

Azure AI Visionとは?
Azure AI Visionは、画像や動画から多様な情報を抽出し、価値を創出するMicrosoftのクラウドAIサービスです。以前はAzure Computer Visionとして知られていましたが、現在は画像分析、OCR(光学文字認識)、顔認識、さらには動画内の物体や動きを解析する機能などが統合され、より包括的なサービスへと進化しました。
このサービスの大きな特徴は、機械学習の専門知識がなくても、これらの高度なコンピュータービジョン機能をAPIを通じて容易にアプリケーションへ組み込める点です。Azure AIサービス群の一つとして提供されており、開発者は迅速にAIを活用した画像・動画解析ソリューションを構築できます。
 Azure AI Vision (引用:Microsoft)
Azure AI Vision (引用:Microsoft)
Azure AI Visionの主な機能
次に、Azure AI Visionが提供する主な機能カテゴリについて、それぞれの特徴と活用例をご説明します。
画像分析
画像分析機能は、10,000種類以上の物体や概念を画像から検出し分類、そしてそれらに基づいたタグ付けや説明文(キャプション)の自動生成を行います。
例えば、画像の内容を文章で説明するキャプション生成や、成人向け・攻撃的といった不適切なコンテンツのフィルタリングにも対応しています。
空間分析
空間分析機能は、主にライブビデオストリームを解析することで、店舗や施設といった物理的な空間内における人や車両の動き、滞在状況、特定ゾーンへの出入りをリアルタイムに検出します。
これにより、例えば店舗内の顧客動線の最適化、混雑状況の監視、安全管理といった実用的なユースケースに活用されます。
光学式文字認識 (OCR)
光学式文字認識(OCR)機能は、画像データに含まれる印刷された文字や手書きの文字を高精度に抽出し、編集可能なテキストデータとして返却します。
多様な言語や書式が混在している場合でもその精度を維持し、契約書や請求書、ポスターなどから文字情報を効率的に抽出したり、抽出したテキストを翻訳や検索の基盤として利用したりする際に役立ちます。
顔検出と分析
顔検出と分析サービス(Faceサービスとも呼ばれる)は、画像や動画から人間の顔を検出し、その位置情報と共に、年齢、性別、感情といった属性情報を推定します。
写真の整理、アクセス制御の補助、マーケティング分析などが主な活用例です。なお、特定の個人を識別・認証する機能は、Face APIの「識別」機能として別途提供されています。
※顔認識に関連する機能、特に個人を識別する機能の利用には、責任あるAI (Responsible AI) に基づき、Microsoftへの利用申請と承認が必要となる場合があります。
ビデオ分析
ビデオ分析機能は、動画コンテンツから有益なインサイトを抽出することを目的としています。 主な機能として、リアルタイムでの動線や滞在を検出する「空間分析(Spatial Analysis)」や、録画された映像をインデックス化し検索可能にする「ビデオ検索(Video Retrieval)」が含まれます。
また、動画の各フレームに対して画像分析、OCR、顔検出といった他のAzure AI Visionの機能を適用することで、より詳細な情報抽出も可能です。 「ビデオ検索」は、特にバッチ処理による詳細な解析や、自然言語を用いた検索、メタデータの生成に適しています。
