
Azure AI Searchのエージェンティック検索(Agentic retrieval)とは?
Azure AI Searchのエージェンティック検索とは、複雑な質問に対応するために設計された、新しいマルチクエリ検索パイプラインです。
このAzure AI Searchの機能は、対話型AIアプリケーションにおける高度なRAG(検索拡張型生成)パターンを実現するための中核技術として位置づけられています。
エージェンティック検索の特徴は、LLM(大規模言語モデル)が、ユーザーからの複雑な質問を焦点の定まった複数のサブクエリに自動的に分解する点にあります。これにより、検索対象となるコンテンツをより網羅的に探索し、精度の高い情報抽出が可能になります。
Azure AI Searchとは?
Azure AI Search(旧称:Azure Cognitive Search)は、Microsoft Azureが提供するフルマネージドのクラウド検索サービスです。開発者はこのサービスを利用することで、多様な形式のコンテンツに対する高度な検索機能を自社アプリケーションに組み込むことができます。
サービスの基本的な仕組みは、Azure Blob StorageやAzure SQL Databaseといった様々なデータソースからデータを取り込み、インデックスと呼ばれる検索可能なデータストアに集約することです。これにより、アプリケーションは高速かつ効率的に情報を検索できるようになります。
特に重要な基盤技術として、以下の3つが挙げられます。
- ベクトル検索:キーワードの一致だけでなく、単語や文章の意味に基づいて情報を検索する機能です。
- ハイブリッド検索:従来のキーワード検索とベクトル検索を組み合わせ、両者の長所を活かすことで、検索の再現率と適合率を向上させる手法です。
- セマンティックランカー:検索結果に対して、Microsoft Bingから学習した深層学習モデルを用いて再度ランキング付けを行い、文脈的な関連性が高い結果を上位に表示する機能です。
次のセクションからは、エージェンティック検索について詳しく解説します。
Azure AI Searchのエージェンティック検索のワークフロー
このセクションでは、エージェンティック検索の動作の流れをご説明します。単一の検索リクエストでは、以下のステップでエージェンティック検索が実行されます。
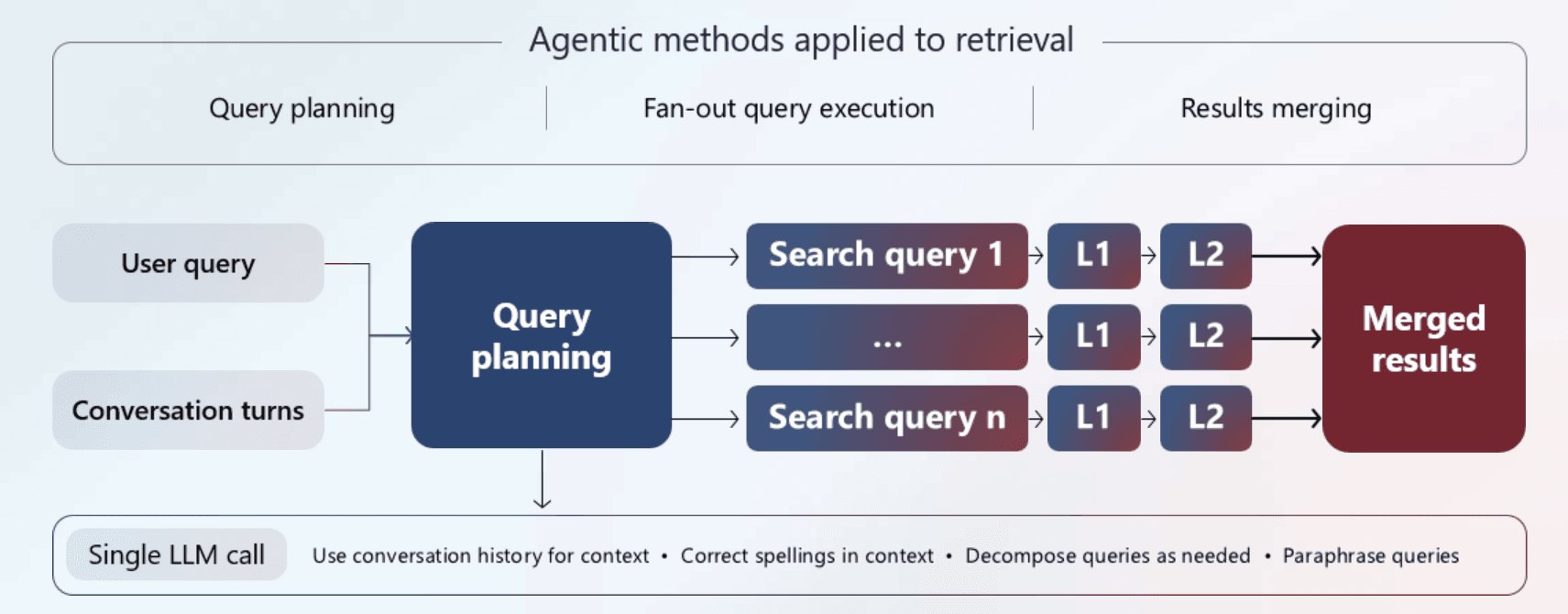
Azure AI Searchのエージェンティック検索のワークフロー 参考:Azure AI Search でのエージェンティック検索
1.クエリ計画
ユーザーからのプロンプトを受け取ると、まずLLMがその内容と、それまでのチャット履歴全体を分析します。これにより、表面的なキーワードだけでなく、会話の文脈からユーザーの意図や潜在的な情報ニーズを特定します。
2.分解と書き換え
次にLLMは、特定した意図に基づき、複雑な質問を複数の具体的なサブクエリに分解します。この過程で、より適切な類義語への言い換え、スペルミスの修正、専門用語の展開などが行われ、検索の網羅性を高めます。
3.並列実行
生成された全てのサブクエリは、検索インデックスに対して同時に実行されます。多くの場合ハイブリッド検索が用いられ、関連情報を見つけ出します。
4.統合と再ランク付け
