azure AI Speechにはあらかじめ大規模なデータでトレーニングされた標準の音声認識モデルが用意されており、さまざまな場面で利用できます。しかし、業界特有の専門用語や組織独自の固有名詞が多い音声、あるいは騒音が多い現場の音声などでは、認識ミスが増える可能性があります。
このような標準モデルでは対応しきれないニーズに応えるために用意されているのが、Custom Speechによるモデルのカスタマイズ機能です。
Custom Speechの主な機能
Custom Speechでは、音声認識モデルの精度を向上させるために、主に以下のカスタマイズを行うことができます。
- 音響モデルのカスタマイズ (Acoustic Model Customization): 実際の音声データ(オーディオデータと書き起こし)を使用して、特定の音響環境や話者のアクセントに適応させます。
- 言語モデルのカスタマイズ (Language Model Customization): テキストデータ(プレーンテキストや構造化テキスト)を使用して、特定のドメインの語彙や言い回しに対する認識精度を高めます。
- 発音のカスタマイズ (Pronunciation Customization): 発音データ(単語と対応する発音の定義)を使用して、標準辞書にない単語や特殊な読み方をする単語の認識を改善します。
音響モデルのカスタマイズ
音響モデルは「音声波形から音素を認識する部分」を指し、話者の声質やアクセント、周囲のノイズ環境などの音響的要因を扱います。
Custom Speechでは、ユーザーが用意した音声データを用いて、音響モデルを追加トレーニングできます。これにより、特定の話者の特徴やアクセントに適応させたり、工場などの特定環境下でも認識しやすいモデルに調整できます。
十分な量の音声データをトレーニングすれば、機械の動作音が鳴り響く作業現場でもコマンドを聞き取れる音声操作システムや、特定の地方訛りに合わせた認識モデルなどを実現できます。
言語モデルのカスタマイズ
言語モデルは「音素列から単語や文章を解釈する部分」で、語彙や文脈に関するモデルです。
Custom Speechでは、ドメイン固有のテキストデータ(業界用語を含む文章データなど)を大量に入力して言語モデルを適応させることができます。製品名や専門用語、人名など標準モデルに十分含まれていない単語をトレーニングすることで、音声認識時にそれらの単語が正しく候補に挙がりやすくなります。
言語モデルのカスタマイズは音声データなしのテキストのみでも可能であり、手軽にモデルの語彙を拡張する方法として利用可能です。
発音のカスタマイズ
標準の音声認識モデルでは正しく認識されにくい単語、例えば、一般的な辞書に載っていない製品名、業界特有の専門用語、略語、造語、または特殊な読み方をする固有名詞などの発音をユーザーが明示的に指定することで、それらの単語の認識精度を向上させることができます。
これは、ユーザーが単語とその正しい発音(発音記号や読み仮名など)を定義した「発音データセット」を準備し、Custom Speechにアップロードすることで行います。システムは提供された発音情報を参照し、該当する単語が音声入力された際に、より正確に認識できるようになります。
例えば、「Azure」を「アジュール」と確実に読ませたい場合や、特定の製品コード「XG-F500」のようなアルファベットと数字の組み合わせを特定の発音で認識させたい場合に有効です。
上記のカスタマイズ機能に加え、音声認識のフォーマット(日付や数字の表記ルールなど)を整える表示テキストの正規化機能や不適切表現のフィルタリング機能も提供されています。これらを駆使することで、ユーザー固有の用語・表記揺れにも柔軟に対応できる音声認識モデルを構築できるのがCustom Speechの強みです。
Custom Speechの料金
ここでは、Custom Speechの料金体系についてご紹介します。Custom Speechには、使った分だけ支払う従量課金プランと、コミットメントレベルごとの定額プランが用意されています。
以下の表は、Microsoft公式が発表しているAzure AI Speechの料金表を一部抜粋・要約したものです。