Azure AI Visionと他サービスの比較
Azure AI Visionは視覚コンテンツの高度な分析に特化したサービスですが、Azureには用途やデータ形式に応じて使い分けるべき類似のAIサービスが複数存在します。 ここでは、それぞれの特徴とAzure AI Visionとの主な違いを整理します。
1. Azure AI Content Understanding
Azure AI Content Understandingは、テキスト、画像、音声、動画といった多様な非構造化データを統合的に処理し、実用的な構造化データへと変換する、生成AIベースの新しいサービスです。
- 対象データ: テキスト、画像、音声、動画など、多様な非構造化データ全般。
- 主な機能: マルチモーダルな非構造化データを取り込み、ユーザー定義のスキーマに基づいて構造化された実用的な情報へと変換します。特に生成AIを活用したソリューション開発の支援を目的としています。
- Azure AI Visionとの違い: Azure AI Visionが画像や動画の視覚的な特徴分析に特化するのに対し、Azure AI Content Understandingはより広範な種類のデータを統合的に解釈し、業務プロセスで活用しやすい形に整理・変換する点に強みがあります。
【関連記事】
Azure AI Content Understandingとは? 非構造化データを活用するマルチモーダルAIを徹底解説
2. Azure AI Video Indexer
Azure AI Video Indexerは、保存されているビデオやオーディオコンテンツから詳細なメタデータを抽出し、検索可能なインデックスを生成することで、ビデオアーカイブの活用を促進するサービスです。
- 対象データ: 保存されているビデオおよびオーディオコンテンツ。
- 主な機能: 音声の文字起こし、翻訳、話者識別、顔検出、感情分析、キーワード抽出、シーン検出といった詳細なメタデータを抽出し、検索可能なインデックスを生成します。ビデオアーカイブからのインサイト抽出に優れています。
- Azure AI Visionとの違い: Azure AI Visionはリアルタイム処理やフレーム単位の視覚分析(例:空間分析の新機能)も扱いますが、Azure AI Video Indexerは特に既存のビデオアーカイブを対象としたバッチ処理による深い分析と、コンテンツの検索性向上、詳細なメタデータ生成に重点を置いています。
3. Azure AI Document Intelligence
Azure AI Document Intelligenceは、請求書、領収書、契約書などの多様なドキュメントから、テキスト、テーブル、キー・バリューペアといった情報を高精度に抽出し、業務プロセスの自動化を支援するサービスです。
- 対象データ: 請求書、領収書、契約書、フォームなど、多様なドキュメント(定型・半定型・非定型)。
- 主な機能: ドキュメントからテキスト、テーブル、キー・バリューペア、署名、レイアウト情報などを高精度に抽出し、構造化されたデータに変換します。事前構築済みモデルやカスタムモデルによる帳票処理の自動化が可能です。
