
Azure AI Foundry Agent ServiceのDeep Researchツールとは?
Azure AI Foundry Agent ServiceのDeep Researchツールとは、公開Webからのデータを利用し多段階の詳細な調査を実行する、Azure AI Foundry Agent Serviceのプレビュー機能です。
このツールは、単に情報を検索して要約するだけでなく、与えられた調査タスクを計画し、複数の情報源を横断的に分析することで、深い洞察を導き出すことを目的として設計されています。従来の検索拡張型生成(RAG)が主に単一の検索結果に基づいて応答を生成するのに対し、Deep Researchツールでは人間の専門家が行うような多角的な調査プロセスを模倣します。
生成される出力は、結論に至るまでの推論過程や参照した情報源の引用を含む、構造化されたレポート形式を取ります。これにより、特に正確性、透明性、信頼性が求められるビジネスシーンでの活用が期待されます。
Azure AI Foundry Agent Serviceとは?
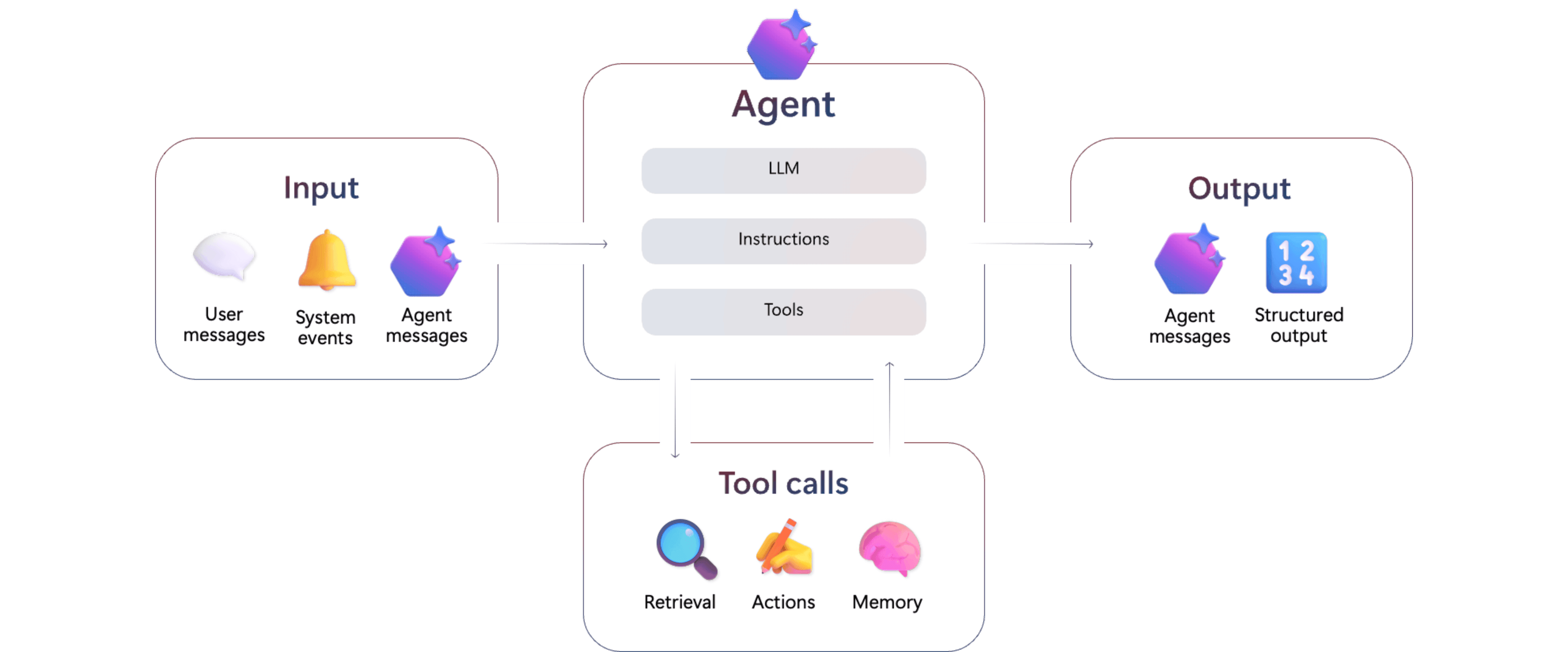
Azure AI Foundry Agent Service (参考:Microsoft)
Azure AI Foundry Agent Serviceは、特定のタスクを実行するAIエージェントを安全かつスケーラブルに構築・運用するためのフルマネージド基盤です。複雑な業務フローをエージェントに任せて自動化するための土台となります。
Agent Serviceは主に次の3要素で構成されます。
- モデル:エージェントの「頭脳」となるLLMです。GPTシリーズなどの汎用モデルから、Deep Researchツールが利用する `o3-deep-research` のような専門モデルまで、カタログから選んで利用できます。
- ツール:エージェントが情報取得や処理を行うための機能部品です。Deep Researchツールのほか、社内ナレッジ検索用の Azure AI Search や業務システム連携用の Azure Logic Apps などを組み合わせられます。
- オーケストレーション:対話状態の管理、ツール呼び出し、権限やセキュリティポリシーの適用など、エージェント実行全体を制御する仕組みです。これにより、Deep Researchのような多段ステップのタスクも安全に実行できます。
一つの万能AIを作るのではなく、役割の異なるエージェントやツールをブロックのように組み合わせて業務フロー全体を自動化する「コンポーザブルなエンタープライズAI」という思想に基づいて設計されています。
Azure AI Foundry Agent ServiceのDeep Researchツールのワークフロー