従量課金プラン(主なもの)
項目 | 価格 (USD) | 備考 |
|---|---|---|
Custom Speech トレーニング | $10 / コンピューティング時間 | 2023年10月1日以降リリースのベースモデルカスタマイズ時などに適用される場合があります |
(その他、トランスクリプションやホスティング費用あり) | (詳細は公式料金ページ参照) |
定額プラン(Standard レベル)
コミットメント時間 | 月額料金 (USD) | 時間単価 (USD) |
|---|---|---|
2,000 時間まで | $1,920 | $0.96 |
10,000 時間まで | $7,800 | $0.78 |
50,000 時間まで | $30,000 | $0.60 |
定額プラン(Connected Container レベル)
コミットメント時間 | 月額料金 (USD) | 時間単価 (USD) |
|---|---|---|
2,000 時間まで | $1,824 | $0.909 |
10,000 時間まで | $7,410 | $0.738 |
50,000 時間まで | $28,500 | $0.565 |
定額プラン(Disconnected Container レベル)
コミットメント時間 | 年額料金 (USD) | 時間単価 (USD) |
|---|---|---|
120,000 時間 | $88,920 | $0.741 |
600,000 時間 | $342,000 | $0.57 |
※上記の内容は2025年6月確認時点の情報です。最新の料金はMicrosoft公式の料金表で必ず最新情報をご確認ください。
また、Custom Speechの利用には、上記に加えて、モデルのカスタマイズ(トレーニング)、リアルタイム/バッチトランスクリプション、エンドポイントホスティングなど、利用状況に応じた費用が発生します。特に、モデルのトレーニング費用は、選択するベースモデルやトレーニング時間によって変動します。
Custom Speechの利用手順
ここでは、Custom Speechを利用するための基本的な手順を解説します。
Custom SpeechはCLIでも利用可能ですが、今回はGUIベースでモデルのカスタマイズを行うことができるSpeech Studioを利用します。Speech StudioはMicrosoftが提供するサービスで、アップロードしたデータは暗号化されてサーバーに安全に保管されるため、オンライン上でも安心して利用できます。
- Azure AI Speech(Azure AI 音声)の準備
Azureポータルにアクセスし、Azure AI Speech(Azure AI 音声)のリソースを作成しましょう。サブスクリプションやリソースグループなど必要事項を入力します。
 Azure AI Speechリソースの作成
Azure AI Speechリソースの作成
- Custom Speechプロジェクトの作成
Speech Studioにアクセスします。サイドバーの「Custom Speech プロジェクト」をクリックし、「プロジェクトを作成する」を選択しましょう。
 Custom Speechプロジェクトの作成
Custom Speechプロジェクトの作成
- データのアップロード
「音声データセット」タブから、モデルのカスタマイズのために用意したデータをアップロードすることで、モデルのトレーニングを行うことができます。
 データのアップロード
データのアップロード
- カスタムモデルのトレーニング
「カスタムモデルのトレーニング」タブから、「新しいモデルのトレーニング」をクリックします。ベースとなる標準モデルと、アップロードしたデータを選択すると、カスタムモデルが自動的に作成されます。
 カスタムモデルのトレーニング
カスタムモデルのトレーニング
- カスタムモデルのデプロイ
「モデルのデプロイ」をクリックすることで、カスタマイズしたモデルをデプロイし、APIで呼び出せるようになります。
 モデルのデプロイ
モデルのデプロイ