- Azure AI Visionとの違い: Azure AI VisionもOCR機能を持ちますが、Azure AI Document Intelligenceは特にドキュメントのレイアウト理解や、特定のフィールドからのデータ抽出、多様なドキュメント形式への対応に特化しており、業務帳票の自動処理においてより高い精度と機能を提供します。
4. Azure Custom Vision
Azure Custom Visionは、ユーザー独自の画像データセットを用いて、特定の物体認識や画像分類を行うカスタムAIモデルを容易に構築・デプロイできるサービスです。
- 対象データ: ユーザーが提供する、特定のドメインやユースケースに特化した画像データ。
- 主な機能: ユーザー独自の画像データセットを用いて、特定の物体を検出したり、画像を分類したりするためのカスタム画像認識モデルを容易に構築、トレーニング、デプロイできます。比較的少ないデータからでもモデル作成が可能です。
- Azure AI Visionとの違い: Azure AI Visionhq幅広い用途に対応できる汎用的な事前学習済みモデルをAPIとして提供しますが、Azure Custom Visionは特定の業務や製品に合わせた高精度なカスタムモデルを、ユーザー自身で作成・管理できるカスタマイズ性に大きな特徴があります。
5. Azure AI Immersive Reader
Azure AI Immersive Readerは、テキストコンテンツの読解支援とアクセシビリティ向上に特化したサービスで、読み上げや翻訳、表示調整などの機能を提供します。
- 対象データ: テキストドキュメント、Webページ、アプリケーション内の文字情報など。
- 主な機能: テキストの読み上げ、単語や行のハイライト、フォント調整、品詞の強調表示、多言語へのリアルタイム翻訳など、テキストコンテンツの読解とアクセシビリティを向上させる機能を提供します。
- Azure AI Visionとの違い: Azure AI Visionが画像や動画といった視覚情報の「内容」を分析するのに対し、Azure AI Immersive Readerはテキスト情報の「可読性」と「理解度」を高めるユーザー体験の強化を目的としており、分析対象と目的が明確に異なります。
Azure AI Visionの使い方
それでは、Azure AI Visionを実際に利用するための基本的な手順をご説明します。
Azure AI Visionには、「Vision Studio」という便利なツールが用意されています。Vision Studioを利用すると、プログラミングを行うことなく、Azure AI Visionが提供する様々な機能を手軽に試し、一部の機能ではカスタムモデルの構築も体験できます。
まずは、このVision Studioを通じて、Azure AI Visionの基本的な使い方をみていきましょう。
- Azureサブスクリプションへのサインイン まず、Vision Studioを利用するためにAzureアカウントでサインインします。Azureのサブスクリプションをお持ちでない場合は、アカウントを作成することから始めてください。
 Azureサブスクリプションへのサインイン
Azureサブスクリプションへのサインイン