各サブクエリから得られた検索結果は一つに統合されます。その後、セマンティックランカーがこの統合された結果全体を再評価し、元の複雑な質問の意図に対しても文脈的に関連性の高いドキュメントを上位に並べ替えます。
5.統一された応答の生成
最終的な出力は、後続のAIエージェントやアプリケーションが利用しやすいように、構造化された応答として返されます。この応答は主に以下の3つの要素で構成されます。
- グラウンディングデータ:最も関連性の高いコンテンツを一つにまとめた文字列で、最終的な回答を生成するLLMに直接渡せるように最適化されています。
- 参照データ:回答の根拠となった情報の出典や引用元がまとめられます。これにより、回答の透明性と信頼性が確保されます。
- アクティビティプラン:実行されたサブクエリの内容など、検索プロセス全体のログが出力されます。デバッグやコスト分析に役立ちます。
上記のように、エージェンティック検索は、Azure AI Searchの機能を自動的にオーケストレーションすることで、従来の手法では困難だった複雑な対話型の情報検索を実現します。
Azure AI Searchのエージェンティック検索の料金
エージェンティック検索は、LLMの呼び出しとセマンティックランカーの呼び出しの2段階で課金が行われます。
LLMの呼び出し
クエリ計画の推論ステップで実行されるLLMの呼び出しは、Azure OpenAI Serviceの利用料金として請求されます。料金は、使用するモデルと、クエリ計画時に消費された入力および出力トークン数に依存します。
Azure OpenAI Serviceの料金については、以下の記事をご覧ください。
Azure OpenAI Service の料金体系・コスト最適化のポイントを解説 (公開後URL)
セマンティックランカーの呼び出し
検索結果の再ランク付けを行うセマンティックランカーの利用料金は、リクエスト数に基づいています。
1か月あたり最初の1,000件のリクエストが無料で、追加リクエスト1,000件ごとに$1の追加料金がかかります。
※2025年11月時点の情報です。最新情報は、Azure AI Search公式料金表をご覧ください。
Azure AI Search エージェンティック検索の利用手順
それでは、実際にエージェンティック検索を利用する手順をご説明します。
0. 要件の確認
エージェンティック検索を利用するためには、以下の要件を満たしている必要があります。
- Azure AI Search
Basicプラン以上、セマンティックランカーが利用可能(Azure AI Searchから確認)
- 権限: 以下の権限が必要(Azure Portalから確認)
Search Service共同作成者 - 検索インデックスデータ閲覧者 - 検索インデックス データ共同作成者
1. Azure OpenAI Serviceリソースの作成
まずは、エージェンティック検索用のLLMをデプロイするため、Azure OpenAI Serviceからリソースを作成しましょう。

Azure OpenAI Serviceリソースの作成
2. モデルカタログにアクセス
リソースの作成が完了したらAzure AI Foundryに移動し、サイドバーの「モデルカタログ」を選択しましょう。
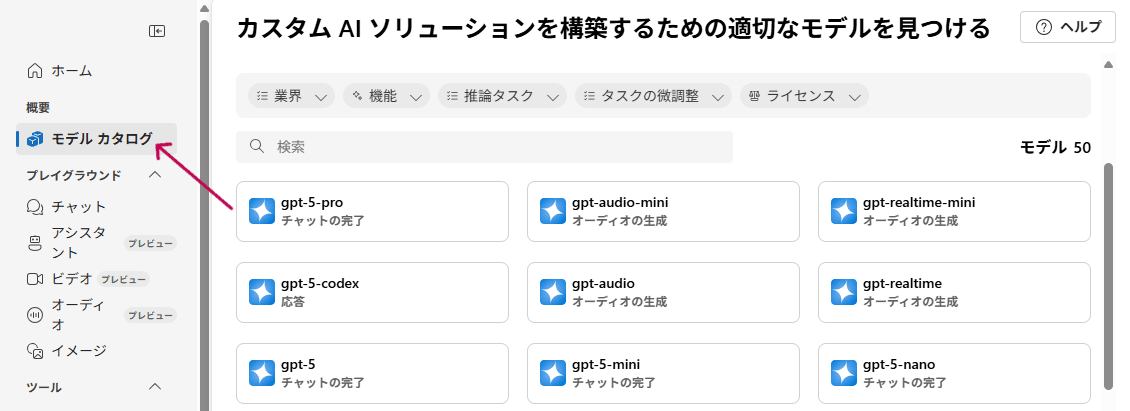
モデルカタログにアクセス
3. LLMのデプロイ