Deep Researchツールは、明確に定義された複数のステージからなる、体系的な処理パイプラインで構成されています。このパイプラインは、信頼性の高い調査結果を保証するために、各ステージで複数の要素を組み合わせています。以下に、Deep Researchツールがクエリを受け取ってから最終的なレポートを出力するまでの主要な流れを4つのステージに分けてご説明します。
1:意図の明確化とタスクのスコープ設定
調査プロセスは、まずユーザーから与えられたプロンプトを正確に理解することから始まります。このステージでは、LLMがユーザーの質問の意図を分析し、曖昧な点があれば追加の文脈を収集し、調査タスクのスコープを厳密に定義します。
この初期段階でのスコープ設定は、後続のコストと時間がかかる調査プロセスが無駄にならないようにするために行われます。
2:Bing検索によるWebグラウンディング
タスクのスコープが確定すると、エージェントは次にGrounding with Bing Searchツールを呼び出します。このツールの目的は、調査タスクに関連する、最新かつ信頼性の高いWeb上の情報源をBing検索によって収集することです。
このグラウンディングと呼ばれるプロセスは、AIが無関係な情報に基づいて誤った情報を生成するハルシネーションのリスクを低減させるために不可欠です。
3:詳細な分析と統合
信頼できる情報源が収集されると、調査の中核となる分析を行います。このステージでは、調査分析タスクに特化して設計された専用モデル`o3-deep-research`が使用されます。
このモデルは、ステージ2で収集された複数の情報源を横断的に分析、統合し、深い洞察を導き出す能力を持っています。
4:構造化され監査可能な出力
最終ステージでは、分析結果が構造化されたレポートとして出力されます。このレポートには、単なる回答だけでなく、その結論に至った根拠となる情報源への引用、モデルの推論過程などが含まれます。
このような情報は、特に金融や法務といった規制の厳しい業界や、企業の重要な意思決定に関わるようなユースケースにおいて、AIの出力に対する信頼性を担保するために重要な要件です。
Azure AI Foundry Agent ServiceのDeep Researchツールの料金体系
このセクションでは、Deep Researchツールの料金体系をご説明します。以下は、Deep Researchツールの料金を示した表です。
種類 | 料金 |
|---|---|
入力 | $10 / 100万トークン |
キャッシュされた入力 | $2.50 / 100万トークン |
出力 | $40 / 100万トークン |
上記のDeep Researchツール自体の料金に加え、Grounding with Bing Searchツールを呼び出すために以下の料金が加算されます。
料金 | トランザクション上限 |
|---|---|
$35 / 1,000トランザクション | 150トランザクション/秒 1日あたり100万件のトランザクション |