- リソースの選択または作成 Azureにサインインしたら、Vision Studio内で使用するAzure AI Visionのリソースを選択します。既存のリソースがない場合は、画面の指示に従って新しいリソースを作成してください。
 リソースの選択または作成
リソースの選択または作成
- 機能の選択と実行 Vision Studioのホーム画面には、Azure AI Visionが提供する様々な機能(例:OCR(光学文字認識)、画像分析、顔検出、ビデオ分析など)がタイル形式で表示されています。 ここから試してみたい機能を選び、クリックして操作を進めます。
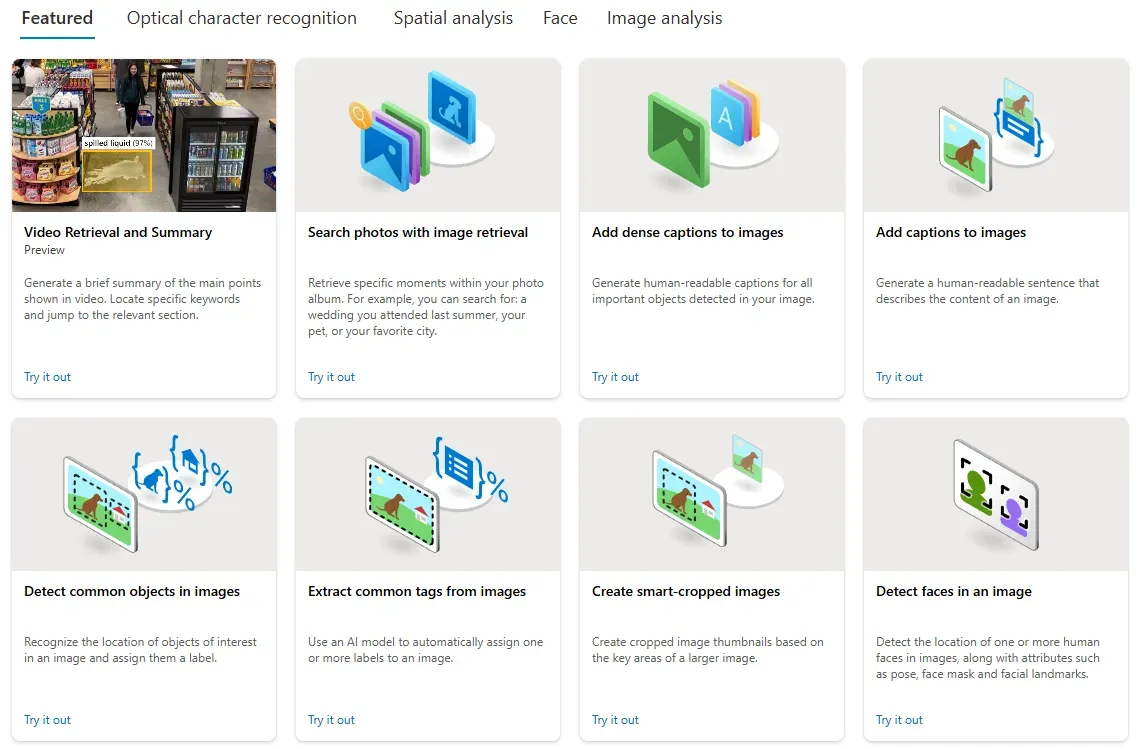 機能の選択と実行
機能の選択と実行
- 結果の確認 選択した機能の画面で、分析したい画像や動画をアップロード(またはサンプルデータを使用)すると、Azure AI Visionによる分析が実行され、その結果が画面上にテキストや視覚的な表現(例:バウンディングボックス)と共に表示されます。 例えば、下の図ではサンプル画像を使って文字認識(OCR)を試したところ、手書きの文字が正確に読み取れていることが確認できます。
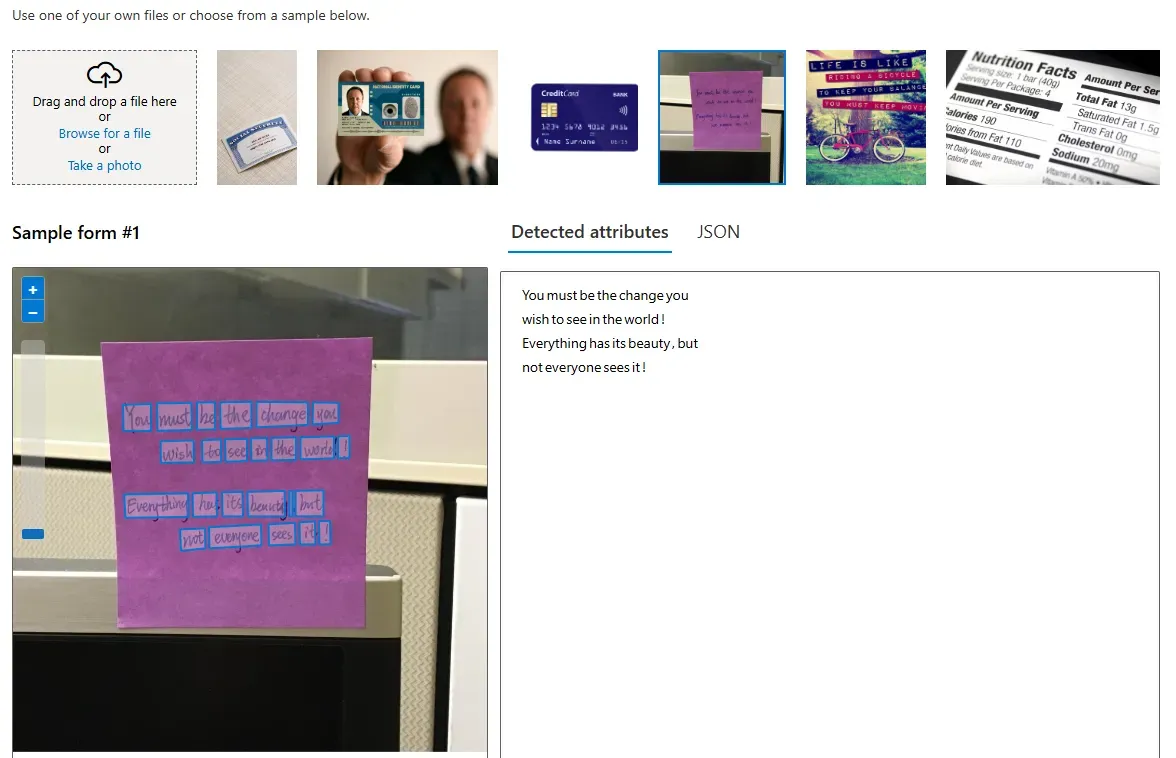 結果の確認
結果の確認 - 結果のエクスポート Vision Studioで得られた分析結果は、より詳細な情報を含むJSON形式でエクスポートすることも可能です。 このJSONデータには、例えば文字認識の場合、検出された各単語の座標情報なども含まれており、プログラムでの利用やさらなる分析に役立ちます。
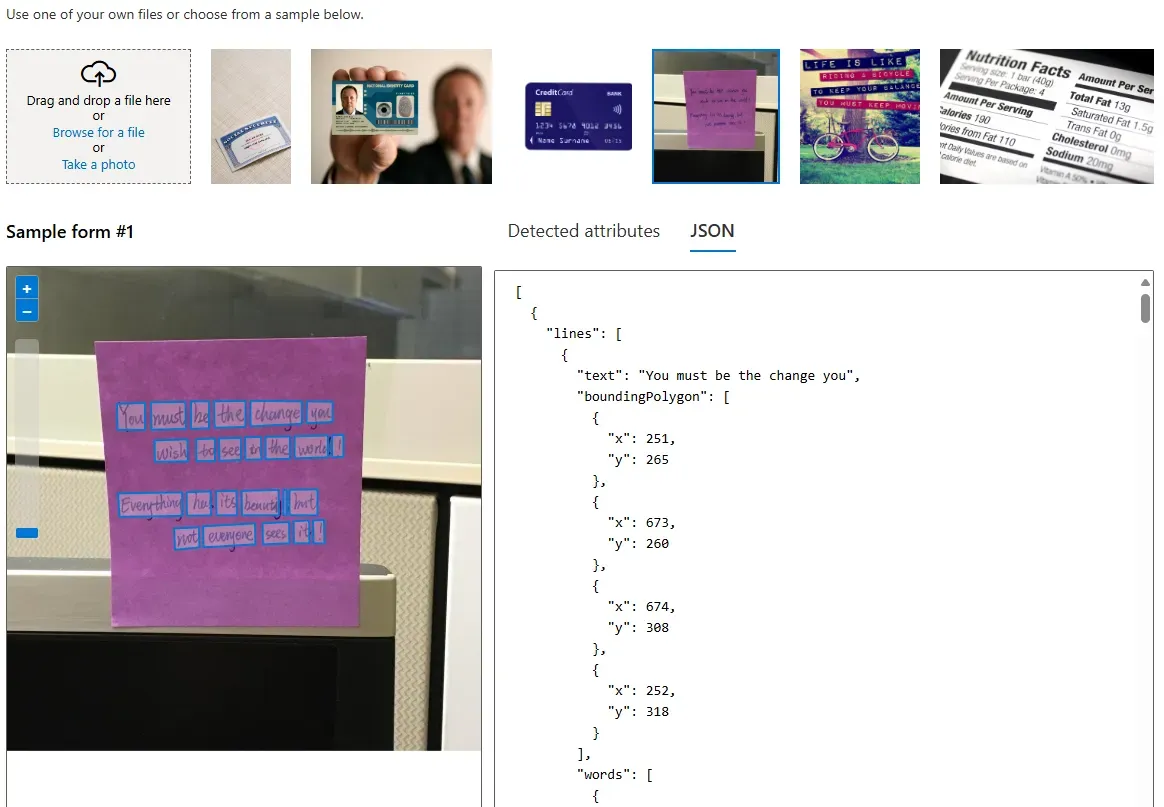 結果のエクスポート
結果のエクスポート
このように、Vision Studioを利用することで、Azure AI Visionの強力な機能を直感的かつ手軽に体験することができます。
なお、これらの機能を実際のアプリケーションに組み込んだり、既存のシステムと連携させたりする場合には、Azure AI VisionのAPIを利用します。 そのためには、APIキーとエンドポイントを取得し、プログラムからAPIを呼び出す形で実装を進めることになります。
Azure AI Visionの実践的な活用例:Pythonによる画像検索
本セクションでは、「大量の画像データの中から特定の画像を効率的に検索する」という具体的なユースケースを想定し、Azure AI Visionを活用する一例をご紹介します。
先ほどはVision Studioを使ってブラウザ上でAzure AI Visionの機能を確認してきましたが、ここではPythonプログラムを用い、複数の画像を一括で処理し、簡易的な検索機能を実装する流れを自動化します。
- まず、Azureポータルにログインします。 次に、作成済みのAzure AI Visionリソースを選択し、APIを利用するために必要な「キー」と「エンドポイントURL」を取得します。これらはプログラムからAzure AI Visionの機能にアクセスする際に使用します。
 APIキーとエンドポイント
APIキーとエンドポイント
- 以下は、本デモで使用するPythonコードです。 Azure AI Vision APIを呼び出して指定されたフォルダ内の各画像を解析し、その結果(特に画像の説明やタグ情報)から簡易的なインデックスを作成します。 そして、ユーザーが入力したキーワードに基づいて、関連する画像を検索できるようにするものです。