モデルカタログの検索ボックスからLLMを検索し、「このモデルを使用する」をクリックしてモデルをデプロイしましょう。
選択可能なLLMは以下の通りです。
- `gpt-4o`
- `gpt-4o-mini`
- `gpt-4.1`
- `gpt-4.1-nano`
- `gpt-4.1-mini`
- `gpt-5`
- `gpt-5-nano`
- `gpt-5-mini`

LLMのデプロイ
4. エンドポイントの確認
エージェントの作成時に必要になるため、デプロイしたモデルの管理画面から、エンドポイントを確認しましょう。
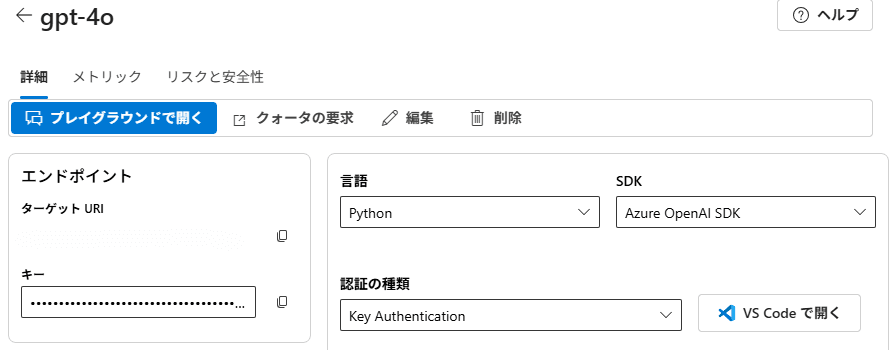
エンドポイントの確認
5. エージェントの作成
次に、実際にエージェンティック検索を実行するためのエージェントを作成します。以下は、Pythonでのサンプルコードです。
```Python
from azure.search.documents.indexes.models import KnowledgeAgent, KnowledgeAgentAzureOpenAIModel, KnowledgeSourceReference, AzureOpenAIVectorizerParameters, KnowledgeAgentOutputConfiguration, KnowledgeAgentOutputConfigurationModality
from azure.search.documents.indexes import SearchIndexClient
aoai_params = AzureOpenAIVectorizerParameters(
resource_url=#[エンドポイント],
deployment_name=#[デプロイ名],
model_name=#[[モデル名]],
)
output_cfg = KnowledgeAgentOutputConfiguration(
modality=KnowledgeAgentOutputConfigurationModality.ANSWER_SYNTHESIS,
include_activity=True,
)
agent = KnowledgeAgent(
name=knowledge_agent_name,
models=[KnowledgeAgentAzureOpenAIModel(azure_open_ai_parameters=aoai_params)],
knowledge_sources=[
KnowledgeSourceReference(
name=knowledge_source_name,
reranker_threshold=2.5,
)
],
output_configuration=output_cfg,
)
index_client = SearchIndexClient(endpoint=search_endpoint, credential=credential)
index_client.create_or_update_agent(agent, api_version=search_api_version)
print(f"Knowledge agent '{knowledge_agent_name}' created or updated successfully.")