上記の内容は2025年11月時点の情報です。最新情報は、Azure AI Foundry Agent Service公式料金表をご確認ください。
Azure AI Foundry Agent ServiceのDeep Researchツールの利用手順
それでは、実際にDeep Researchツールを利用する手順をご説明します。
このセクションでは、ステップ7以降、Pythonを使用して実装を行います。C#やTypeScriptといった他言語のコードはDeep Researchツール公式ドキュメントをご覧ください。
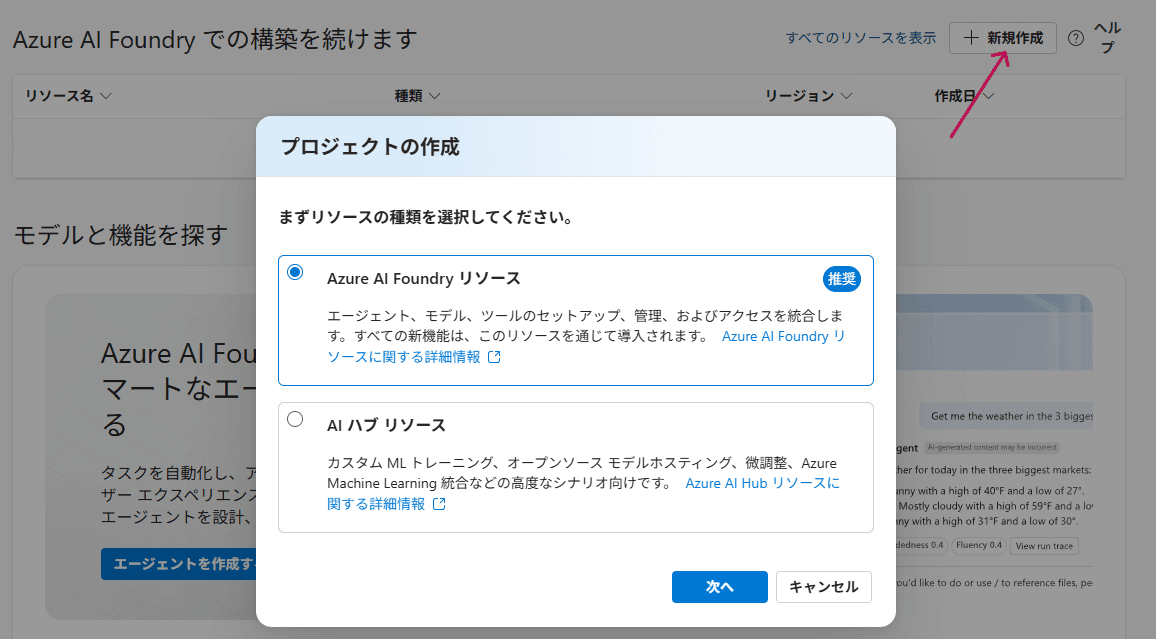
1. Azure AI Foundryにアクセス
まずはAzure AI Foundryにアクセスし、「新規作成」をクリックしてプロジェクトを作成します。
リソースグループやサブスクリプションなど、必要な情報を入力しましょう。
Azure AI Foundryにアクセス
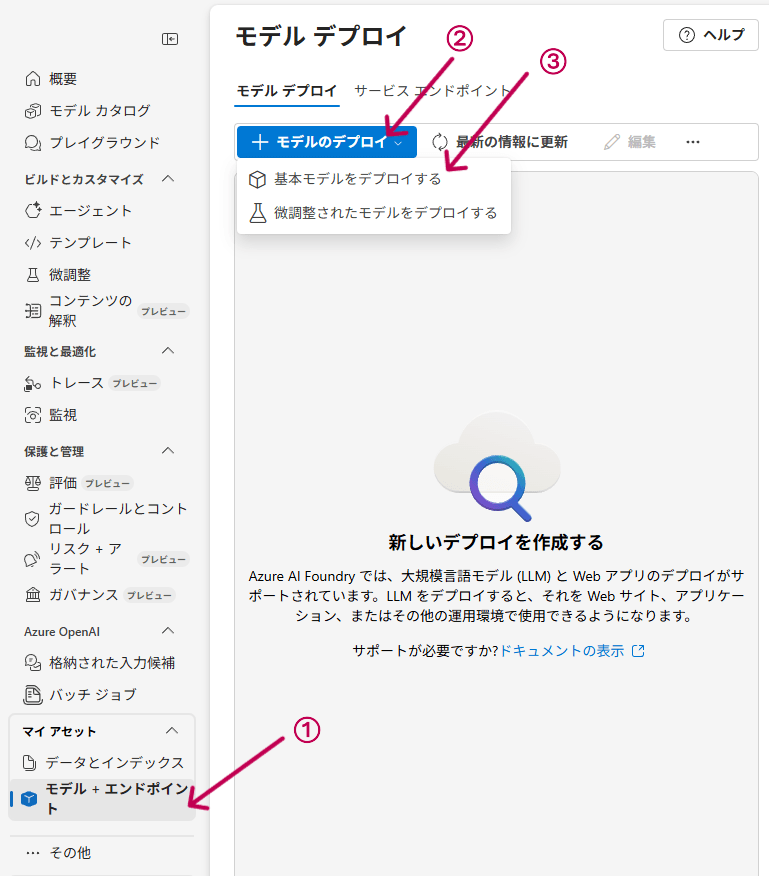
2. モデルのデプロイ
サイドバーの「モデル+エンドポイント」タブから「モデルのデプロイ」をクリックし、「基本モデルをデプロイする」を選択します。
モデルのデプロイ
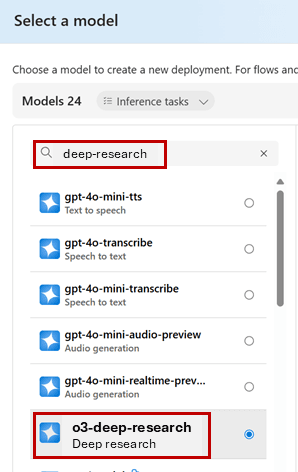
3. `o3-deep-research`のデプロイ
`o3-deep-research`と検索して「確認」をクリックし、デプロイを行いましょう。
※`o3-deep-research`の利用には事前申請が必要な場合があります。申請の承認まで時間がかかることもあるため、利用を検討している場合は早めに申請しましょう。
`o3-deep-research`のデプロイ (参考:Microsoft)
4. スコープ設定を行うモデルのデプロイ
プロンプトを受け取り、スコープの設定を行うためのLLMをデプロイします。デプロイ手順はステップ3と同様です。
※2025年11月現在、スコープの設定は`gpt-4o`のみでサポートされています。
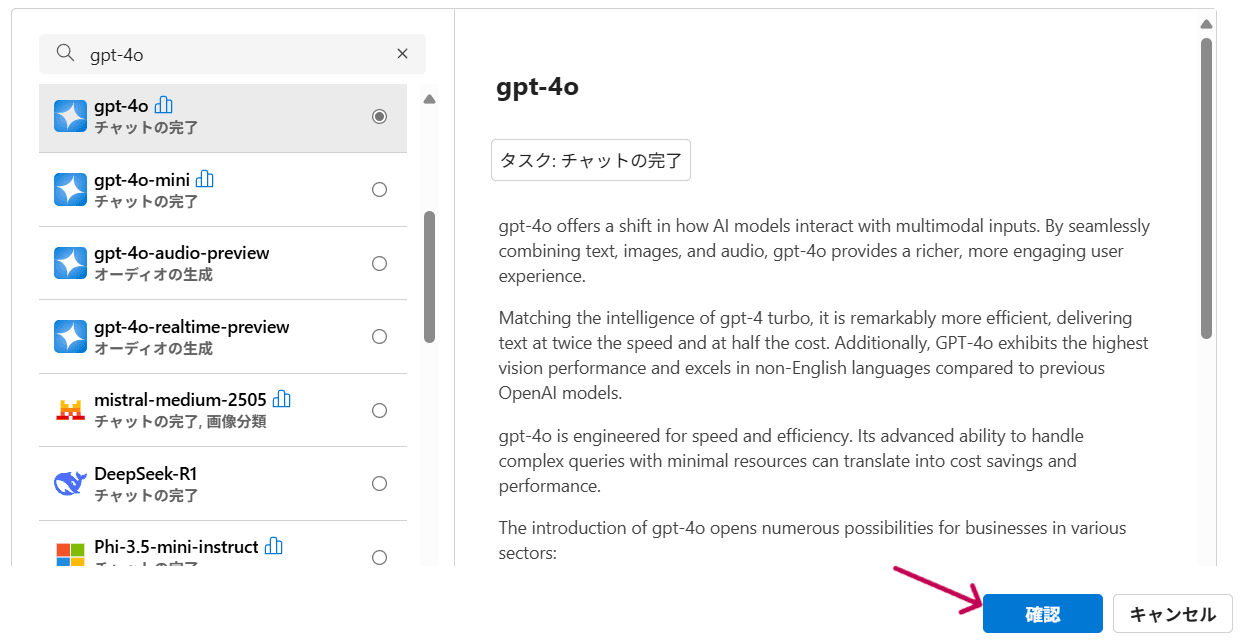
スコープ設定を行うモデルのデプロイ
5. 管理センターにアクセス
サイドバーの「管理センター」タブから「Connected resources」をクリックし、「新しい接続」を選択します。
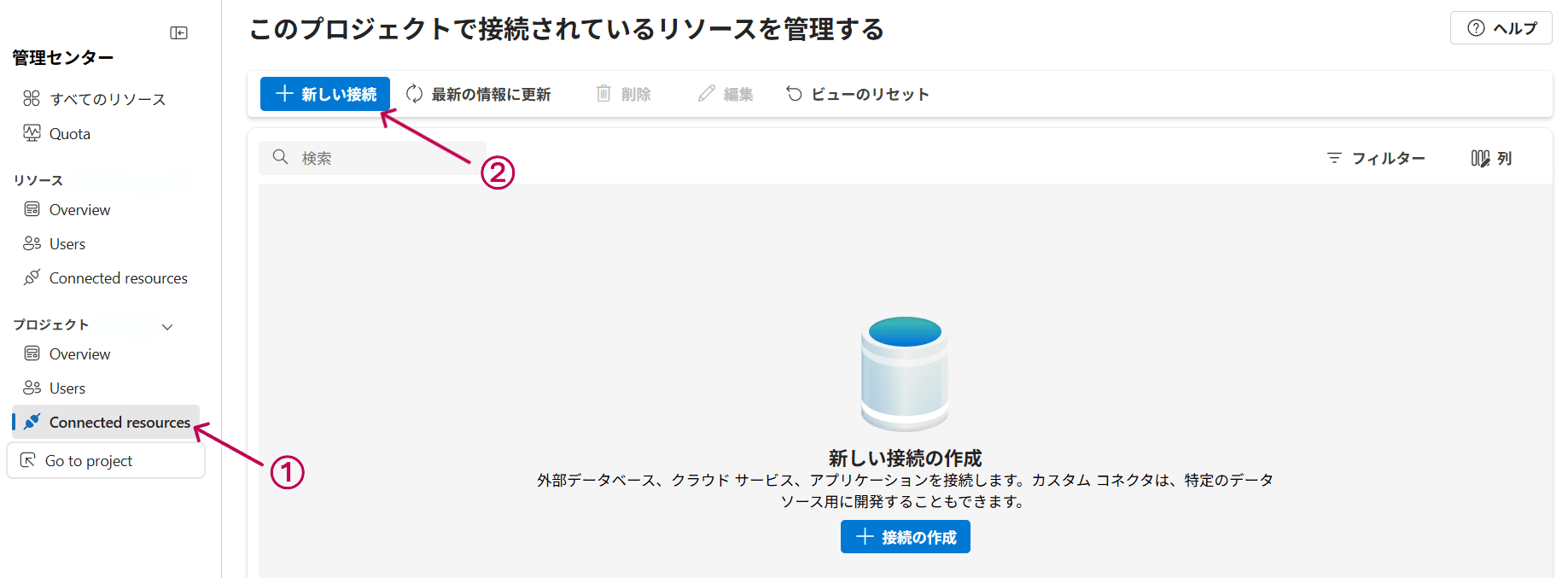
管理センターにアクセス
6. Grounding with Bing Searchツールの接続
「エージェントナレッジツール」から、「Grounding with Bing Search」を選択し、Bing Searchアカウントを使用してツールを接続します。
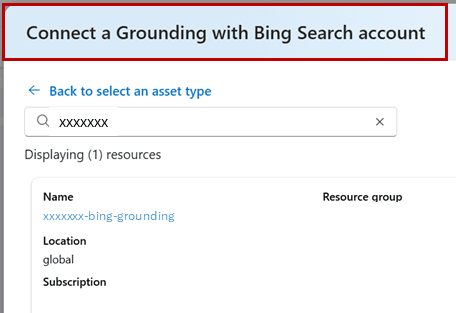