import requests
import os
subscription_key = # APIキー
endpoint = # APIエンドポイント
analyze_url = endpoint + "/vision/v3.2/analyze"
# リクエストヘッダーとパラメータの設定
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Content-Type': 'application/octet-stream'
}
params = {'visualFeatures': 'Categories,Description,Tags'}
def analyze_image(image_path):
"""指定された画像をAzure AI Visionで解析し、JSONを返す"""
with open(image_path, 'rb') as image_file:
image_data = image_file.read()
response = requests.post(analyze_url, headers=headers, params=params, data=image_data)
response.raise_for_status()
return response.json()
def index_images(folder_path):
"""フォルダ内の画像を解析し、画像ファイル名とインデックスを作成する"""
image_index = {}
for file in os.listdir(folder_path):
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
image_path = os.path.join(folder_path, file)
try:
result = analyze_image(image_path)
# descriptionからタグ取得
tags = result.get("description", {}).get("tags", [])
image_index[file] = tags
except Exception as e:
print(f"{file} の解析に失敗しました: {e}")
return image_index
def search_images(image_index, keyword):
"""画像のインデックスから、指定されたキーワードが含まれる画像ファイル名を返す"""
matching_images = []
for filename, tags in image_index.items():
# タグを小文字に
if any(keyword.lower() in tag.lower() for tag in tags):
matching_images.append(filename)
return matching_images
if __name__ == '__main__':
# 画像が保存されているフォルダのパスを指定
folder_path =
print("画像のインデックスを作成中...")