```
C#やTypeScriptといった他言語のコードはエージェンティック検索の公式ドキュメントをご覧ください。
6. クエリの送信
実際にクエリを送信することで、検索エージェントを実行できます。以下のサンプルコードに「エージェントへの指示」と「クエリ」を入力することで実行可能です。
```Python
from azure.search.documents.agent import KnowledgeAgentRetrievalClient
from azure.search.documents.agent.models import KnowledgeAgentRetrievalRequest, KnowledgeAgentMessage, KnowledgeAgentMessageTextContent, SearchIndexKnowledgeSourceParams
instructions = """"""#エージェントへの指示
messages = [
{
"role": "system",
"content": instructions
}
]
agent_client = KnowledgeAgentRetrievalClient(endpoint=search_endpoint, agent_name=knowledge_agent_name, credential=credential)
query_1 = """"""#クエリ
messages.append({
"role": "user",
"content": query_1
})
req = KnowledgeAgentRetrievalRequest(
messages=[
KnowledgeAgentMessage(
role=m["role"],
content=[KnowledgeAgentMessageTextContent(text=m["content"])]
) for m in messages if m["role"] != "system"
],
knowledge_source_params=[
SearchIndexKnowledgeSourceParams(
knowledge_source_name=knowledge_source_name,
)
]
)
result = agent_client.retrieve(retrieval_request=req, api_version=search_api_version)
print(f"Retrieved content from '{knowledge_source_name}' successfully.")
```
上記の手順で、エージェンティック検索を利用することが可能です。さらに詳しい実装手順は、エージェンティック検索の公式ドキュメントをご確認ください。
Azure AI Search エージェンティック検索利用上のポイント
エージェンティック検索を有効に活用するには、いくつかのコツとベストプラクティスを意識する必要があります。このセクションでは、主な使い方のコツをご紹介します。
基盤となるインデックスを最適化する
エージェントの性能は、検索対象となるインデックスの品質に大きく依存します。
業界の専門用語に対応するためのシノニムマップ(類義語辞書)の活用、重要なフィールドの重み付けを行うスコアリングプロファイルの適用といったインデックス設計を最適化することが重要です。
パフォーマンスとレイテンシを管理する
エージェンティック検索は、LLMによるクエリ計画処理が介在するため、通常のクエリよりも応答に時間がかかります。
このレイテンシを緩和するため、リクエストに含める会話履歴を要約する、クエリ計画には高速なモデル(例:`gpt-4o-mini`)を使用する、Knowledge Agentにタイムアウト(`maxRuntimeInSeconds`)を設定するなどの対策が有効です。
透明性を確保する
LLMの推論プロセスはブラックボックスになりがちです。応答に含まれるactivity配列を活用して、生成されたサブクエリや実行ステップを可視化し、プロセスの透明性を確保しましょう。また、Azure MonitorやApplication Insightsと連携し、パフォーマンスの監視、品質の低下の検知、応答内容の継続的な評価を行う体制を整えることが推奨されます。
Azure AI Search エージェンティック検索の活用シーン
エージェンティック検索を活用することで、人間が複数のステップを踏んで調査するような、複雑な情報合成タスクを自動化することができます。以下に具体的な活用シーンを挙げます。
社内ナレッジベースを横断した検索
企業の社内文書は、出張規定、経費精算規定、国別特記事項など、目的別に異なるドキュメントとして管理されています。
例えば従業員から「3ヶ月を超える海外プロジェクトで顧客先を訪問する場合の出張規定と、日本での宿泊費および食費の具体的な上限額について教えてください」のような質問があった場合、通常は複数のドキュメントを横断的に検索し、情報を統合する必要があります。
エージェンティック検索は、この一連の調査プロセスを自動化して従業員からの問い合わせに回答することができます。
高度なカスタマーサポート
製品サポートにおいては、トラブルシューティング、保証情報、サービス拠点情報など、性質の異なる複数のナレッジベースを参照する必要があります。