Grounding with Bing Searchツールの接続 (参考:Microsoft)
7. ライブラリのインストール
以下のコマンドを実行し、`azure-ai-projects`ライブラリをインストールします。
```
pip install --pre azure-ai-projects
```
8. エージェントの構築
Deep Researchツールを呼び出すエージェントを構築します。以下はPythonでのサンプルコードです。
デプロイしたモデルのエンドポイントといった環境変数を設定したうえで実行しましょう。
```Python
import os, time
from typing import Optional
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
from azure.ai.agents import AgentsClient
from azure.ai.agents.models import DeepResearchTool, MessageRole, ThreadMessage
# エージェントからの新しい応答を取得して表示
def fetch_and_print_new_agent_response(
thread_id: str,
agents_client: AgentsClient,
last_message_id: Optional[str] = None,
) -> Optional[str]:
# 投稿された最後のメッセージを取得
response = agents_client.messages.get_last_message_by_role(
thread_id=thread_id,
role=MessageRole.AGENT,
)
if not response or response.id == last_message_id:
return last_message_id
# エージェントの応答を表示
print("\nエージェントの応答:")
print("\n".join(t.text.value for t in response.text_messages))
# 引用URLを表示
for ann in response.url_citation_annotations:
print(f"引用URL: [{ann.url_citation.title}]({ann.url_citation.url})")
return response.id
# 調査結果の要約をマークダウンファイルとして作成
def create_research_summary(
message : ThreadMessage,
filepath: str = "research_summary.md"
) -> None:
if not message:
print("メッセージの内容が提供されていないため、調査要約を作成できません。")