image_index = index_images(folder_path)
# ユーザーから検索ワードを入力
keyword = input("検索ワードを入力してください: ")
results = search_images(image_index, keyword)
# 検索結果の表示
print("検索結果:")
if results:
for image in results:
print(image)
else:
print("該当する画像が見つかりませんでした。")
※注意 上記コード内の YOUR_API_KEY と YOUR_ENDPOINT_URL は、手順1で取得したご自身のAPIキーとエンドポイントURLに置き換えてください。また、画像が保存されているフォルダのパスも適切に設定してください。
- Azure AI Visionの解析処理には、画像のアップロードとAIによる分析が含まれるため、多数の画像を処理する場合は相応の時間がかかります。 今回は処理時間を考慮し、10枚程度のフリー画像を用意して試してみます。
 用意したフリー画像
用意したフリー画像 - 上記のPythonプログラムを実行すると、まず指定されたフォルダ内の画像がAzure AI Visionによって解析され、それぞれの画像に関連付けられたタグ情報などが収集されてインデックスが作成されます。 その後、ユーザーに検索キーワードの入力を促し、入力されたキーワードに合致するタグを持つ画像ファイル名が検索結果として表示されます。

キーワード「dog」での検索結果
上記の画像では、検索キーワードを「dog」と入力すると、画像を探し検索結果として「a dog standing on a sidewalk」と表示されました。 学習した犬の画像と一致していることがわかります。
このように、Azure AI VisionのAPIを活用することで、画像の内容に基づいた検索システムなど、より実践的なアプリケーションを開発することが可能です。
Azure AI Vision の料金体系
ここでは、Azure AI Visionの料金体系についてご紹介します。
※本記事では東日本リージョンの2025年5月時点の情報を基に記載しています。最新の情報は、Azure AI Visionの公式の価格情報からご確認ください。
1. 無料利用枠 (Free F0)
Azure AI Visionを初めて利用する場合や小規模なテストには、無料利用枠が用意されています。
- 対象機能:
- 画像分析(グループ1、グループ2の全機能)
- マルチモーダルの埋め込み(テキスト埋め込み、画像埋め込み)
- 無料トランザクション数: 上記対象機能全体で、月間 5,000 トランザクションまで無料
- スループット制限: 1分あたり 20 トランザクション
- 空間分析 (Edge): 1ヶ月あたり 1 カメラまで無料
2. 従量課金 (Standard S1)
無料枠を超過した場合、またはStandardレベルの機能を利用する場合は、実際に行ったトランザクション数や利用時間に応じて料金が発生します。
a. 画像分析
画像の内容を理解するための機能群です。機能はグループ1とグループ2に分類され、それぞれ料金が異なります。
- グループ1: 対象機能: タグ付け、顔検出、サムネイル生成、色分析、画像の種類判定、注目領域検出、人物検出 (プレビュー)、スマートトリミング、OCR、成人コンテンツ判定、著名人・ランドマーク識別、オブジェクト検出、ブランド識別 料金 (1,000トランザクションあたり):
トランザクション数
料金(¥)
0~100万 トランザクション
142.856
100万~1,000万 トランザクション
92.856
1,000万~1億 トランザクション
85.714
1億トランザクション超
57.143
- グループ2: 対象機能: 画像の説明、Read API、キャプション生成、高密度キャプション 料金 (1,000トランザクションあたり):
トランザクション数
料金(¥)
0~100万 トランザクション
214.283
100万トランザクション超
85.714
- 背景の削除 (プレビュー): 現在無料
※ 画像分析の「モデルのカスタマイズ」および「製品の認識」は、東日本リージョンでは利用できません。
b. マルチモーダルの埋め込み
テキストや画像をベクトル表現に変換する機能です。
機能 | 料金(1,000トランザクションあたり) |
|---|---|
テキスト埋め込み | ¥2.000 |
画像埋め込み | ¥14.286 |
c. 空間分析 (Edge)
物理空間内の人物の動きなどをリアルタイムで分析する機能です。
機能 | 料金(時間あたり) |
|---|---|
Edge での空間分析 | ¥1.5429 |
d. ビデオの取得 (Video Retrieval)
録画されたビデオコンテンツから情報を検索可能にする機能です。
機能 | 料金 |
|---|---|
インジェスト (取り込み) | ¥7.143 / 1分間のビデオあたり |
クエリ (検索) | ¥35.714 / 1,000 クエリあたり |
3. コミットメントレベル (定額プラン)