例えば「モデルXの製品から異音がしており、保証が来月で切れます。保証期間内に修理は可能ですか?また、修理を申請する手続きと、郵便番号xxx-xxxxの近くにあるサービスセンターを教えてください」といった質問には、トラブルシューティングガイド、保証規定、サービスセンターのデータベースという複数の情報源を検索する必要があります。
エージェンティック検索を活用することで、横断的に情報を収集し、顧客にとって最適なサポートを一度に提供できます。
対話形式の財務分析
企業の財務分析では、複数企業の年次報告書から特定の指標を抽出し、期間を揃えて比較するといった多段階の分析が求められます。例えば「A社とB社の直近2年間の年次報告書から、第4四半期の収益成長率と利益率を比較し、サプライチェーンの課題について言及している箇所をすべて抜き出してください」のような依頼には、「指標抽出」「期間整合」「差分比較」「根拠抽出」といった複数のサブタスクが必要で、人間が手作業で行うと時間がかかります。
エージェンティック検索によって、LLMがこれらのサブクエリに自動分割し、各社の年次報告書から比較結果と要点サマリーを一貫した形式で生成できます。
これらのユースケースの共通点は、単一の自然言語の質問の裏に、情報抽出、照合、根拠確認という複数の調査ステップが内在することです。エージェンティック検索は、クエリ分解、並列検索、統合、再ランク付けによってこれらを自動化し、根拠付きで一貫した回答を返します。
Azure AI Search エージェンティック検索利用時の注意点
エージェンティック検索は有用な機能ですが、導入を検討する際には、現時点でプレビュー段階にあることを理解し、その特性と現状の制約を客観的に評価することが重要です。ここでは、利用時の注意点をご説明します。
クエリレイテンシの増加
エージェンティック検索では、クエリ計画のためにLLMの推論ステップが追加されるため、直接的な検索クエリと比較して応答時間が長くなる傾向があります。特に複雑なクエリの場合、生成されるサブクエリの数が増加することで、さらに処理時間が延びることになります。
このため、高速な応答が求められるリアルタイムアプリケーションには適さない場合があります。
なお、少数の広範なサブクエリを生成する「mini」プランナーの方が、多数の焦点を絞ったサブクエリを生成する「フルサイズ」プランナーよりも速く結果を返すことがあります。
プレビュー段階の制約と利用要件
現在、エージェンティック検索はパブリックプレビュー段階にあります。この段階ではSLA(サービスレベルアグリーメント)が提供されないため、本番環境での利用は推奨されていません。機能や仕様が変更される可能性もあるため、導入を検討する際は正式リリースまでのロードマップを確認することが重要です。
また、利用環境にはいくつかの前提条件があります。セマンティックランカーを提供するリージョンでのみ利用可能であり、クエリプランニングに使用できるLLMモデルも一部のシリーズに限定されています。
これらの制約により、既存の環境構成によっては追加の投資やアーキテクチャの変更が必要になる場合があります。特にグローバル展開を検討している場合は、展開予定のリージョンでこれらの要件が満たせるかを事前に確認しましょう。
実装とコストの複雑さ
実装には、Knowledge Agentオブジェクトの作成、Azure OpenAIモデルのデプロイ、インデックス設定など複数の構成要素の設定が必要で、プレビューAPIやSDKを使用したプログラマティックな実装が求められます。
また、コスト面では、Azure OpenAI(クエリプランニング・応答合成)とAzure AI Search(セマンティックランキング)の二重課金が発生します。初期プレビュー期間中はセマンティックランキングが無料ですが、プレビュー終了後は標準のトークン課金が適用されます。
不正確な応答やスコープ逸脱の可能性
設定が不十分な場合、エージェントが指定されたインデックスの内容に従わず、LLMの事前知識に基づいて回答を生成してしまう「ハルシネーション」のリスクがあります。応答が提供された情報源に基づいていることを保証するためには、適切なシステムプロンプトの設計やグラウンディングデータの品質管理など、慎重なプロンプトエンジニアリングが求められます。
導入にあたっては、解決したいビジネス課題の価値が運用オーバーヘッドを上回るかどうかを慎重に評価する必要があります。シンプルなFAQや単一ドキュメント検索には従来のRAGで十分な場合が多く、エージェンティック検索は真に複雑なマルチステップの情報統合が必要なユースケースに限定して使用することが推奨されます。
まとめ
本記事では、Azure AI Searchのエージェンティック検索の基本的な仕組み、料金体系、利用手順、活用シーン、注意点について詳しく解説しました。
エージェンティック検索は、複雑な質問に対応するための新しい検索パイプラインであり、LLMを活用してクエリを分解・統合することで、高度な情報検索を実現します。
エージェンティック検索は、ナレッジベースの横断検索や高度なカスタマーサポート、対話形式の財務分析など、複雑な情報合成タスクにおいて特に有用です。一方で、クエリレイテンシや実装の複雑さといった課題もあるため、導入前にビジネス価値と運用コストを慎重に検討しましょう。
東京エレクトロンデバイスは、Azure導入支援からID・権限設計、セキュリティ対策支援までをワンストップでサポートしています。