return
with open(filepath, "w", encoding="utf-8") as fp:
text_summary = "\n\n".join([t.text.value.strip() for t in message.text_messages])
fp.write(text_summary)
# 引用URLが存在する場合、重複を除いて書き込む
if message.url_citation_annotations:
fp.write("\n\n## 参考文献\n")
seen_urls = set()
for ann in message.url_citation_annotations:
url = ann.url_citation.url
title = ann.url_citation.title or url
if url not in seen_urls:
fp.write(f"- [{title}]({url})\n")
seen_urls.add(url)
print(f"調査要約が'{filepath}'に書き込まれました。")
# クライアントを初期化
project_client = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
# Grounding with Bing SearchのIDを取得
conn_id = project_client.connections.get(name=os.environ["BING_RESOURCE_NAME"]).id
# Deep Researchツールを初期化
deep_research_tool = DeepResearchTool(
bing_grounding_connection_id=conn_id,
deep_research_model=os.environ["DEEP_RESEARCH_MODEL_DEPLOYMENT_NAME"],
)
# Deep Researchツールを使ってエージェントを実行
with project_client:
with project_client.agents as agents_client:
# Deep Researchツールがアタッチされた新しいエージェントを作成
agent = agents_client.create_agent(
model=os.environ["MODEL_DEPLOYMENT_NAME"],
name="my-agent",
instructions="",# エージェントへの指示
tools=deep_research_tool.definitions,
)
print(f"作成されたエージェントID: {agent.id}")
# 対話用のスレッドを作成
thread = agents_client.threads.create()