特定の機能(現在は「Read API」が対象)について、利用量をコミットすることで、トランザクションあたりの単価が割引されるプランです。利用形態に応じてプランが用意されています。
a. Azureオンライン および 接続されたコンテナー (Read API)
月間の利用量をコミットするプランです。
利用形態 | 月額料金 / コミット量 | 超過料金 (1,000トランザクションあたり) |
|---|---|---|
Azure - S1 (オンライン) | ¥53,570.626 / 50万トランザクション | ¥107.142 |
¥171,426.001 / 200万トランザクション | ¥85.714 | |
¥599,991.001 / 800万トランザクション | ¥75.714 | |
接続されたコンテナー - S1 | ¥48,284.991 / 50万トランザクション | ¥97.142 |
¥154,283.401 / 200万トランザクション | ¥77.142 | |
¥539,991.901 / 800万トランザクション | ¥67.142 |
b. 切断されたコンテナー (Read API)
ネットワーク接続なしで利用できるコンテナー向けの年間コミットメントプランです。
年額 | 年間最大使用量 | 月間プロジェクト使用量目安 |
|---|---|---|
¥1,851,400.801 | 2,400万トランザクション | 200万トランザクション |
¥6,479,902.802 | 9,600万トランザクション | 800万トランザクション |
4. トランザクションのカウント方法に関する注意点
- 複数の機能の同時呼び出し (Analyze API): Analyze API を使用して一度に複数の機能(例: タグ付け、顔検出、成人コンテンツ判定)を指定した場合、指定した機能の数だけトランザクションがカウントされます(この例では3トランザクション)。
- Read API (複数ページドキュメント): Read API で複数ページのPDFドキュメントを処理する場合、各ページが1トランザクションとしてカウントされます(例: 200ページのドキュメントは200トランザクション)。
- 結果取得のGET呼び出し: 非同期処理(Read APIなど)の結果を取得するためのGET呼び出しもトランザクションとしてカウントされますが、これらには料金は発生しません。
5. コスト最適化のポイント
- 無料枠の活用: テストや小規模利用では、無料枠を最大限に活用しましょう。
- Analyze APIによる一括処理: 複数の分析が必要な場合、Analyze APIで一度にリクエストすることで、API呼び出しのオーバーヘッドを削減できる可能性があります(ただし、トランザクション数は機能ごとにカウントされます)。
- 適切な機能選択: 分析の目的に応じて、必要な機能のみを選択することで、不要なトランザクションを避けることができます。
- コミットメントレベルの検討: 「Read API」を大量に利用する場合は、コミットメントレベルの利用がコスト削減に繋がる可能性があります。
Azure AI Visionのユースケース
Azure AI Visionの主要な機能ごとに詳しく掘り下げ、活用例をご紹介します。
OCR(光学文字認識)
Azure AI VisionのOCRはディープラーニングベースのモデルのため精度が高く、曲がった文字列や複雑なレイアウトの文章からでも適切にテキストを取得します 。
【活用例】
- 文書デジタル化と検索性向上: 紙の書類や画像の中のテキストをOCRでデータ化することで、社内資料のデジタル化や全文検索が可能になります。 例えば契約書や報告書をスキャンしてOCRすれば、キーワードで素早く目的の文書を探せるようになります。
- 医療・製薬業界での帳票処理: 医師の手書きカルテや処方箋の読み取りにもOCRが活用できます。手書き文字対応のAzure AI Visionであれば、判読が難しい筆記体でもある程度テキスト化できるため、電子カルテ化やデータ分析の下準備を支援します。
このように、OCR機能はあらゆる業界で紙や画像からのデータ入力作業を自動化し、業務効率化に寄与します。
画像分析
Azure AI Visionの画像分析は非常に多機能で、1回のAPI呼び出しで10,000以上の概念やオブジェクトの分析が可能です 。モデルのカスタマイズにも対応しており、独自のカテゴリで画像を分類・検出することもできます 。
【活用例】
- 画像の情報整理: 大量の画像から情報を抽出する場合、自動タグ付け・キャプション生成を行えば、画像検索や整理が格段に容易になります。 例えば製品写真に「屋外」「笑顔」「車」などのタグを自動付与し、あとから「車 AND 屋外」で検索して該当写真を一括取得することも可能です。
- ソーシャルメディア監視: ユーザーが投稿する画像に不適切なコンテンツ(暴力的・成人向けなど)が含まれていないか自動検出し、違反の場合はアラートを上げる仕組みを構築できます。 コミュニティガイドライン遵守のための画像モデレーションはSNSの運営やオンライン掲示板で重宝するでしょう。
以上のように、画像分析機能は幅広い領域で、目視による判断を自動化することが可能です。