上記のステップで実際にモデルのカスタマイズが可能です。次のセクションでは、用意したデータで活用デモを行います。
Custom Speechの活用デモ
このセクションでは、専門用語をまとめたテキストデータを利用して、実際にモデルのカスタマイズを行い、どの程度性能が向上したかテストします。 今回はテキストデータのみを利用しますが、主な機能のセクションでも前述したように、音声データによるカスタマイズも可能です。
モデルのトレーニングのために、以下のようなテキストデータを用意しました。一般的ではない生物学分野の用語を含んでいます。
 トレーニング用のテキストデータ
トレーニング用のテキストデータ
まずは、上記のテキストデータをSpeech Studio上にアップロードします。構造化されていないので、データの型は「テキスト」を選択しました。アップロードしたテキストデータから、カスタマイズモデルを新規作成します。
 トレーニング用データのアップロード
トレーニング用データのアップロード
カスタムモデルの性能が向上したかテストするため、テスト用の音声データと、以下のように音声データを正しく文字起こししたテキストデータを用意しました。
 テスト用のテキストデータ
テスト用のテキストデータ
「テストモデル」タブから、「新しいテストを作成する」をクリックしてテストを行います。
 カスタムモデルのテスト
カスタムモデルのテスト
テストの結果を確認すると、以下のように、標準モデルと比較して単語の誤り率が**9.21%から2.41%**に減少し、性能が向上したことが分かります。
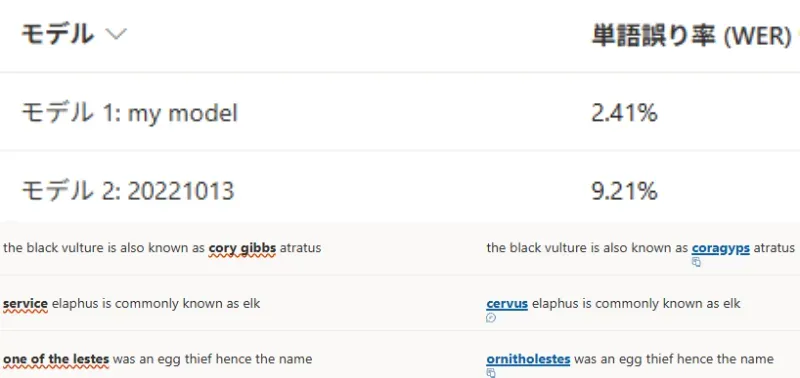
テスト結果
このように、用意したテキストデータからモデルのカスタマイズを行い、音声認識の性能を簡単に向上させることができました。
Custom Speechを利用する上でのポイント
Custom Speechで満足のいくモデルを作るには、いくつかのポイントを押さえる必要があります。ここでは精度を高めるためのコツやベストプラクティスをご紹介します。
十分なトレーニングデータを用意する
モデルの性能はトレーニングデータの質と量に大きく左右されます。音声はクリアな品質のものを使い、雑音の有無や話者の特徴など目的に合わせてバランスよく含めましょう。たとえば複数人の音声を認識したいなら、さまざまな年代の声を含め、アクセントや話し方の癖もできるだけ網羅します。
言語モデル用のテキストも、できるだけターゲット分野の語彙や言い回しを豊富に含むものを集めましょう。
テキストデータの品質を確保する
トレーニング用の文字起こしデータは正確に用意しましょう。文字起こしに誤りやズレがあると、モデルが誤ったトレーニングをしてしまい精度悪化の原因になります。
テキストデータをそのまま言語モデルトレーニングに使う場合、大量のデータから不要な記号やノイズを除去し、改行や文区切りなどフォーマット要件にしたがって整形しておきます。 モデルに覚えさせたい専門用語や新語があればスペルミスのないよう注意しましょう。
逐次的にモデル改善を繰り返す
一度で完璧なモデルを作ろうとせず、トレーニング→評価→データ追加→再トレーニングを何度か繰り返すことでモデルの精度を高めることができます。最初に作ったモデルの評価結果を分析し、その原因となるデータを追加収集するのが効果的です。
たとえば、ある話者の声だけ精度が低ければその話者の音声データを追加するといった具合です。
上記のように、適切なデータ準備と評価、改善を重ねることで、高精度な音声認識モデルを実現できます。
Custom Speechの活用シーン
ここでは、Custom Speechの利用が想定される活用シナリオをいくつかご紹介します。
騒音のある現場での音声操作
製造業の工場や建設現場など、バックグラウンドノイズが多い環境でのハンズフリー音声操作は、安全性の向上や効率化に有用です。
しかし、雑音下では標準モデルが誤認識しがちです。Custom Speechでその環境音を含む音声をトレーニングさせたモデルを使えば、騒音に埋もれがちなコマンド音声もしっかり聞き分けられるようになります。
会議の議事録自動作成