print(f"作成されたスレッドID: {thread.id}")
# スレッドにメッセージを作成
message = agents_client.messages.create(
thread_id=thread.id,
role="user",
content=(
""# Deep Researchツールに渡すメッセージの内容
),
)
print(f"作成されたメッセージID: {message.id}")
print(f"メッセージの処理を開始します...完了まで数分かかる場合があります。")
# 実行ステータスが'queued'または'in_progress'の間ポーリング
run = agents_client.runs.create(thread_id=thread.id, agent_id=agent.id)
last_message_id = None
while run.status in ("queued", "in_progress"):
time.sleep(1)
run = agents_client.runs.get(thread_id=thread.id, run_id=run.id)
# 実行中に新しいエージェントの応答を取得して表示
last_message_id = fetch_and_print_new_agent_response(
thread_id=thread.id,
agents_client=agents_client,
last_message_id=last_message_id,
)
print(f"実行ステータス: {run.status}")
print(f"実行が完了しました。ステータス: {run.status}, ID: {run.id}")
if run.status == "failed":
print(f"実行が失敗しました: {run.last_error}")
# 最終メッセージを取得し、調査要約を作成
final_message = agents_client.messages.get_last_message_by_role(
thread_id=thread.id, role=MessageRole.AGENT
)
if final_message:
create_research_summary(final_message)
```
上記の手順でDeep Researchツールを利用することが可能です。
非同期の実装サンプルや、`azure-ai-projects`ライブラリの詳細情報は、Deep Researchツールの公式ドキュメントに掲載されています。ぜひ併せてご覧ください。
Azure AI Foundry Agent ServiceのDeep Researchツールの使い方のコツ
Deep Researchツールを効果的に運用するためには、いくつかのコツがあります。このセクションでは、主な使い方のコツをご紹介します。