顔認識
Azure AI Visionの顔認識は高精度で、大規模な顔画像データベースに対しても高速に処理できます。
【活用例】
- セキュリティとアクセス管理: 入退館管理に顔認証を利用することができます。社員や許可訪問者の顔を事前登録し、入口のカメラ映像で照合することで、鍵やIDカードを使わずスムーズかつ安全に認証を行えます。近年は非接触・衛生面の理由からも顔認証ゲートの導入が進んでおり、オフィスやイベント会場での活用が増えています。
- 写真に写る人物の分類: 顔認識はスマートフォンのフォトアプリにも搭載されています。Azure AI Visionを組み込めば、ユーザーの写真を人物ごとにグルーピングしたり、「〇〇さんが写っている写真だけ表示」表示したりといった機能を比較的容易に実装できます。
以上のように、顔認識機能はセキュリティ強化とユーザーの利便性向上の双方に貢献する強力な技術です。
ビデオ分析
Azure AI Visionのビデオ分析は映像内の基本的な動きの検知にフォーカスしています 。
【活用例】
- 店舗や施設の安全管理: 空間分析を用いて、人の行動検知による安全管理が可能です。例えば、商業施設で立入禁止エリアに人が入った際に警告を出したり、閉店後に店内に人の動きを検知して不審者の侵入を知らせたりといった実装ができます。
- 映像アーカイブの検索効率化: 膨大な監視カメラ映像や動画から特定のシーンを探すのは困難ですが、ビデオインデックス機能で事前に解析・インデックス化しておけば、後から必要な映像をすぐに検索できます。 例えば、映像のアーカイブを再利用する場合に、「海岸の夕日」、「歓声が上がるシーン」等のように、素材を検索することが可能です。
ビデオ分析機能は、リアルタイム性が要求される現場から、大量の映像資産を扱う領域まで幅広く活用できます。
Azure AI Vision利用時の注意点
AIを活用する上で忘れてはならないのが、倫理的・法的な配慮です。特に顔認識のように個人に関わるデータを扱う機能では、その利用に慎重さが求められます。 ここでは、Azure AI Visionを使う際に留意すべきポイントを解説します。
プライバシーとデータの取り扱い
Azure AI Visionが扱うデータには、人の顔、車のナンバープレート、機密書類の内容など、個人情報や機密情報が含まれる可能性があります。 これらをクラウドに送信して分析するため、以下の点に注意しましょう。
- プライバシーポリシーの整備と告知 AIによってどのようなデータを収集・利用しているかを、ユーザーに対して明確に示しましょう。 特に顔認識や映像解析を導入する場合、「防犯目的でカメラ映像をAI解析しています」といった告知を分かりやすく行うことが大切です。
- データ保存とセキュリティ対策 分析に用いた画像や結果データの保存期間・場所にも配慮が必要です。個人が特定できるデータを不必要に長期間保存しない、保存する場合には暗号化やアクセス制限を施すなど、セキュリティ対策を徹底しましょう。 Azure自体は多くのコンプライアンス認証を持つ安全な基盤ですが、最終的なデータ管理責任は利用者側にあることを認識しておく必要があります。
公平性・バイアスへの対策
AIモデルには、学習データの偏りに起因するバイアスの問題が潜んでいることがあります。MicrosoftはAIの公平性を重視しモデル改善を続けていますが、利用者側でも以下の点を考慮しましょう。
- 導入前のテストと評価 利用シナリオに応じて事前にテストを行い、精度に偏りや問題が見られる場合は追加対策を検討します。 例えば、特定の条件下でうまく認識できない場合は、その条件では人間によるダブルチェックを行う運用を導入するなど、工夫が求められます。
- 継続的な評価と改善 AIシステム導入後も、定期的に結果を評価し、不適切な動作や差別的な影響が出ていないかをチェックしましょう。 必要に応じてモデルを再訓練したり設定を調整したりすることで、公平性の維持・向上に努めることが重要です。
Azure AI Visionの活用においては、技術的な有用性と社会的な受容性のバランスを取ることが不可欠です。Microsoftが提唱する責任あるAIの原則(公平性、信頼性と安全性、プライバシーとセキュリティ、包括性、透明性、説明責任)に則りつつ、価値あるソリューションを実現していきましょう。
まとめ
本記事ではAzure AI Visionの最新情報に基づき、その概要から機能説明、導入方法、注意事項まで包括的に解説しました。
Azure AI Visionは、画像や動画から多様な情報を抽出し、業務効率化や新たなサービス創出を支援する強力なクラウドAIサービスです。OCR(光学文字認識)、画像分析、顔認識、ビデオ分析といった主要なコンピュータービジョン機能を統合的に提供しており、プログラミング不要で扱えるVision Studioも用意されているため、手軽にAI技術を活用できます。
プライバシーや公平性に留意することで、Azure AI Visionは、未来の業務やサービスを支える目として、確かな価値を提供してくれるでしょう。
東京エレクトロンデバイスは、Azureの企業導入をサポートしています。 無料相談も受け付けておりますので、お気軽にご相談ください。