ビジネス会議や講演の内容を書き起こすニーズは高まっています。標準モデルでも多人数会議のリアルタイム字幕や録音からの文字起こしは可能ですが、社内用語や製品名が頻出する会議では、Custom Speechによるカスタムモデルが役立ちます。
社内用語の独特な語彙や、製品カタログに記載された固有名詞が頻繁に使用される場合、標準モデルではそれらを正確に認識できないことがあります。このような場合はCustom Speechを活用して、認識したい用語を含むテキストデータでモデルをトレーニングすることで、認識精度を向上させることが可能です。
先ほどの活用デモのように、トレーニング用のテキストデータをSpeech Studioにアップロードし、カスタムモデルを作成することで、会議中に使用される専門用語や固有名詞を正確に認識できるようになります。さらに音声データを追加でトレーニングに使用すれば、特定の話者の声質やアクセントにも対応したモデルを構築できます。
たとえば、製品開発会議で「XXXX」という製品名や「YYYY」という技術用語が頻出する場合、これらを含むトレーニングデータを事前に用意してモデルをカスタマイズすることで、会議の内容を正確に文字起こしできます。結果として議事録の品質が向上し、会議後の情報共有や意思決定がスムーズになります。
Custom Speechを活用した議事録の作成は、専門性の高い業界や独自の用語が多い企業にとって、有用なソリューションとなるでしょう。
Custom Speech利用時の注意点
高度なカスタマイズが可能なCustom Speechですが、運用にあたっていくつか注意すべきポイントも存在します。最後に、誤認識のリスクやデータ品質について注意事項を整理します。
完璧な精度にはならない
カスタムモデルを調整しても、音声認識にはある程度の誤りがつきものです。とくに人名や数字列などは音が似ていれば取り違えが発生し、訓練データにない新語が出現すればカスタムモデルでも誤認識が発生します。
Custom Speechの導入により精度は向上しますが、それでも100%の正確さは保証できない点は留意が必要です。重要なシステムでは、人間によるフォロー体制を組んでおくと安心です。
トレーニングデータの質と偏りに注意
使い方のコツでも言及したように、トレーニングに使うデータが不適切だと、モデルが誤ったトレーニングをして逆効果になる場合もあります。
たとえば文字起こしに誤字が多いと誤認識の可能性が高まり、一人の話者の音声だけでトレーニングしたモデルは他の話者の音声認識に弱いモデルになってしまいます。データ収集や前処理の段階で品質確保とバランス調整を行いましょう。
トレーニングデータのセキュリティ
企業内のデータをトレーニングに使う際は、情報ガバナンスのルールにしたがって取り扱う必要があります。 Azure側ではアップロードされたカスタム用データはユーザー専有扱いで保護されますが、内部情報や個人情報が含まれる場合は暗号化や契約面の確認なども行いましょう。
モデルのメンテナンス
一度作ったカスタムモデルも、時間の経過とともに見直しが必要になる場合があります。たとえば社名変更や新製品リリースで重要語彙が変化した場合、それをモデルに反映させる追加トレーニングを検討しましょう。
Custom Speechでモデルは作って終わりではなく、運用しながらメンテナンスするものと捉え、定期的な評価の機会を設けることが重要でしょう。
まとめ
本記事では、Custom Speechの機能、料金体系、および実際の活用事例まで詳しく解説しました。Azure AI Speech(Azure AI 音声)が提供するCustom Speechは、音声認識技術をニーズに合わせてパーソナライズできる機能です。標準モデルでは難しかった専門用語が含まれる音声や、ノイズ環境下の音声も、Custom Speechで訓練したモデルなら高精度に認識できます。
実際の導入に際しては、目的を明確にし、適切なデータ収集と前処理を行うことで、高精度なモデルを実現できます。自社のニーズに合わせた音声認識環境の構築に、ぜひご活用ください。
東京エレクトロンデバイスは、Azure AI SpeechをはじめとするAzure AIソリューションの企業導入をサポートしています。