効果的なプロンプトを作成する
ツールの性能は、最初のプロンプトの質に大きく左右されます。曖昧な指示は、モデルの不要な推論を増やし、コストを増大させる原因となります。
「金融におけるAIについて教えて」のような広範な質問ではなく、「過去12ヶ月以内に発表された研究に基づき、米国の銀行セクターにおけるリスク管理のための生成AIの主要な応用事例を要約してください」のように、具体的で明確な指示を心がけましょう。
構造化された出力をプログラムで活用する
Deep Researchツールの出力は、引用や推論過程を含む構造化データです。これを単なるテキストとして扱うのではなく、プログラムで処理することで、より有効に活用できます。
例えば、抽出された引用URLを自動的にクロールして社内ナレッジベースに蓄積したり、情報の信頼性を検証するプロセスを構築するといった活用が期待できます。
長時間タスクには非同期処理を検討する
複雑な調査は完了までに数分以上かかる場合があります。アプリケーションに組み込む際は、同期的に結果を待ち続けるのではなく、非同期パターンを実装することが推奨されます。
調査の実行を開始した後、処理が完了したらWebhookで通知を送信するようにシステムを構成することで、アプリケーションはポーリングを続ける必要がなくなり、リソースを効率的に使用できます。
Azure AI Foundry Agent ServiceのDeep Researchツールの活用シーン
Deep Researchツールは、根拠に基づいたレポートを必要とするあらゆるシナリオで価値を発揮します。以下に、ビジネスシーンでの活用例を3つご紹介します。
競合他社の動向把握
Deep Researchツールを搭載したエージェントに、定期的にプレスリリース、業界ニュース、技術ブログなどをスキャンさせることで、競合企業の製品戦略、市場でのポジショニング、強み・弱みなどをまとめた、引用付きの統合レポートが自動生成されます。
これにより、アナリストはデータ収集ではなく、分析と戦略立案という、より価値の高い業務に集中できます。
法務・規制コンプライアンスへの対応
Deep Researchツールを搭載したエージェントが、週次や月次で各国の政府機関のウェブサイト、法律専門誌、関連ニュースを自動検索し、GDPRやCCPAなどの最新の改正案や判例の変更点を抽出します。
変更点の要約と根拠となる公式文書への直接リンクを含む監査可能なレポートが生成され、最新のコンプライアンスの遵守に寄与します。
金融デューデリジェンス
M&Aや投資を検討している企業の事業内容、財務状況、経営陣の経歴、市場での評判などの公開情報を、ニュース記事、業界レポートなど多岐にわたる情報源から分析します。
これにより、対象企業の全体像を把握するための包括的なプロファイルが迅速に作成され、アナリストの初期調査の負担を軽減します。
上記のように、Deep Researchツールは、手作業では膨大な時間と労力を要する調査タスクの自動化に適しています。
Azure AI Foundry Agent ServiceのDeep Researchツール利用時の注意点
Deep Researchツールは有用な機能ですが、運用にあたってはいくつかの注意点や制約事項を理解しておく必要があります。ここでは、特に注意すべきポイントをご説明します。
データプライバシーとコンプライアンス境界
Deep Researchツールの公式ドキュメントには、Grounding with Bing Searchツールを使用する際、検索クエリやリソースキーといったデータがAzureのコンプライアンス境界の外にあるBingのサービスに転送されると明記されています。
Bingのサービスは、中核となるAzure AI Foundry Agent Serviceと同じコンプライアンス認証基準を満たしているわけではありません。そのため、特に厳格なデータ主権やプライバシー要件を持つ組織は、このデータ転送が自社のポリシーに適合するかどうかを慎重に評価する必要があります。
コスト管理の重要性
Grounding with Bing Searchツールの利用コストは変動制であり、複雑なクエリを実行すると高額になる可能性があります。
適切な監視体制やプロンプト設計のガイドラインなしに利用すると、コストが予期せず膨れ上がるリスクがあります。組織として利用する際は、Azureポータルで予算アラートを設定するなど、初期段階からコスト管理の仕組みを導入することが推奨されます。
調査対象は公開Webデータのみ
Deep Researchツールは、その設計上、公開されているWeb上の情報のみを調査対象としています。現時点では、SharePointや社内データベースといった、企業内部の非公開データを検索する機能は備わっていません。
社内データとWeb上のデータを組み合わせた調査を行うには、Azure AI Searchなどの他のツールと連携する、より高度なマルチツールエージェントを構築する必要があります。
まとめ
本記事では、Deep Researchツールの基本的な役割や機能、利用手順、料金体系、活用シーン、注意点について詳しく解説しました。
Deep Researchツールは、Azure AI Foundry Agent Serviceの一部として、公開Webデータを活用した高度な調査を自動化するためのツールです。その多段階のワークフローにより、信頼性の高い構造化レポートを生成し、ビジネスの意思決定を支援します。
Deep Researchツールの効率的な運用を目指すためには、ツールの特性を理解し、適切な設定や運用体制を整えることが重要です。
本記事を参考に、Deep Researchツールを最大限に活用してください。
東京エレクトロンデバイスは、Azure導入支援からID・権限設計、セキュリティ対策支援までをワンストップでサポートしています。



